AI-Ready Data Blueprints — Bản dịch tiếng Việt
Tựa gốc: AI-Ready Data Blueprints — From Raw Data to AI-Driven Innovation Tác giả: Navnit Shukla, Kien Pham, Srikanth Sopirala và Harsha Tadiparthi Lời tựa (Foreword): Ehsan Hoque Nhà xuất bản: O'Reilly — Ấn bản thứ nhất, tháng 5/2026
Phần này gồm các trang đầu sách (front matter): trang bìa, thông tin bản quyền, lời tựa, lời nói đầu và lời cảm ơn.
Trang bìa
AI-Ready Data Blueprints
Từ dữ liệu thô đến đổi mới do AI dẫn dắt (From Raw Data to AI-Driven Innovation)
Navnit Shukla, Kien Pham, Srikanth Sopirala và Harsha Tadiparthi
Lời tựa của Ehsan Hoque
O'REILLY®
Thông tin bản quyền
AI-Ready Data Blueprints — của Navnit Shukla, Kien Pham, Srikanth Sopirala và Harsha Tadiparthi.
Bản quyền © 2026 thuộc về Navnit Kumar Shukla, AZ25 Lab, Harsha Tadiparthi và Srikanth Sopirala. Bảo lưu mọi quyền.
Xuất bản bởi O'Reilly Media, Inc., 141 Stony Circle, Suite 195, Santa Rosa, CA 95401.
Sách của O'Reilly có thể được mua phục vụ mục đích giáo dục, kinh doanh hoặc khuyến mãi bán hàng. Hầu hết các tựa sách cũng có ấn bản trực tuyến (https://oreilly.com). Để biết thêm thông tin, vui lòng liên hệ bộ phận bán hàng doanh nghiệp/tổ chức: 800-998-9938 hoặc corporate@oreilly.com.
- Biên tập viên mua bản quyền (Acquisitions Editor): Aaron Black
- Biên tập viên phát triển nội dung (Development Editor): Sara Hunter
- Biên tập viên sản xuất (Production Editor): Elizabeth Faerm
- Biên tập bản thảo (Copyeditor): Rachel Wheeler
- Hiệu đính (Proofreader): Kim Wimpsett
- Lập chỉ mục (Indexer): Judith McConville
- Thiết kế bìa (Cover Designer): Susan Brown
- Minh họa bìa (Cover Illustrator): Monica Kamsvaag
- Thiết kế nội dung (Interior Designer): David Futato
- Minh họa nội dung (Interior Illustrator): Kate Dullea
Tháng 5/2026: Ấn bản thứ nhất.
Lịch sử phiên bản của ấn bản thứ nhất
- 2026-05-06: Phát hành lần đầu.
Xem chi tiết phát hành tại https://oreilly.com/catalog/errata.csp?isbn-9798341631793.
Logo O'Reilly là thương hiệu đã đăng ký của O'Reilly Media, Inc. AI-Ready Data Blueprints, hình ảnh bìa và các yếu tố nhận diện liên quan là thương hiệu của O'Reilly Media, Inc.
Các quan điểm trình bày trong tác phẩm này là của các tác giả và không đại diện cho quan điểm của nhà xuất bản. Mặc dù nhà xuất bản và các tác giả đã nỗ lực với thiện chí nhằm bảo đảm thông tin và hướng dẫn trong tác phẩm là chính xác, nhà xuất bản và các tác giả không chịu trách nhiệm về các sai sót hoặc thiếu sót, bao gồm nhưng không giới hạn ở trách nhiệm đối với các thiệt hại phát sinh từ việc sử dụng hoặc dựa vào tác phẩm này. Việc sử dụng thông tin và hướng dẫn trong tác phẩm này là rủi ro do bạn tự chịu. Nếu bất kỳ đoạn mã mẫu hoặc công nghệ nào mà tác phẩm này chứa đựng hoặc mô tả thuộc phạm vi của giấy phép mã nguồn mở hoặc quyền sở hữu trí tuệ của bên khác, bạn có trách nhiệm bảo đảm việc sử dụng của mình tuân thủ các giấy phép và/hoặc quyền đó.
ISBN: 979-8-341-63179-3
[LSI]
Lời tựa (Foreword)
Tại phòng thí nghiệm của tôi ở Đại học Rochester, suốt hơn một thập kỷ, chúng tôi đã xây dựng các hệ thống AI biết lắng nghe giọng nói của bệnh nhân và quan sát cử động khuôn mặt của họ để phát hiện sớm dấu hiệu của bệnh Parkinson và chứng tự kỷ — thường là trước cả khi một bác sĩ lâm sàng kịp thăm khám. Những mô hình chúng tôi xây dựng rất tinh vi. Các thuật toán đều vững vàng. Nhưng bài toán khó nhất chưa bao giờ là mô hình. Đó là dữ liệu.
Chúng tôi học được bài học này theo cách mà hầu hết các nhà nghiên cứu đều trải qua: một cách đau đớn. Những hệ thống thuở ban đầu của chúng tôi hoạt động hoàn hảo trên các tập dữ liệu được tuyển chọn kỹ lưỡng, rồi sụp đổ khi ra thế giới thực — không phải vì mạng nơ-ron sai, mà vì dữ liệu nuôi chúng bị thiếu sót, không nhất quán, hoặc đã bị tước đi bối cảnh vốn mang lại ý nghĩa cho nó. Một đoạn ghi âm giọng nói mà thiếu siêu dữ liệu (metadata) về thời điểm dùng thuốc của bệnh nhân thì chỉ là tạp âm. Một biểu cảm khuôn mặt mà thiếu bối cảnh hội thoại thì, nhẹ nhất là mơ hồ, nặng nhất là gây hiểu lầm. Tín hiệu luôn ở đó — chỉ là dữ liệu chưa sẵn sàng để bộc lộ nó.
Trải nghiệm đó, lặp đi lặp lại qua các nghiên cứu lâm sàng, qua những lần triển khai AI y tế quy mô quốc gia ở Ả Rập Xê Út, và qua công việc tư vấn với Viện Hàn lâm Quốc gia (National Academies), đã cho tôi một niềm tin sâu sắc: những tổ chức dẫn đầu trong kỷ nguyên AI không phải là những tổ chức sở hữu các mô hình mạnh nhất. Đó là những tổ chức có dữ liệu được kiến trúc một cách có chủ đích nhất.
Đây chính xác là luận điểm mà Navnit, Kien, Srikanth và Harsha đưa ra trong AI-Ready Data Blueprints, và họ trình bày nó với một sự sáng rõ cùng chiều sâu thực tiễn hiếm thấy trong các tác phẩm kỹ thuật.
Điều khiến tôi ấn tượng nhất ở cuốn sách này là nó được viết dựa trên kinh nghiệm thực địa, và các ví dụ phản ánh công việc thực tế với khách hàng mà hầu hết tổ chức đều thường gặp. Các tác giả không né tránh sự thật khó chịu rằng gần 60% tổ chức vẫn chưa điều chỉnh chiến lược dữ liệu của mình cho AI tạo sinh (generative AI), ngay cả khi họ đổ nguồn lực vào các bản thử nghiệm khái niệm (proof of concept). Họ không vờ rằng việc chọn đúng mô hình nền tảng (foundation model) mới là phần khó. Thay vào đó, họ trực diện chỉ ra nút thắt thật sự: khâu chuẩn bị dữ liệu quan trọng gấp năm đến sáu lần so với việc lựa chọn mô hình. Từng tận mắt chứng kiến điều này — từ việc xây dựng các hệ thống AI y tế phục vụ hàng triệu người đến việc tư vấn cho các chính phủ về chiến lược AI quốc gia — tôi có thể khẳng định con số đó cảm thấy hoàn toàn đúng.
Hành trình của cuốn sách phản chiếu đúng hành trình mà mọi nhà thực hành AI nghiêm túc đều phải đi qua. Nó bắt đầu từ câu hỏi nền tảng: điều gì khiến AI tạo sinh khác biệt căn bản so với phân tích dữ liệu truyền thống và học máy — một sự khác biệt mà quá nhiều tổ chức vẫn còn xem nhẹ. Rồi nó xây dựng một cách có hệ thống xuyên suốt: khung làm việc cho dữ liệu sẵn sàng cho AI (AI-ready data), công việc tuy không hào nhoáng nhưng thiết yếu là xử lý và chuẩn bị dữ liệu (data wrangling), các thách thức về quản trị và bảo mật vốn trở nên sống còn ở quy mô doanh nghiệp, kiến trúc của các cơ sở tri thức (knowledge base) và cơ sở dữ liệu vector (vector database), và cuối cùng là sự khôn ngoan phải trả giá mới có được để đưa các ứng dụng AI vào trạng thái sẵn sàng vận hành (production-ready).
Tôi đặc biệt bị cuốn hút bởi các chương về quản trị dữ liệu và mức độ sẵn sàng cho vận hành. Trong công việc đảm nhiệm vai trò lãnh đạo AI cấp cao cho chính phủ Ả Rập Xê Út, tôi đã tận mắt thấy quản trị không phải là một ràng buộc kìm hãm đổi mới mà là điều kiện tiên quyết cho đổi mới. Khi bạn triển khai các hệ thống AI chạm tới việc chăm sóc sức khỏe của cả một quốc gia, thì những câu hỏi về chất lượng dữ liệu, bảo mật, tuân thủ và AI có trách nhiệm không phải là chuyện tính sau. Chúng là nền móng để gây dựng niềm tin. Các tác giả hiểu điều này một cách sâu sắc, và cách họ bàn về các nguyên tắc của AI có trách nhiệm (công bằng, minh bạch, trách nhiệm giải trình, quyền riêng tư, độ tin cậy và sự giám sát của con người) phản ánh một độ chín chỉ có được từ kinh nghiệm triển khai trong thế giới thực.
Điều cũng khiến tôi đồng cảm là tầm nhìn của cuốn sách về nơi chúng ta đang hướng tới. Sự tiến hóa từ những trợ lý AI đơn giản đến các tác nhân (agent) tự chủ đòi hỏi một mối quan hệ khác về căn bản với dữ liệu. Các tác nhân không chỉ truy xuất thông tin — chúng suy luận trên thông tin đó, hành động dựa trên nó, và học hỏi từ nó. Hạ tầng dữ liệu cần thiết để hỗ trợ mức độ tự chủ đó khác biệt về chất so với bất cứ thứ gì chúng ta từng xây dựng trước đây. Khung tư duy của các tác giả để hiểu sự tiến hóa này, cùng với hướng dẫn thực tiễn để chuẩn bị cho nó, vừa kịp thời vừa thiết yếu.
Tôi đã dành cả sự nghiệp của mình ở giao điểm giữa AI và phúc lợi con người, xây dựng những hệ thống khuếch đại năng lực con người thay vì thay thế họ. Các tác giả cũng chia sẻ định hướng này. Việc họ khẳng định rằng dữ liệu là một tài sản chiến lược xứng đáng được kiến trúc một cách có chủ đích không chỉ là một luận điểm kỹ thuật: đó là một tuyên ngôn về giá trị. Nó nói rằng chúng ta nợ những con người sẽ chịu tác động bởi các hệ thống AI của mình trách nhiệm phải làm đúng ngay từ nền móng.
Dù bạn là một lãnh đạo đang cố hiểu vì sao sáng kiến AI tạo sinh của mình bị đình trệ, một kiến trúc sư dữ liệu đang thiết kế lại các đường ống (pipeline) cho kỷ nguyên AI, hay một nhà thực hành đang xây dựng hệ thống RAG vận hành đầu tiên của mình, cuốn sách này sẽ đón bạn ở đúng nơi bạn đang đứng và đưa bạn đến nơi bạn cần đến. Bản thiết kế (blueprint) đang nằm trong tay bạn.
Giờ là lúc bắt tay vào xây dựng.
Ehsan Hoque, Tiến sĩ Giáo sư chính thức ngành khoa học máy tính, Đại học Rochester Lãnh đạo AI cấp cao, chính phủ Ả Rập Xê Út Giải thưởng Presidential Early Career Award cho các nhà khoa học và kỹ sư (PECASE) Nhà đổi mới dưới 35 tuổi của MIT Technology Review
Lời nói đầu (Preface)
Bạn đang cầm trên tay một cuốn sách ra đời từ một quan sát đơn giản: hầu hết các dự án AI thất bại không phải vì mô hình tồi, mà vì dữ liệu tồi.
Trong hai năm qua, chúng tôi đã làm việc sát cánh với các tổ chức thuộc mọi quy mô, trải khắp nhiều ngành, khi họ chạy đua áp dụng AI tạo sinh. Chúng tôi đã chứng kiến những đội ngũ tài năng xây dựng nên các nguyên mẫu (prototype) ấn tượng, rồi lại thấy chúng đình trệ trên con đường tiến tới vận hành thực tế. Khuôn mẫu luôn giống nhau. Mô hình chạy tốt. Câu lệnh (prompt) thì khéo léo. Nhưng dữ liệu bên dưới? Nó chưa sẵn sàng.
Chính khuôn mẫu đó là động lực khiến chúng tôi viết cuốn sách này.
Khi ChatGPT ra mắt vào tháng 11/2022 và đạt 100 triệu người dùng chỉ trong 60 ngày, nó đã châm ngòi cho một làn sóng phấn khích lẫn hoảng loạn khắp thế giới doanh nghiệp. Bỗng nhiên, mọi phòng họp ban lãnh đạo đều xôn xao những thuật ngữ như "RAG", "cơ sở dữ liệu vector", và "AI tác nhân (agentic AI)". Các công ty lập ra hàng tá bản thử nghiệm khái niệm. Nhưng như một nghiên cứu gần đây của AWS chỉ ra, dù phần lớn các lãnh đạo dữ liệu đều thừa nhận tầm quan trọng của việc chuẩn bị dữ liệu cho các tình huống sử dụng AI tạo sinh, gần 60% cho biết họ vẫn chưa thực hiện những thay đổi cần thiết đối với chiến lược dữ liệu của công ty. Khoảng cách giữa việc biết dữ liệu quan trọng và việc thực sự làm cho nó vận hành được chính là điều cuốn sách này bàn tới.
Chúng tôi viết AI-Ready Data Blueprints cho những người ở tuyến đầu: các kiến trúc sư dữ liệu đang thiết kế lại đường ống cho khối lượng công việc AI, các kỹ sư đang vật lộn với chiến lược chia nhỏ dữ liệu (chunking), các nhà lãnh đạo đang cố tìm hiểu vì sao chatbot AI của họ cứ liên tục "bịa đặt" (hallucinate), và các đội ngũ quản trị đang băn khoăn làm sao giữ cho việc triển khai vừa an toàn vừa tuân thủ. Dù bạn là một lãnh đạo đang cố hiểu vì sao sáng kiến AI tạo sinh của mình bị đình trệ, hay một nhà thực hành trực tiếp xây dựng hệ thống tạo sinh tăng cường truy xuất (retrieval-augmented generation — RAG) vận hành đầu tiên, chúng tôi muốn trao cho bạn một thứ gì đó thực tiễn — không lý thuyết suông, không chạy theo cường điệu, mà bám rễ vào những gì thực sự hiệu quả.
Bạn sẽ tìm thấy gì bên trong
Cuốn sách này đi theo hành trình mà dữ liệu của bạn phải trải qua — từ thô ráp, lộn xộn và rời rạc đến sẵn sàng cho AI, được quản trị và đạt chuẩn vận hành.
Chúng tôi bắt đầu bằng việc trình bày vì sao AI tạo sinh đòi hỏi một cách tiếp cận dữ liệu khác biệt về căn bản so với phân tích truyền thống hay học máy. Đây không còn chỉ là chuyện dọn dẹp các bảng dữ liệu nữa. Đây là chuyện gìn giữ ý nghĩa, mô hình hóa các mối quan hệ, và xây dựng những hệ thống biết suy luận chứ không chỉ truy xuất. Từ đó, chúng tôi dẫn bạn đi qua một khung làm việc toàn diện cho dữ liệu sẵn sàng cho AI, bao quát mọi thứ — từ việc nắm bắt logic nghiệp vụ và bối cảnh, đến việc bảo đảm chất lượng và tính nhất quán, cho tới việc quản lý các thách thức về bảo mật và tuân thủ phát sinh khi đưa AI vào thế giới thực. Chúng tôi đi sâu vào các chi tiết kỹ thuật của cơ sở tri thức, cơ sở dữ liệu vector, các chiến lược chia nhỏ dữ liệu và tối ưu hóa truy xuất, bởi vì nghiên cứu đã chỉ rõ: cách bạn chuẩn bị dữ liệu quan trọng gấp năm đến sáu lần so với việc bạn chọn mô hình nào.
Chúng tôi cũng đối diện với những thách thức mà bạn sẽ gặp sau khi đã phát triển được một nguyên mẫu hoạt động, đào sâu vào các chủ đề như mức độ sẵn sàng cho vận hành, suy luận tự động (automated reasoning), các lớp siêu dữ liệu ngữ nghĩa thông minh (intelligent semantic metadata layers), và bối cảnh đang định hình của các nền tảng AI tác nhân. Đây không phải là những khái niệm trừu tượng. Những hiểu biết chúng tôi cung cấp đến từ các lần triển khai thực tế, bao gồm cả những tổ chức quản lý hàng triệu tỷ tệp tin tích lũy qua nhiều thập kỷ.
Các bản thiết kế (blueprint), sơ đồ kiến trúc và mã mẫu được cung cấp qua trang web đồng hành của cuốn sách và kho lưu trữ GitHub.
Cuốn sách này dành cho ai
Nếu bạn từng nhìn một bản demo AI tạo sinh và nghĩ: "Tuyệt thật — giờ làm sao để nó chạy được với dữ liệu của chúng ta?", thì cuốn sách này dành cho bạn. Chúng tôi viết nó cho một độc giả rộng: các lãnh đạo cấp cao, kiến trúc sư dữ liệu, kỹ sư, nhà thực hành AI, và cả những chuyên gia nghiệp vụ nắm giữ tri thức kinh doanh — thứ làm cho AI thực sự hữu dụng. Bạn không cần phải là một nhà nghiên cứu học máy mới rút ra được giá trị từ những trang này. Bạn chỉ cần quan tâm đến việc làm AI cho đúng.
Ý tưởng về cuốn sách nảy sinh sau khi bốn chúng tôi ngồi lại với nhau để bàn về việc xây dựng nền tảng dữ liệu cho AI tạo sinh, trong một tập của podcast mà Navnit vẫn dẫn trên kênh YouTube của mình. Tất cả chúng tôi đều xuất thân từ thế giới dữ liệu và AI tại AWS. Gộp lại, chúng tôi đã dành hàng chục năm giúp các tổ chức điều hướng qua thực tế lộn xộn của dữ liệu doanh nghiệp. Điều gắn kết chúng tôi là một niềm tin chung: dữ liệu của bạn là một tài sản chiến lược xứng đáng được kiến trúc một cách có chủ đích. Làm đúng điều này, mọi thứ khác sẽ theo sau. Làm sai, thì không một mức độ tinh vi nào của mô hình có thể cứu được bạn.
Chúng tôi đã cố viết ra cuốn sách mà chính mình từng ước có khi mọi chuyện mới bắt đầu — một cuốn sách trung thực về các thách thức, cụ thể về các giải pháp, và đủ thực tiễn để dùng được ngay trong khối lượng công việc vận hành của bạn.
Bản thiết kế đang nằm trong tay bạn. Giờ là lúc bắt tay vào xây dựng.
Các quy ước được dùng trong cuốn sách
Cuốn sách sử dụng các quy ước về kiểu chữ sau:
Chữ nghiêng (Italic) : Biểu thị thuật ngữ mới, URL, địa chỉ email, tên tệp và phần mở rộng tệp.
Chữ rộng đều (Constant width)
: Dùng cho các đoạn mã chương trình, cũng như trong các đoạn văn để chỉ các thành phần của chương trình như tên biến hoặc tên hàm, cơ sở dữ liệu, kiểu dữ liệu, biến môi trường, câu lệnh và từ khóa.
GHI CHÚ (NOTE): Yếu tố này biểu thị một ghi chú chung.
CẢNH BÁO (WARNING): Yếu tố này biểu thị một cảnh báo hoặc lưu ý cần thận trọng.
Sử dụng các ví dụ mã
Tài liệu bổ sung (ví dụ mã, bài tập, v.v.) có thể tải xuống tại https://oreil.ly/code-samples.
Nếu bạn có câu hỏi kỹ thuật hoặc gặp vấn đề khi sử dụng các ví dụ mã, vui lòng gửi email đến support@oreilly.com.
Cuốn sách này có mặt để giúp bạn hoàn thành công việc. Nhìn chung, nếu một ví dụ mã được cung cấp kèm theo sách, bạn có thể dùng nó trong các chương trình và tài liệu của mình. Bạn không cần liên hệ xin phép chúng tôi trừ khi bạn tái tạo một phần đáng kể của đoạn mã. Ví dụ, viết một chương trình sử dụng vài đoạn mã từ cuốn sách này thì không cần xin phép. Việc bán hoặc phân phối các ví dụ từ sách của O'Reilly thì cần xin phép. Trả lời một câu hỏi bằng cách trích dẫn cuốn sách này và dẫn lại ví dụ mã thì không cần xin phép. Đưa một lượng đáng kể mã ví dụ từ cuốn sách này vào tài liệu sản phẩm của bạn thì cần xin phép.
Chúng tôi trân trọng, nhưng nhìn chung không bắt buộc, việc ghi nguồn. Một dòng ghi nguồn thường gồm tựa đề, tác giả, nhà xuất bản và ISBN. Ví dụ: "AI-Ready Data Blueprints của Navnit Shukla, Kien Pham, Srikanth Sopirala và Harsha Tadiparthi (O'Reilly). Bản quyền 2026 Navnit Kumar Shukla, AZ25 Lab, Harsha Tadiparthi và Srikanth Sopirala, 979-8-341-63179-3."
Nếu bạn cho rằng việc sử dụng các ví dụ mã của mình nằm ngoài phạm vi sử dụng hợp lý (fair use) hoặc phạm vi cho phép nêu trên, xin cứ liên hệ với chúng tôi tại permissions@oreilly.com.
Học trực tuyến cùng O'Reilly
GHI CHÚ (NOTE): Trong hơn 40 năm, O'Reilly Media đã cung cấp đào tạo, tri thức và hiểu biết sâu sắc về công nghệ và kinh doanh để giúp các công ty thành công.
Mạng lưới độc đáo gồm các chuyên gia và nhà đổi mới của chúng tôi chia sẻ kiến thức và chuyên môn của họ thông qua sách, bài viết và nền tảng học trực tuyến. Nền tảng học trực tuyến của O'Reilly cho bạn quyền truy cập theo nhu cầu vào các khóa đào tạo trực tiếp, lộ trình học chuyên sâu, môi trường lập trình tương tác, cùng một kho đồ sộ văn bản và video từ O'Reilly và hơn 200 nhà xuất bản khác. Để biết thêm thông tin, vui lòng truy cập https://oreilly.com.
Cách liên hệ với chúng tôi
Vui lòng gửi các nhận xét và câu hỏi liên quan đến cuốn sách này đến nhà xuất bản:
O'Reilly Media, Inc. 141 Stony Circle, Suite 195 Santa Rosa, CA 95401 800-889-8969 (tại Hoa Kỳ hoặc Canada) 707-827-7019 (quốc tế hoặc địa phương) 707-829-0104 (fax) support@oreilly.com https://oreilly.com/about/contact.html
Chúng tôi có một trang web cho cuốn sách này, nơi liệt kê các đính chính (errata) và mọi thông tin bổ sung. Bạn có thể truy cập trang này tại https://oreil.ly/ai-ready-data-blueprints.
Để cập nhật tin tức và thông tin về sách và khóa học của chúng tôi, vui lòng truy cập https://oreilly.com.
Tìm chúng tôi trên LinkedIn: https://linkedin.com/company/oreilly-media. Theo dõi chúng tôi trên YouTube: https://youtube.com/oreillymedia.
Lời cảm ơn (Acknowledgments)
Các tác giả xin bày tỏ lòng biết ơn sâu sắc nhất đến những người sau đây vì sự hỗ trợ của họ trong suốt quá trình phát triển cuốn sách này:
Navnit Shukla
Trước hết và trên hết, cuốn sách này là một món quà dành cho gia đình tôi. Cuốn sách đầu tay của tôi, Data Wrangling on AWS, được viết cho con trai cả của tôi, Anav. Thật vui khi được dành tặng tác phẩm này cho con trai thứ hai của tôi, Ayansh, hiện đã 18 tháng tuổi. Gửi vợ tôi, Anchal, và các con trai Anav và Ayansh: cảm ơn vì sự ủng hộ không lay chuyển của mọi người, và vì đã là ánh sáng dẫn đường cho tôi qua biết bao đêm khuya và sáng sớm mà dự án này đòi hỏi.
Tôi xin gửi lời cảm ơn đặc biệt đến Sara Hunter vì sự dẫn dắt và hỗ trợ tuyệt vời của cô ấy trong suốt quá trình này; những góc nhìn của cô là yếu tố then chốt đưa dự án này thành hình. Tôi cũng muốn cảm ơn phần còn lại của đội ngũ O'Reilly — Aaron Black, Elizabeth Faerm, Rachel Wheeler và Kim Wimpsett — vì chuyên môn biên tập của họ.
Được làm việc cùng các đồng tác giả Kien, Srikanth và Harsha là một vinh dự. Tôi nợ họ lời cảm ơn đặc biệt vì vô số giờ tranh luận và cam kết chung của chúng tôi đối với sự xuất sắc trong kiến trúc dữ liệu. Cuối cùng, tôi xin cảm ơn Long Tran, Thong Do, Robert Fisher, John Giles và nhiều người phản biện khác, những phản hồi thẳng thắn của họ đã giữ cho nội dung kỹ thuật luôn thực tế và trung thực.
Kien Pham
Tôi vô cùng biết ơn đội ngũ O'Reilly — Aaron Black, Sara Hunter, Elizabeth Faerm, Rachel Wheeler và Kim Wimpsett — những người mà sự dẫn dắt biên tập và lòng kiên nhẫn đã định hình cuốn sách này thành một thứ tốt hơn rất nhiều so với điểm xuất phát ban đầu của chúng tôi.
Tôi xin gửi lời cảm ơn đặc biệt đến các đồng tác giả — Navnit, Srikanth và Harsha — vì vô số giờ thảo luận, tranh luận và niềm tin chung rằng dữ liệu doanh nghiệp xứng đáng được kiến trúc một cách có chủ đích. Tôi cũng muốn cảm ơn Long Tran, Thong Do, Robert Fisher, John Giles và nhiều người khác vì những lần phản biện kỹ lưỡng và phản hồi thẳng thắn, giúp giữ cho nội dung kỹ thuật trung thực và bám sát thực tiễn. Cuối cùng và quan trọng nhất, tôi cảm ơn gia đình vì sự ủng hộ và thấu hiểu không lay chuyển trong suốt biết bao sáng sớm và đêm khuya mà dự án này đòi hỏi.
Srikanth Sopirala
Tôi biết ơn rất nhiều người đã góp phần đưa cuốn sách này thành hình. Ý tưởng đầu tiên xuất hiện trong một cuộc trò chuyện podcast, nơi một cuộc thảo luận đơn giản đã thắp lên một tầm nhìn lớn hơn về việc ghi lại những hiểu biết này dưới một hình thức bền vững hơn. Navnit đã lấy tia lửa ban đầu đó và biến nó thành hiện thực, mang đến sự khích lệ, cấu trúc và trách nhiệm cần thiết để biến những ý tưởng rời rạc thành một cuốn sách hoàn chỉnh.
Cảm ơn gia đình và bạn bè vì sự động viên không ngừng, cảm ơn biên tập viên và đội ngũ xuất bản của tôi vì chuyên môn và sự dẫn dắt, và cảm ơn các đồng nghiệp cùng độc giả — những câu hỏi, phê bình và trò chuyện của họ đã định hình nên những ý tưởng này. Những đóng góp của các bạn, cả thấy được lẫn không thấy được, đều được trân trọng sâu sắc.
Harsha Tadiparthi
Gửi vợ tôi và cô con gái nhỏ —
Các con là trái tim của tất cả những gì anh/bố làm. Cuốn sách này được viết trong những giờ "đánh cắp" được, len lỏi giữa những câu chuyện kể trước giờ đi ngủ và những tòa tháp xếp hình, và nó sẽ không tồn tại nếu thiếu sự ủng hộ không lay chuyển của em/con. Gửi vợ anh, cảm ơn em đã giữ cho thế giới của chúng ta vẹn nguyên mỗi khi anh biến mất vào những trang viết này. Gửi cô con gái ba tuổi của bố, người chẳng hề biết bố đã gõ những gì, nhưng tiếng cười của con đã khiến mỗi con chữ đều đáng giá.
Cuốn sách này dành cho cả hai người.
Chương 1. Giới thiệu về Nền tảng Dữ liệu Sẵn sàng cho AI
Trong chương này, chúng ta sẽ xem xét sự tăng trưởng nhanh chóng của các công nghệ AI tạo sinh (generative AI — GenAI) và giới thiệu hạ tầng dữ liệu thiết yếu cần có để triển khai chúng thành công. Việc áp dụng các mô hình nền tảng (foundation model) với tốc độ chưa từng có đã vượt xa mức độ sẵn sàng về dữ liệu của các tổ chức, tạo ra một khoảng cách đáng kể giữa giai đoạn thử nghiệm và giai đoạn triển khai vận hành. Chúng ta sẽ tìm hiểu khoảng cách này biểu hiện trong thực tế ra sao: theo nghiên cứu gần đây của McKinsey, dù 79% tổ chức thường xuyên sử dụng GenAI trong ít nhất một chức năng nghiệp vụ, chỉ 7% đã mở rộng hoàn toàn việc dùng AI ra môi trường vận hành. Đến nay đã là một sự thật quá rõ ràng rằng nguyên nhân chính của thất bại không nằm ở việc chọn mô hình — mà ở khâu chuẩn bị dữ liệu chưa đầy đủ. Các kiến trúc dữ liệu truyền thống vốn được tối ưu cho phân tích và học máy đơn giản là không thể hỗ trợ khả năng hiểu ngữ nghĩa (semantic understanding), bối cảnh thời gian thực (real-time context) và suy luận liên miền (cross-domain reasoning) mà các ứng dụng GenAI đòi hỏi.
Khi GenAI tiến hóa từ những trợ lý đơn giản thành các tác nhân (agent) tự chủ, yêu cầu đặt lên hạ tầng dữ liệu ngày càng phức tạp. Mỗi giai đoạn tiến hóa — từ trợ lý AI cơ bản, đến trợ lý đồng hành (copilot), đến tác nhân dựa trên truy xuất tăng cường (retrieval-augmented generation — RAG), rồi đến AI tác nhân (agentic AI) — đều đặt ra những yêu cầu khác biệt về căn bản đối với cách dữ liệu được cấu trúc, truy cập và quản trị. Chương này nhận diện năm mẫu kiến trúc (architectural pattern) thường xuyên xuất hiện ở các tổ chức vượt qua thành công khoảng cách tiến tới vận hành: đồ thị tri thức (knowledge graph) cho trí tuệ giàu bối cảnh, kiến trúc hướng sự kiện (event-driven architecture) cho AI thời gian thực, nền tảng lakehouse cho dữ liệu hợp nhất, tìm kiếm ngữ nghĩa (semantic search) cho truy xuất dựa trên ý nghĩa, và các thuộc tính sẵn sàng cho tác nhân (agent-ready properties) cho việc truy cập tự chủ. Thông qua các ví dụ thực tế — bao gồm hành trình tiến hóa của một nhà bán lẻ toàn cầu từ các mô hình đa chiều (dimensional model) truyền thống — chúng tôi sẽ minh họa cách các mẫu này phối hợp với nhau để tạo nên thành công khi đưa vào vận hành.
Giới thiệu và bối cảnh thị trường
Ngày 30 tháng 11 năm 2022, OpenAI ra mắt ChatGPT 3.5 dưới dạng một "bản xem trước nghiên cứu" (research preview), với mục tiêu thu thập phản hồi và hiểu rõ các khả năng cũng như giới hạn của nó.
Tuy nhiên, lần ra mắt này đã gặp một làn sóng quan tâm bùng nổ, và mô hình mới nhanh chóng trở thành một hiện tượng lan truyền, giải phóng một sức mạnh công nghệ sẽ nhanh chóng định hình lại thế giới theo những cách mà chúng ta chỉ mới bắt đầu hiểu được. Chỉ trong hai tháng, ChatGPT đã thu hút hơn 100 triệu người dùng, trở thành ứng dụng phần mềm tiêu dùng tăng trưởng nhanh nhất trong lịch sử. Chỉ trong 60 ngày, nó đạt được lượng người dùng mà Instagram phải mất hai năm rưỡi và TikTok mất chín tháng mới gây dựng được.
Khác với những bước tiến công nghệ trước đây như động cơ đốt trong vào thập niên 1860, internet vào thập niên 1990, điện thoại thông minh vào năm 2007, và điện toán đám mây vào đầu thập niên 2010 — vốn được áp dụng một cách dần dần — tác động của AI tạo sinh được phổ cập gần như tức thì.
GenAI đã đặt khả năng sáng tạo nội dung mạnh mẽ vào tay tất cả mọi người — thường chỉ cần một câu lệnh bằng ngôn ngữ tự nhiên đơn giản hoặc thậm chí một mệnh lệnh bằng giọng nói. Giờ đây, bất kỳ ai cũng có thể tạo ra nội dung trong lĩnh vực mình quan tâm hoặc có chuyên môn, dù là tạo hình ảnh, viết kịch bản, sản xuất video hay lập trình. Khả năng tiếp cận mới mẻ này đã cách mạng hóa năng suất, trao quyền cho từng cá nhân — bất kể trình độ kỹ thuật — để tạo ra mọi loại nội dung một cách dễ dàng.
Người lao động tri thức (knowledge worker) ở mọi ngành — bao gồm lập trình viên, người sáng tạo nội dung, chuyên viên phân tích, nhà nghiên cứu, tư vấn viên và các chuyên gia khác chủ yếu làm việc với thông tin — đã trải nghiệm một sự tăng tốc đáng kể trong quy trình làm việc của mình, với những tác vụ từng tốn nhiều ngày nay được hoàn thành chỉ trong vài giờ hoặc thậm chí vài phút. Việc tích hợp GenAI một cách liền mạch thông qua các giao diện ngôn ngữ tự nhiên trực quan — vốn (khác với các phần mềm doanh nghiệp trước đây đòi hỏi quá trình làm quen kéo dài) không cần đào tạo chuyên biệt — đã thúc đẩy một làn sóng áp dụng chưa từng có trên cả mặt trận tiêu dùng lẫn doanh nghiệp.
Chứng kiến tiềm năng biến đổi của GenAI, các tổ chức nhanh chóng bước vào cái mà giới phân tích ngành gọi là chế độ hoảng loạn GenAI (GenAI panic mode) — một cuộc đua triển khai năng lực AI tạo sinh được thúc đẩy bởi áp lực cạnh tranh nhiều hơn là bởi hoạch định chiến lược. Các lãnh đạo cấp cao (C-suite) ở mọi lĩnh vực yêu cầu triển khai ngay các sáng kiến AI tạo sinh, thúc ép đội ngũ của họ tung ra các bản thử nghiệm khái niệm chỉ ít lâu sau màn ra mắt của ChatGPT vào tháng 11/2022.
Một phân tích năm 2024 của Arize AI dựa trên dữ liệu hồ sơ nộp lên Ủy ban Chứng khoán và Giao dịch Hoa Kỳ (SEC) cho thấy 64,6% các công ty trong danh sách Fortune 500 đã nhắc đến AI trong báo cáo thường niên gần nhất của họ — tăng 250,1% so với năm 2022. Hơn một phần năm số công ty nhắc đến cụ thể AI tạo sinh, và hơn một nửa (281 công ty) coi nó là một yếu tố rủi ro, so với chỉ 49 công ty vào năm 2022. Hình 1-1 trực quan hóa sự tăng trưởng nhanh chóng này về mức độ áp dụng và nhận thức.
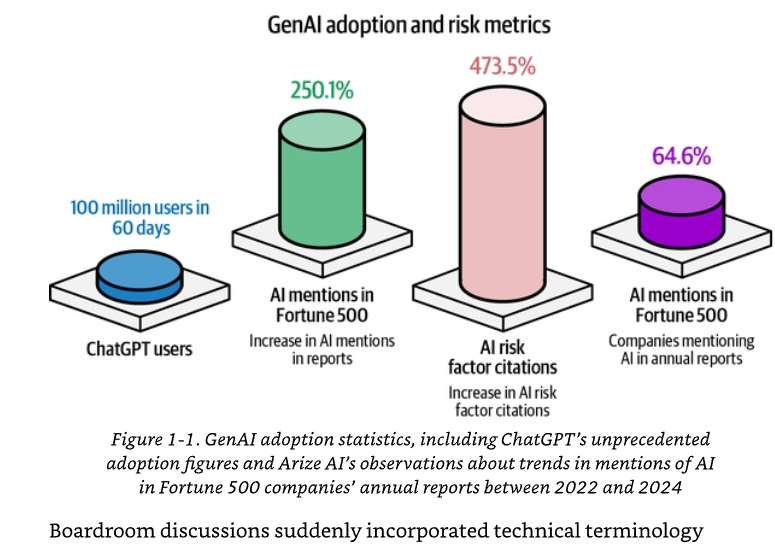
Chú thích Hình 1-1. Thống kê mức độ áp dụng GenAI, bao gồm các con số áp dụng chưa từng có của ChatGPT và các quan sát của Arize AI về xu hướng nhắc đến AI trong báo cáo thường niên của các công ty Fortune 500 giai đoạn 2022–2024. Các chỉ số nổi bật: 100 triệu người dùng trong 60 ngày; tăng 250,1% số lần nhắc đến AI trong báo cáo; tăng 473,5% số lần viện dẫn AI như một yếu tố rủi ro; 64,6% công ty Fortune 500 nhắc đến AI trong báo cáo thường niên.
[Ghi chú biên tập: Ảnh hình hiện được lưu trên Google Drive (ảnh chụp nguyên trang chứa Hình 1-1). Xem tại: https://drive.google.com/file/d/13RGDWFawDeXKeB3U2NbqG3CZp2SJJFMD/view]
Các cuộc thảo luận trong phòng họp ban lãnh đạo bỗng nhiên bắt đầu sử dụng những thuật ngữ kỹ thuật trước đây vốn chỉ giới hạn trong các bài báo nghiên cứu AI. Những thuật ngữ như "mô hình nền tảng (foundation model)", "cơ sở tri thức (knowledge base)", "kỹ thuật câu lệnh (prompt engineering)", "kiến trúc RAG", "cơ sở dữ liệu vector (vector database)", "tác nhân (agent)", "bịa đặt (confabulation, hay còn gọi là hallucination)", và "AI tác nhân (agentic AI)" gần như chỉ sau một đêm đã trở thành một phần vốn từ vựng của giới điều hành.
Sự hào hứng này của doanh nghiệp (hay nỗi sợ bị bỏ lại phía sau — FOMO, fear of missing out) càng tăng cao khi nhiều mô hình nền tảng khác lần lượt gia nhập thị trường với tốc độ chóng mặt. Chỉ trong sáu tháng kể từ khi ChatGPT ra mắt, một loạt đối thủ cạnh tranh đã tung ra sản phẩm của riêng mình, trong đó có (chỉ nêu một vài cái tên):
- Claude của Anthropic
- Bard của Google
- Llama của Meta
- Titan và Bedrock của Amazon
- Tongyi Qianwen của Alibaba
- Các mô hình Diffusion của Stability.ai
Sự bùng nổ về số lượng mô hình càng đổ thêm dầu vào tính cấp bách cạnh tranh trong việc áp dụng các công nghệ AI tạo sinh, với việc khách hàng chủ động tìm kiếm sự tư vấn về các lựa chọn sẵn có nhằm đẩy nhanh các bản thử nghiệm khái niệm của họ — và việc người tiêu dùng đón nhận đã chuyển hóa thành mức độ triển khai chưa từng có ở quy mô doanh nghiệp.
JPMorgan Chase đã mở rộng AI tạo sinh tới 200.000 nhân viên trên toàn bộ hoạt động toàn cầu của mình, tạo nên một trong những lần triển khai AI quy mô doanh nghiệp lớn nhất trong lịch sử ngành dịch vụ tài chính. Tương tự, Siemens đã tích hợp Amazon Bedrock vào nền tảng Mendix của mình, nay phục vụ hơn 50 triệu người dùng trên hơn 200.000 ứng dụng. Vận tốc phát triển cũng đáng kinh ngạc không kém: BT Group đã triển khai Amazon CodeWhisperer (nay được tích hợp vào Q Developer) cho 1.200 kỹ sư, tự động hóa 12% công việc của họ và sinh ra hơn 100.000 dòng mã chỉ trong bốn tháng.
Tuy vậy, ẩn bên dưới cơn sốt áp dụng này là một thách thức cốt yếu: hầu hết các tổ chức đang nhận ra rằng hạ tầng dữ liệu hiện có của họ không thể hỗ trợ các ứng dụng GenAI ở mức vận hành. Trong khi việc thử nghiệm diễn ra rộng khắp, việc mở rộng tới mức vận hành lại phơi bày những lỗ hổng căn bản trong cách dữ liệu doanh nghiệp được cấu trúc, truy cập và quản trị.
Để hiểu vì sao các kiến trúc dữ liệu truyền thống thất bại với GenAI, trước hết chúng ta phải xem xét điều gì khiến AI tạo sinh khác biệt về căn bản so với các phương pháp AI trước đây. Chính những khác biệt kỹ thuật này trực tiếp dẫn đến các thách thức hạ tầng mà các tổ chức phải đối mặt khi chuyển từ thử nghiệm sang vận hành.
Điều gì khiến AI tạo sinh khác biệt
AI tạo sinh đánh dấu một sự dịch chuyển căn bản trong cách các hệ thống AI được xây dựng và những gì chúng có thể làm. Các hệ thống AI truyền thống thường tập trung vào phân loại (classification), dự đoán (prediction) hoặc gợi ý (recommendation) dựa trên đầu vào có cấu trúc. Chúng dựa vào các mô hình hẹp, chuyên biệt theo tác vụ, đòi hỏi các tập dữ liệu đã gán nhãn hoặc các tín hiệu củng cố (reinforcement signal) để cải thiện theo thời gian. Ngược lại, các mô hình tạo sinh — đặc biệt là các mô hình nền tảng cỡ lớn — có khả năng tạo ra nội dung hoàn toàn mới, bao gồm văn bản, hình ảnh, âm nhạc, video và cả mã nguồn.
Điều khiến các mô hình nền tảng mang tính cách mạng không chỉ là quy mô hay sự đa dạng đầu ra của chúng, mà là phương pháp học của chúng (xem Hình 1-2). Thay vì chủ yếu phụ thuộc vào dữ liệu do con người gán nhãn (như trong học có giám sát — supervised learning) hay các vòng lặp thử-và-sai dựa trên phần thưởng (như trong học tăng cường — reinforcement learning), các mô hình này sử dụng học tự giám sát (self-supervised learning) — một phương pháp trong đó mô hình tự dạy chính mình hiểu và tạo ra ngôn ngữ, hình ảnh hoặc mã bằng cách dự đoán các thành phần bị che hoặc còn thiếu bên trong dữ liệu thô, chưa gán nhãn.
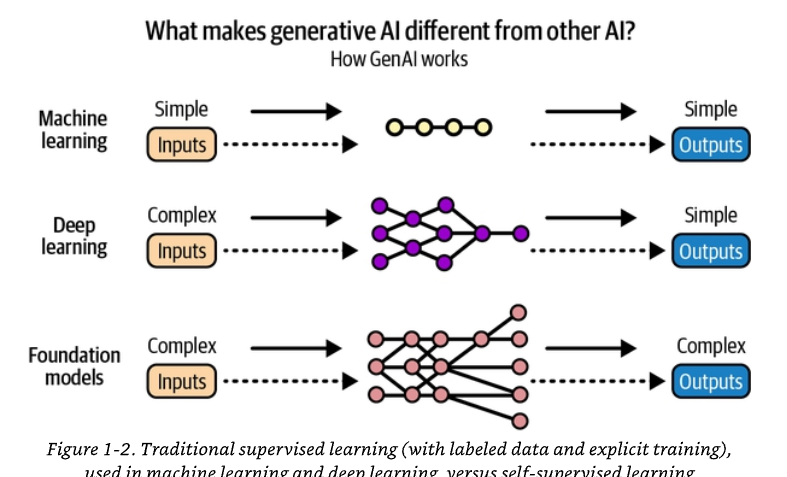
Chú thích Hình 1-2. Học có giám sát truyền thống (với dữ liệu đã gán nhãn và huấn luyện tường minh), được dùng trong học máy (machine learning) và học sâu (deep learning), đối lập với học tự giám sát. Sơ đồ minh họa: học máy nhận đầu vào đơn giản và cho đầu ra đơn giản; học sâu nhận đầu vào phức tạp và cho đầu ra đơn giản; mô hình nền tảng nhận đầu vào phức tạp và cho đầu ra phức tạp.
[Ghi chú: Hình đã được cắt riêng vùng hình (lưu cục bộ trong assets/); trang nguồn đầy đủ trên Google Drive: https://drive.google.com/file/d/10V8j2AbZMJUy16m8BhiS5I4MaMaN9s5g/view]
Quá trình này phản chiếu cách con người học — bằng cách quan sát, suy luận và hình thành các biểu diễn nội tại về thế giới mà không phải lúc nào cũng cần đến chỉ dẫn tường minh. Ví dụ, khi bạn dạy đứa con mới biết đi của mình về một con chó, một con mèo, hay bất kỳ con vật nào khác, chúng không chỉ học về riêng loài vật cụ thể đó. Chẳng bao lâu, chúng bắt đầu phân biệt giữa các loại động vật khác nhau, và cuối cùng, chúng bắt đầu phân biệt giữa các giống khác nhau trong từng nhóm.
Kiến trúc Transformer: Nền móng kỹ thuật của GenAI
Ở trung tâm của AI tạo sinh hiện đại là kiến trúc Transformer — một bước đột phá của học sâu đã cách mạng hóa cách các hệ thống AI xử lý và tạo ra nội dung. Được giới thiệu trong bài báo có tính nền tảng năm 2017 "Attention Is All You Need" của Ashish Vaswani và nhóm nghiên cứu tại Google, Transformer cho phép các mô hình nắm bắt những mối quan hệ phức tạp bên trong dữ liệu thông qua một cơ chế gọi là tự chú ý (self-attention).
Cơ chế tự chú ý cho phép mô hình cân nhắc tầm quan trọng của các phần khác nhau trong đầu vào khi tạo ra từng phần của đầu ra. Điều này cho phép mô hình duy trì tính mạch lạc và bối cảnh xuyên suốt những chuỗi văn bản (hoặc dữ liệu khác) dài — điều mà các kiến trúc trước đây gặp khó khăn. Các khía cạnh kỹ thuật then chốt của Transformer có ảnh hưởng đến yêu cầu về dữ liệu bao gồm:
Xử lý song song (Parallel processing) : Khác với các mô hình tuần tự trước đây (mạng nơ-ron hồi quy — recurrent neural network, mạng bộ nhớ ngắn-dài hạn — long short-term memory network), Transformer xử lý đồng thời tất cả các token đầu vào, cho phép huấn luyện hiệu quả trên các tập dữ liệu khổng lồ.
Cửa sổ ngữ cảnh (Context windows) : Transformer hoạt động trong các cửa sổ ngữ cảnh có độ dài cố định, đòi hỏi hạ tầng dữ liệu có khả năng quản lý và truy xuất ngữ cảnh liên quan một cách hiệu quả.
Mã hóa vị trí (Positional encoding) : Transformer sử dụng mã hóa vị trí để hiểu thứ tự của chuỗi, đòi hỏi khâu chuẩn bị dữ liệu phải gìn giữ được các mối quan hệ tuần tự có ý nghĩa.
Cơ chế chú ý (Attention mechanisms) : Cơ chế tự chú ý tạo ra một đồ thị tính toán kết nối mọi token với mọi token khác, cho phép sự hiểu biết theo ngữ cảnh phong phú nhưng đòi hỏi nguồn lực tính toán đáng kể.
Những đặc trưng kiến trúc này ảnh hưởng trực tiếp đến cách dữ liệu phải được cấu trúc, lưu trữ và truy xuất để triển khai GenAI hiệu quả. Các kiến trúc dữ liệu truyền thống vốn được tối ưu cho mẫu truy cập theo hàng (row-based) hoặc theo cột (columnar) thường không phù hợp với mẫu truy cập theo token, giàu bối cảnh mà các mô hình Transformer đòi hỏi.
Dữ liệu doanh nghiệp là yếu tố tạo khác biệt then chốt
Mặc dù các mô hình nền tảng cung cấp những năng lực tổng quát mạnh mẽ, giá trị kinh doanh thực sự của chúng chỉ bộc lộ khi chúng được kết nối với dữ liệu độc đáo của tổ chức bạn. Sự kết nối này biến các hệ thống AI đa năng thành những công cụ kinh doanh chuyên biệt, hiểu được bối cảnh ngành, thuật ngữ riêng của công ty và tri thức chuyên môn theo lĩnh vực của bạn.
Những tổ chức xây dựng được những cây cầu hiệu quả nối giữa dữ liệu độc quyền của mình và các mô hình nền tảng sẽ giành được lợi thế cạnh tranh đáng kể nhờ các giải pháp AI chính xác hơn, phù hợp hơn và đáng tin cậy hơn. Có bốn chiến lược thường được dùng để đạt được điều này:
Kỹ thuật bối cảnh (Context engineering) : Sử dụng RAG để cung cấp thông tin độc quyền của bạn làm bối cảnh cho các mô hình nền tảng. Đòi hỏi tìm kiếm ngữ nghĩa với độ trễ thấp trên các vector nhúng (vector embedding) cùng khả năng cập nhật theo thời gian thực.
Tinh chỉnh (Fine-tuning) : Điều chỉnh các mô hình nền tảng đã được huấn luyện trước bằng các tập dữ liệu chuyên biệt theo lĩnh vực của bạn. Đòi hỏi các tập dữ liệu đã gán nhãn chất lượng cao, có quản lý phiên bản và truy vết nguồn gốc (lineage) rõ ràng.
Huấn luyện mô hình tùy chỉnh (Custom model training) : Xây dựng các mô hình chuyên dụng được tối ưu cho các tình huống sử dụng và dữ liệu cụ thể của bạn. Đòi hỏi khả năng truy cập song song quy mô lớn tới các tập dữ liệu đa dạng, được tối ưu cho thông lượng (throughput) hơn là độ trễ (latency).
Tối ưu hóa mô hình (Model optimization) : Tạo ra các mô hình nhỏ hơn, hiệu quả hơn thông qua các kỹ thuật như chưng cất (distillation) và cắt tỉa (pruning) — vốn nắm bắt được năng lực của các mô hình lớn hơn trong khi đòi hỏi ít nguồn lực hơn.
Như chúng ta sẽ tìm hiểu sâu hơn trong Chương 2, các mẫu triển khai này tạo thành một dải liên tục về mức độ ghép cặp cấu trúc (structural coupling) giữa dữ liệu doanh nghiệp và hành vi của mô hình. Khi các tổ chức tận dụng những năng lực này, việc áp dụng GenAI của họ thường tiến hóa qua các giai đoạn riêng biệt, mỗi giai đoạn đặt ra những đòi hỏi khác nhau lên hạ tầng dữ liệu. Chúng ta sẽ xem xét các giai đoạn đó trong mục "Sự tiến hóa của các ứng dụng GenAI".
Trí tuệ theo bối cảnh: Một ví dụ đơn giản
Việc hiểu các nền tảng kỹ thuật của AI tạo sinh — trí tuệ theo bối cảnh (contextual intelligence), học tự giám sát, và hiểu biết ngữ nghĩa — là điều cốt yếu, bởi vì chúng tạo điều kiện cho những ứng dụng ngày càng tinh vi. Để minh họa sức mạnh của cơ chế tự chú ý, hãy xét một thí nghiệm đơn giản nhưng đầy ý nghĩa. Hãy yêu cầu một mô hình tạo ảnh tạo ra hình "một người đàn ông ngồi bên một bank" (trong tiếng Anh, "bank" vừa có nghĩa là ngân hàng, vừa có nghĩa là bờ sông), và bạn có thể nhận được bức ảnh một người ngồi bên ngoài một tổ chức tài chính. Giờ hãy đổi câu lệnh thành "một người đàn ông câu cá bên một bank", và bức ảnh thu được nhiều khả năng sẽ là một người bên bờ sông (Hình 1-3). Mô hình không đoán mò ngẫu nhiên — nó đang dùng bối cảnh từ các từ xung quanh để phân định giữa những nghĩa khác nhau của từ "bank".

Chú thích Hình 1-3. Các ví dụ ảnh được tạo bởi câu lệnh "một người đàn ông ngồi bên một bank" và "một người đàn ông câu cá bên một bank", sử dụng Amazon Nova Canvas.
[Ghi chú OCR: Một dòng chú thích trên ảnh minh họa của Hình 1-3 bị nhòe/khó đọc trong ảnh gốc nên chưa chắc chắn về nội dung.]
[Ghi chú: Hình đã được cắt riêng vùng hình (lưu cục bộ trong assets/); trang nguồn đầy đủ trên Google Drive (trang này chứa cả Hình 1-3 và 1-4): https://drive.google.com/file/d/1IuHDgSoeLlg7COfT3jo2oEsa_HHNOzxp/view]
Giờ hãy xét cách một từ duy nhất có thể đảo ngược hoàn toàn việc quy chiếu đại từ trong khả năng hiểu ngôn ngữ, như được minh họa trong Hình 1-4. Trong câu "The trophy doesn't fit in the suitcase because it is too big" ("Chiếc cúp không bỏ vừa vali vì nó quá to"), từ "it" ("nó") rõ ràng chỉ chiếc cúp. Nhưng chỉ cần đổi một từ — "The trophy doesn't fit in the suitcase because it is too small" ("Chiếc cúp không bỏ vừa vali vì nó quá nhỏ") — và giờ "it" lại chỉ chiếc vali. Cùng một cấu trúc ngữ pháp, cùng một đại từ, nhưng bối cảnh do từ "big" ("to") so với "small" ("nhỏ") tạo ra đã thay đổi căn bản đối tượng đang được nhắc tới. Điều này cho thấy các mô hình phải tận dụng các manh mối theo bối cảnh và tri thức về thế giới thực — về các ràng buộc vật lý — để diễn giải đúng ý nghĩa.
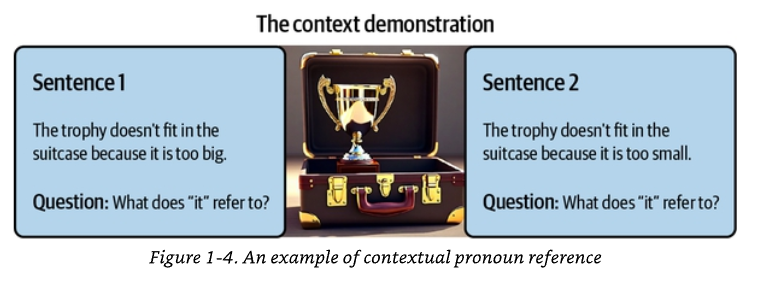
Chú thích Hình 1-4. Một ví dụ về quy chiếu đại từ theo bối cảnh. Câu 1: "The trophy doesn't fit in the suitcase because it is too big." (Hỏi: "it" chỉ cái gì?). Câu 2: "The trophy doesn't fit in the suitcase because it is too small." (Hỏi: "it" chỉ cái gì?).
[Ghi chú: Hình đã được cắt riêng vùng hình (lưu cục bộ trong assets/); trang nguồn đầy đủ trên Google Drive (cùng trang với Hình 1-3): https://drive.google.com/file/d/1Yd9zgyqme51o6XZYHU-kcgdB_TtZLQb_/view]
Khả năng suy ra ý nghĩa từ bối cảnh này cho thấy mô hình nắm bắt được các mối quan hệ ngữ nghĩa ở tầng nội tại — một khác biệt then chốt so với các hệ thống truyền thống vốn dựa vào việc so khớp từ khóa hay các nhãn cứng nhắc. Khi các mô hình tạo sinh được huấn luyện trên dữ liệu ngày càng đa dạng và đồ sộ, sự hiểu biết của chúng càng sâu sắc, cho phép chúng thực hiện những tác vụ mà chúng chưa từng được huấn luyện một cách tường minh.
Loại suy luận theo bối cảnh này không phải là phép màu — nó được học trong quá trình huấn luyện. Để hiểu cách các mô hình AI tạo sinh phân định ý nghĩa một cách tinh tế đến vậy, chúng ta cần xem xét cách chúng biểu diễn ngôn ngữ ở tầng nội tại.
Biểu diễn ý nghĩa trong không gian vector
Làm thế nào một mô hình GenAI hiểu được liệu các từ có gần nhau về mặt ngữ nghĩa hay không? Sự hiểu biết theo bối cảnh này được đặt nền tảng về mặt toán học trong cách các mô hình biểu diễn từ, cụm từ, và thậm chí cả các khái niệm dưới dạng vector trong không gian nhiều chiều (Hình 1-5). Những từ có ý nghĩa hoặc cách dùng theo bối cảnh tương tự nhau sẽ nằm gần nhau hơn, trong khi những từ không liên quan hoặc được dùng khác nhau sẽ nằm cách xa nhau hơn.
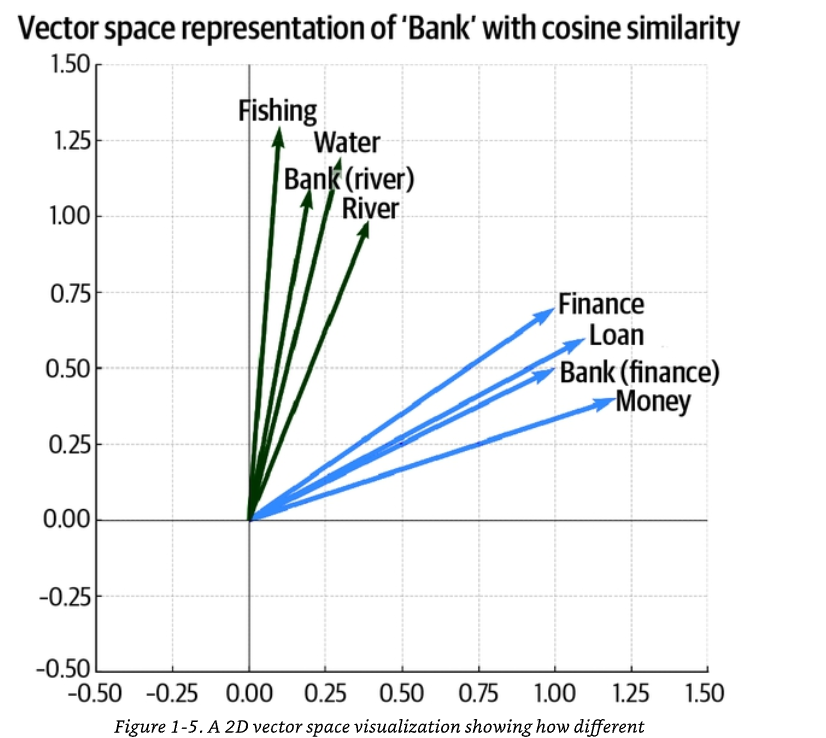
Chú thích Hình 1-5. Một hình ảnh trực quan hóa không gian vector 2 chiều cho thấy các nghĩa khác nhau của từ "bank" được định vị như thế nào trong tương quan với các từ khác. Trong biểu đồ, cụm "Bank (river)" (bờ sông) nằm gần "Water" (nước), "Fishing" (câu cá), "River" (sông); còn cụm "Bank (finance)" (ngân hàng) nằm gần "Finance" (tài chính), "Loan" (khoản vay), "Money" (tiền). Tiêu đề biểu đồ: "Vector space representation of 'Bank' with cosine similarity".
[Ghi chú: Hình đã được cắt riêng vùng hình (lưu cục bộ trong assets/); trang nguồn đầy đủ trên Google Drive: https://drive.google.com/file/d/18QKfX35r4F65fNvlt4pDagR-RpqMWD4i/view]
Trong ví dụ này:
- "Bank (finance)" (ngân hàng) nằm gần các từ như "loan" (khoản vay), "money" (tiền) và "finance" (tài chính).
- "Bank (river)" (bờ sông) xuất hiện gần "water" (nước), "fishing" (câu cá) và "river" (sông).
- Góc giữa hai vector "bank" rất lớn, biểu thị độ tương đồng cosine (cosine similarity) thấp (tức là mức độ trùng lặp về bối cảnh thấp).
Cấu trúc này cho phép các hệ thống AI tạo sinh suy luận theo ngữ nghĩa thay vì theo cú pháp, khiến chúng có khả năng thực hiện các tác vụ như tìm kiếm theo bối cảnh, tóm tắt, trả lời câu hỏi và sáng tạo nội dung theo những cách mà AI truyền thống không thể. Khả năng tìm kiếm ngữ nghĩa này — mà chúng ta sẽ tìm hiểu như một trong năm mẫu kiến trúc đang nổi lên ở phần sau của chương — đang trở thành một yêu cầu nền tảng đối với các hệ thống AI doanh nghiệp.
Ví dụ doanh nghiệp: Hiểu biết xuyên tài liệu trong hỗ trợ khách hàng
Để minh họa cách sự hiểu biết dựa trên vector này được áp dụng trong bối cảnh kinh doanh, hãy xét một cơ sở tri thức hỗ trợ khách hàng với các mục sau:
- Sản phẩm X yêu cầu phiên bản firmware 2.1 trở lên khi dùng với bộ điều khiển Y3000.
- Bộ điều khiển Y3000 đã bị ngừng hỗ trợ (deprecated) vào tháng 11/2023 và được thay thế bằng mẫu Y3500.
- Bộ điều khiển Y3500 tương thích ngược với tất cả các sản phẩm vốn yêu cầu bộ điều khiển Y3000.
Khi một nhân viên hỗ trợ hỏi "Sản phẩm X cần firmware nào?", các hệ thống truyền thống dựa trên từ khóa nhiều khả năng chỉ trả về tài liệu đầu tiên. Nhưng một hệ thống GenAI sử dụng hiểu biết ngữ nghĩa có thể:
- Nhận ra rằng cả ba tài liệu đều liên quan với nhau theo bối cảnh thông qua việc cùng nhắc đến các bộ điều khiển.
- Hiểu mối quan hệ theo thời gian giữa mẫu Y3000 và mẫu Y3500 mới hơn.
- Kết nối phát biểu về tính tương thích để đưa ra một câu trả lời đầy đủ, bao gồm cả yêu cầu ban đầu lẫn thông tin về bộ điều khiển đã được cập nhật.
Khả năng rút ra bối cảnh xuyên nhiều tài liệu này, như được minh họa trong Hình 1-6, chính là điều khiến GenAI khác biệt về căn bản so với các hệ thống dữ liệu truyền thống — vốn có kiến trúc dữ liệu thường không hỗ trợ hiệu quả những năng lực này.
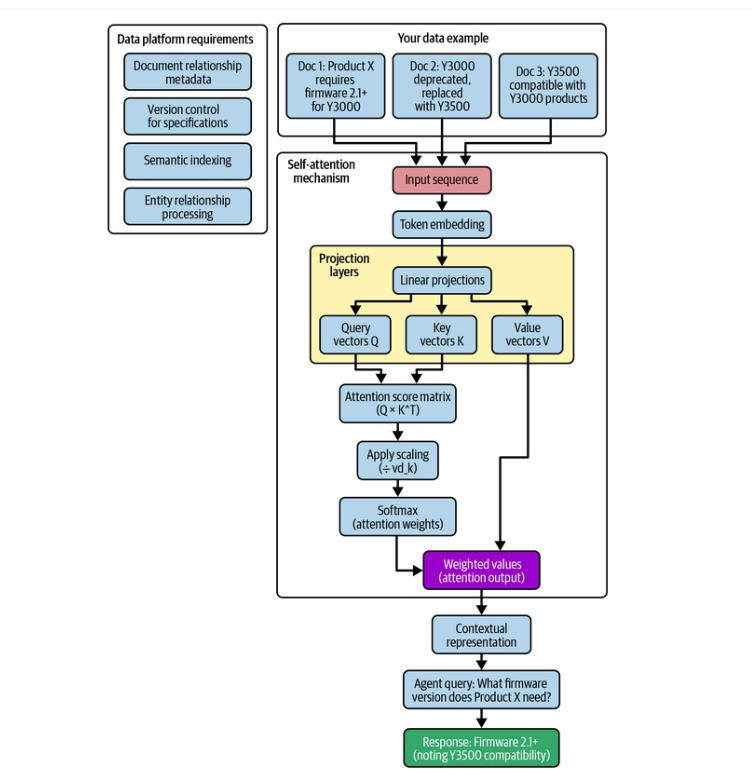
Chú thích Hình 1-6. Cách cơ chế tự chú ý cho phép sự hiểu biết xuyên tài liệu tinh vi, kết nối thông tin qua ba tài liệu để đưa ra câu trả lời đầy đủ về yêu cầu firmware. Sơ đồ minh họa luồng xử lý: chuỗi đầu vào (input sequence) → nhúng token (token embedding) → các lớp chiếu (projection layers) tạo ra vector Truy vấn (Query — Q), vector Khóa (Key — K), vector Giá trị (Value — V) → ma trận điểm chú ý (Q × K^T) → áp dụng tỷ lệ co giãn (chia cho căn bậc hai của d_k) → softmax (trọng số chú ý) → giá trị có trọng số (đầu ra chú ý) → biểu diễn theo bối cảnh. Truy vấn của tác nhân: "Sản phẩm X cần phiên bản firmware nào?" → Phản hồi: "Firmware 2.1+ (lưu ý khả năng tương thích của Y3500)". Các yêu cầu đối với nền tảng dữ liệu được nêu: siêu dữ liệu về quan hệ tài liệu, kiểm soát phiên bản cho các thông số kỹ thuật, lập chỉ mục ngữ nghĩa, xử lý quan hệ thực thể.
[Ghi chú: Hình đã được cắt riêng vùng hình (lưu cục bộ trong assets/); trang nguồn đầy đủ trên Google Drive: https://drive.google.com/file/d/1Ks581MTygDLOQSslPKtEXZbrVlv0bWx2/view]
Hiểu cách các mô hình GenAI xử lý và biểu diễn ý nghĩa là chìa khóa để thiết kế những hệ thống thông minh — nhưng đó chỉ là một phần của bức tranh. Khi các công nghệ này tiến hóa từ những trợ lý đơn giản thành các tác nhân tự chủ, các tổ chức đang đáp ứng bằng cách xây dựng những kiến trúc dữ liệu mới — bắc cầu nối khoảng cách giữa các hệ thống truyền thống và hạ tầng sẵn sàng cho AI (xem Bảng 1-1).
Bảng 1-1. Những khác biệt giữa AI truyền thống và AI tạo sinh
| Đặc điểm | AI truyền thống | AI tạo sinh |
|---|---|---|
| Phương pháp học | Học có giám sát với dữ liệu đã gán nhãn | Học tự giám sát từ dữ liệu thô |
| Hiểu biết | So khớp mẫu theo cú pháp | Hiểu biết ngữ nghĩa theo bối cảnh |
| Biểu diễn | Vector đặc trưng (feature vector) | Vector nhúng theo bối cảnh (contextual embedding) trong không gian vector |
| Năng lực | Phân loại, dự đoán, gợi ý | Tạo sinh, suy luận, hiểu biết theo bối cảnh |
| Yêu cầu về dữ liệu | Tập dữ liệu có cấu trúc, đã gán nhãn | Dữ liệu đa dạng, giàu bối cảnh, có các mối quan hệ |
| Nhu cầu hạ tầng | Xử lý theo lô (batch), kho dữ liệu (data warehouse) | Truy xuất thời gian thực, cơ sở dữ liệu vector, quản lý bối cảnh |
Sự tiến hóa của các ứng dụng GenAI
Khi các công nghệ AI tạo sinh trưởng thành, chúng ta đang chứng kiến một sự tiến hóa nhanh chóng trong ứng dụng của chúng, từ những trợ lý đơn giản đến các tác nhân ngày càng tự chủ. Bước tiến này không chỉ thể hiện sự tiến bộ về kỹ thuật mà còn là một sự dịch chuyển căn bản trong cách các hệ thống AI tương tác với dữ liệu, người dùng và thế giới — một điều mà các tổ chức phải hiểu để chuẩn bị hạ tầng dữ liệu của mình cho cả các năng lực AI hiện tại lẫn tương lai.
Từ trợ lý đến tác nhân: Bốn giai đoạn tiến hóa của GenAI
Sự tiến hóa của các ứng dụng GenAI có thể được hiểu qua bốn giai đoạn riêng biệt (thể hiện trong Hình 1-7), mỗi giai đoạn kế thừa năng lực của giai đoạn trước trong khi đặt ra những yêu cầu mới về dữ liệu và những thách thức mới cho tổ chức.
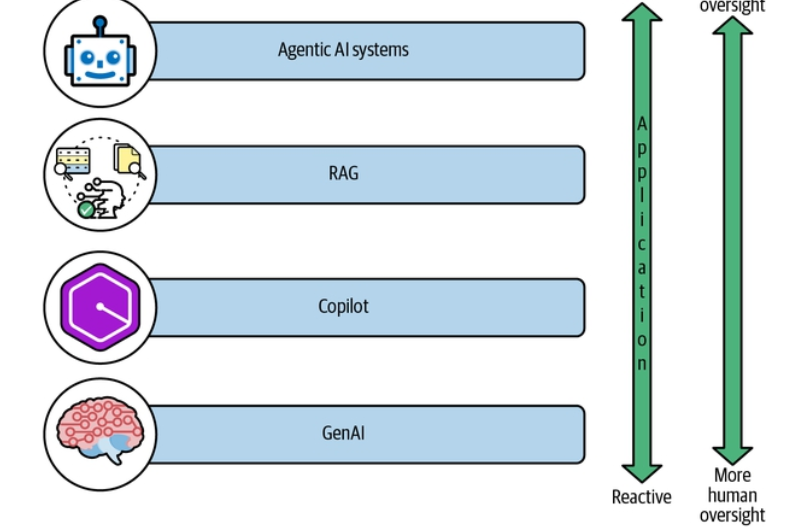
Chú thích Hình 1-7. Bốn giai đoạn tiến hóa của GenAI. Theo trục tiến triển: GenAI → Copilot (trợ lý đồng hành) → RAG → Hệ thống AI tác nhân (Agentic AI systems). Càng tiến về sau, hệ thống càng chủ động (proactive) và cần ít sự giám sát của con người hơn (less human oversight); càng về đầu, hệ thống càng bị động (reactive) và cần nhiều sự giám sát của con người hơn (more human oversight).
[Ghi chú: Hình đã được cắt riêng vùng hình (lưu cục bộ trong assets/); trang nguồn đầy đủ trên Google Drive: https://drive.google.com/file/d/1fJwIjQzacbMiz1m1GBm7PmMEYizyhEu2/view]
Giai đoạn 1: Trợ lý AI — truy xuất thông tin và hoàn thành tác vụ cơ bản
Thế hệ ứng dụng GenAI đầu tiên tập trung vào việc cung cấp thông tin và hoàn thành các tác vụ đơn giản để đáp lại truy vấn trực tiếp của người dùng. Những trợ lý này, như các phiên bản đầu của ChatGPT và Gemini, làm tốt các việc:
- Trả lời câu hỏi dựa trên dữ liệu huấn luyện của chúng.
- Tạo nội dung như email, bản tóm tắt, hoặc văn bản sáng tạo.
- Giải thích các khái niệm hoặc quy trình.
- Dịch giữa các ngôn ngữ.
Các hệ thống này chủ yếu dựa vào tri thức đã được huấn luyện trước, với khả năng hạn chế trong việc truy cập hoặc suy luận về thông tin mới. Yêu cầu về dữ liệu của chúng tương đối đơn giản — chúng cần dữ liệu huấn luyện chất lượng cao nhưng ít cần tích hợp dữ liệu thời gian thực hay quản lý tri thức phức tạp.
Giai đoạn 2: Trợ lý đồng hành (copilot) — cộng tác cùng con người
Giai đoạn thứ hai chứng kiến các hệ thống GenAI tiến hóa thành những trợ lý đồng hành (copilot) làm việc song song với con người, tăng cường năng lực của họ trong các lĩnh vực cụ thể. Ví dụ gồm GitHub Copilot cho lập trình, Microsoft 365 Copilot cho năng suất văn phòng, và Adobe Firefly cho công việc sáng tạo. Các copilot này:
- Hiểu bối cảnh và thuật ngữ chuyên biệt theo lĩnh vực.
- Tạo nội dung và gợi ý phù hợp với lĩnh vực.
- Học từ phản hồi và sở thích của người dùng.
- Tích hợp với các công cụ và quy trình làm việc hiện có.
Copilot đặt ra những yêu cầu dữ liệu phức tạp hơn, bao gồm nhu cầu truy cập các cơ sở tri thức chuyên ngành, hiểu các định dạng dữ liệu độc quyền, và duy trì bối cảnh xuyên suốt các phiên làm việc của người dùng. Chúng bắt đầu làm mờ ranh giới giữa hệ thống AI tổng quát và hệ thống AI chuyên biệt, đòi hỏi các chiến lược tích hợp dữ liệu tinh vi hơn.
Giai đoạn 3: Tác nhân dựa trên RAG — tri thức và hiểu biết bối cảnh được tăng cường
Giai đoạn thứ ba giới thiệu kỹ thuật tạo sinh tăng cường truy xuất (RAG) để khắc phục giới hạn của tri thức huấn luyện trước. Các tác nhân dựa trên RAG có thể:
- Truy cập và suy luận trên các cơ sở tri thức doanh nghiệp theo thời gian thực.
- Cung cấp thông tin cập nhật vượt quá mốc thời gian huấn luyện của chúng.
- Đặt câu trả lời trên nền tảng các tài liệu hoặc nguồn dữ liệu cụ thể (grounding).
- Kết nối thông tin xuyên các nguồn vốn trước đây bị tách rời (siloed).
RAG làm tăng đáng kể độ phức tạp của yêu cầu dữ liệu, đòi hỏi:
- Cơ sở dữ liệu vector cho tìm kiếm ngữ nghĩa.
- Đường ống nhúng (embedding pipeline) để chuyển tài liệu thành biểu diễn vector.
- Quản lý siêu dữ liệu để truy nguồn (source attribution).
- Cơ chế làm mới nội dung để duy trì tính cập nhật.
Các tổ chức triển khai tác nhân dựa trên RAG phát hiện rằng kiến trúc dữ liệu hiện có của họ thường không đáp ứng được những yêu cầu mới này, dẫn đến các thách thức triển khai mà chúng ta sẽ bàn ở phần sau của chương.
Giai đoạn 4: AI tác nhân (agentic AI) — tự chủ ra quyết định và hành động
Biên giới thứ tư và cũng là hiện tại của quá trình tiến hóa GenAI là AI tác nhân — những hệ thống có thể tự chủ lập kế hoạch và thực thi các tác vụ phức tạp với mức giám sát tối thiểu của con người. Các tác nhân này:
- Phân rã mục tiêu phức tạp thành các bước có thể hành động.
- Truy cập nhiều công cụ và API để hoàn thành tác vụ.
- Ra quyết định dựa trên thông tin thời gian thực.
- Học từ thành công và thất bại để cải thiện hiệu năng.
- Vận hành với mức độ tự chủ ngày càng cao.
AI tác nhân thể hiện một bước nhảy vọt về yêu cầu dữ liệu và mức độ sẵn sàng của tổ chức. Những hệ thống này cần không chỉ quyền truy cập thông tin mà còn:
- Khung phân quyền (permission framework) để kiểm soát hành động.
- Hệ thống giám sát để theo dõi.
- Cơ chế phản hồi để học hỏi.
- Kiểm soát bảo mật để ngăn lạm dụng.
- Xác minh độ tin cậy của nguồn dữ liệu.
Giai đoạn 4 đã bắt đầu xuất hiện trong các lĩnh vực chuyên biệt. Hơn một triệu robot của Amazon minh chứng cho việc tự chủ ra quyết định trong hậu cần (logistics) — chúng tự đưa ra quyết định độc lập về xử lý kiện hàng, tối ưu hóa lộ trình và quản lý tồn kho.
Độ phức tạp ngày càng tăng của yêu cầu dữ liệu
Mỗi giai đoạn tiến hóa lại đặt ra những yêu cầu và thách thức dữ liệu mới, như thể hiện trong Bảng 1-2.
Bảng 1-2. Sự tiến hóa của AI tạo sinh
| Giai đoạn GenAI | Trọng tâm dữ liệu chính | Yêu cầu dữ liệu then chốt | Thách thức tổ chức |
|---|---|---|---|
| Trợ lý AI | Tri thức đã huấn luyện trước | Dữ liệu huấn luyện chất lượng cao | Quản lý kỳ vọng về giới hạn tri thức |
| Trợ lý đồng hành (copilot) | Tri thức chuyên ngành | Tích hợp với hệ thống và định dạng độc quyền | Cân bằng giữa hỗ trợ và chuyên môn con người |
| Tác nhân dựa trên RAG | Cơ sở tri thức doanh nghiệp | Cơ sở dữ liệu vector, đường ống nhúng, quản lý siêu dữ liệu | Phá vỡ các "ốc đảo" dữ liệu (data silo), bảo đảm chất lượng dữ liệu |
| AI tác nhân | Tri thức đa nguồn và quyền hành động | Khung phân quyền, hệ thống giám sát, xác minh độ tin cậy | Bảo mật, quản trị, trách nhiệm pháp lý, khả năng quan sát và kiểm soát |
Độ phức tạp mang tính tiến hóa này lý giải vì sao quá nhiều tổ chức chật vật để vượt khỏi giai đoạn thử nghiệm, và vì sao những tổ chức đã triển khai thành công các ứng dụng GenAI ở giai đoạn trước vẫn có thể gặp khó khăn với những triển khai cao cấp hơn — mỗi giai đoạn đòi hỏi những cân nhắc về kiến trúc dữ liệu khác nhau về căn bản. Tuy nhiên, bằng cách nghiên cứu các khuôn mẫu đang nổi lên trong những lần triển khai thành công, ta có thể nhận diện những cách tiếp cận kiến trúc cụ thể nhằm đáp ứng các yêu cầu ngày càng leo thang này.
Những gì các tổ chức dẫn đầu đang xây dựng hôm nay
Dù khoảng cách giữa thử nghiệm và vận hành vẫn còn lớn — với chưa tới 10% tổ chức mở rộng GenAI thành công ở hiện tại — một xu hướng rõ ràng đang nổi lên trong số những tổ chức thành công. Thay vì chờ đợi các giải pháp hoàn hảo, các tổ chức dẫn đầu đang xây dựng những hệ thống triển khai các mẫu kiến trúc riêng biệt, biến hạ tầng dữ liệu truyền thống thành nền tảng sẵn sàng cho AI, giúp họ đi từ bản thử nghiệm khái niệm đến vận hành thực tế.
Bài kiểm tra thực tế về vận hành
Ấn bản năm 2025 của khảo sát McKinsey Global Survey on AI cho thấy một khoảng cách triển khai đáng chú ý. Dù 88% tổ chức nay dùng AI trong ít nhất một chức năng — tăng từ 72% năm 2024 — bước chuyển từ thí điểm sang vận hành vẫn khó khăn. Mức độ thành công trong việc tạo ra giá trị doanh nghiệp thực chất khác nhau rõ rệt theo độ phức tạp của tình huống sử dụng: 15–20% tổ chức đã mở rộng thành công AI cho xử lý tài liệu và dịch vụ khách hàng; 10–15% đã vượt qua giai đoạn thử nghiệm trong tạo sinh nội dung và phân tích dữ liệu; và chưa tới 10% (hiện ước tính khoảng 6% là nhóm "hiệu suất cao") đã triển khai thành công AI cho việc ra quyết định phức tạp hoặc các tác nhân tự chủ.
Trong chính công việc của mình, chúng tôi đã chứng kiến những thách thức này tận mắt. Một khách hàng đã phải thu hồi (roll back) việc triển khai GenAI của họ — không phải vì vấn đề mô hình hay câu lệnh mà do chất lượng dữ liệu kém; trong khi mọi thứ hoạt động tốt trong môi trường thử nghiệm, việc sử dụng thực tế ở môi trường vận hành đã phơi bày những điểm thiếu nhất quán trong dữ liệu, buộc phải dừng lại hoàn toàn. Họ hiện đang tập trung xây dựng lại nền tảng dữ liệu của mình.
Chúng tôi cũng đã dẫn dắt những lần triển khai thành công, chẳng hạn một giải pháp phân tích chênh lệch (variance analysis) cho văn phòng giám đốc tài chính (CFO) — xử lý dữ liệu hoạch định nguồn lực doanh nghiệp (ERP), tính toán các chênh lệch, và dùng AI để soạn thảo các bình luận tài chính. Trong một trường hợp khác, chúng tôi giúp một khách hàng xây dựng tác nhân trò chuyện (chat agent) tiếp thị tạo ra nội dung được bản địa hóa cho các đội ngũ hiện trường của họ.
Trong những lần triển khai thực tế kiểu này, năm mẫu kiến trúc riêng biệt đã nổi lên. Đây không chỉ là các khung lý thuyết; chúng là những cách tiếp cận đã được kiểm chứng, thiết kế để vượt qua giới hạn của các kiến trúc dữ liệu truyền thống khi phải đáp ứng những đòi hỏi đặc thù của GenAI.
Các mẫu kiến trúc GenAI đang nổi lên
Phần này tìm hiểu chi tiết năm mẫu kiến trúc đang nổi lên.
Mẫu 1: Đồ thị tri thức (knowledge graph) cho trí tuệ theo bối cảnh
Đó là gì: Đồ thị tri thức kết nối các nguồn dữ liệu rời rạc thông qua việc ánh xạ quan hệ một cách tường minh, tạo ra một mạng lưới ngữ nghĩa cho phép suy luận liên miền. Khác với cơ sở dữ liệu truyền thống lưu các bản ghi cô lập, đồ thị tri thức biểu diễn các thực thể (khách hàng, sản phẩm, giao dịch) và quan hệ giữa chúng (đã mua, đã trả lại, được gợi ý) dưới dạng các nút (node) liên kết với nhau.
Vì sao quan trọng với AI: Các tác nhân GenAI cần hiểu bối cảnh xuyên các ranh giới của tổ chức. Khi một nhân viên dịch vụ khách hàng hỏi "Vì sao khách hàng này trả lại ba đơn hàng tháng trước?", câu trả lời đòi hỏi phải kết nối dữ liệu khách hàng, lịch sử đơn hàng, thông số sản phẩm, hậu cần vận chuyển, và phiếu hỗ trợ — những dữ liệu thường nằm ở các hệ thống riêng biệt. Đồ thị tri thức làm cho các kết nối này trở nên tường minh và có thể truy vấn.
Ví dụ thực địa: Một tổ chức dịch vụ tài chính đã triển khai một đồ thị tri thức kết nối hồ sơ khách hàng, lịch sử giao dịch, dữ liệu thị trường và các yêu cầu pháp lý. Tác nhân tuân thủ (compliance agent) dựa trên RAG của họ nay có thể trả lời những câu hỏi như "Những khách hàng nào chịu tác động bởi quy định mới của EU?" bằng cách duyệt qua các quan hệ trên những tập dữ liệu vốn trước đây bị tách rời. Thời gian phân tích giảm từ nhiều ngày xuống còn vài phút.
Yêu cầu dữ liệu:
- Cơ sở dữ liệu đồ thị (Neo4j, Amazon Neptune) để lưu quan hệ.
- Đường ống phân giải thực thể (entity resolution) để nhận diện và hợp nhất các thực thể trùng lặp.
- Quản lý bản thể luận (ontology) để định nghĩa quan hệ nhất quán.
- Đồng bộ liên tục từ các hệ thống nguồn.
Mẫu này được minh họa trong Hình 1-8.
Tiến hóa lên data mesh: Các tổ chức dẫn đầu đang mở rộng mẫu này bằng cách coi đồ thị tri thức như những sản phẩm dữ liệu liên hợp (federated data product). Thay vì tập trung mọi dữ liệu vào một đồ thị duy nhất, họ tạo ra các đồ thị tri thức theo từng miền (đồ thị khách hàng, đồ thị sản phẩm, đồ thị chuỗi cung ứng) mà các tác nhân có thể tự khám phá và truy vấn. Cách tiếp cận data mesh này cho phép mở rộng quy mô mà không bị nghẽn ở một điểm tập trung.
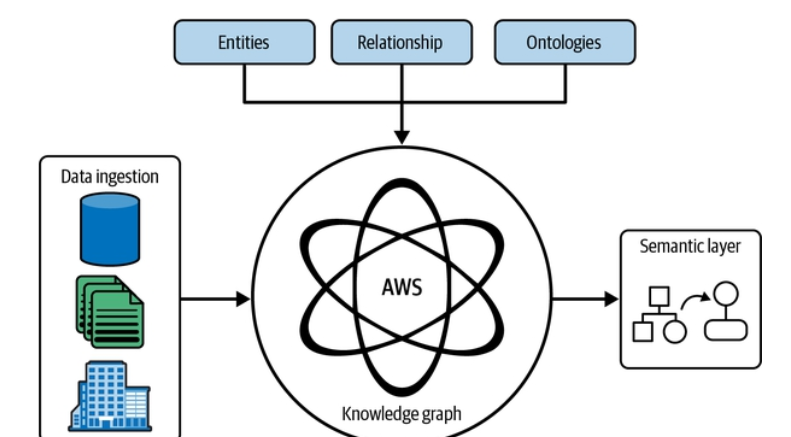
Chú thích Hình 1-8. Đồ thị tri thức cho trí tuệ theo bối cảnh. Sơ đồ: nạp dữ liệu (data ingestion) → thực thể (entities), quan hệ (relationship), bản thể luận (ontologies) → lớp ngữ nghĩa (semantic layer) → đồ thị tri thức (trên nền AWS).
[Ghi chú: Hình đã được cắt riêng vùng hình (lưu cục bộ trong assets/); trang nguồn đầy đủ trên Google Drive: https://drive.google.com/file/d/1U9CE4erW8CRSBrCjjV1Xva1RiqI4qsE6/view]
Mẫu 2: Nền tảng hướng sự kiện (event-driven) cho AI thời gian thực
Đó là gì: Kiến trúc hướng sự kiện thay thế xử lý theo lô (batch) bằng các đường ống dữ liệu luồng (streaming) — nắm bắt và lan truyền các thay đổi ngay khi chúng xảy ra. Mọi sự kiện kinh doanh — một giao dịch mua của khách hàng, cập nhật tồn kho, thay đổi giá, hay một phiếu hỗ trợ — đều chảy qua các luồng sự kiện mà nhiều hệ thống có thể tiêu thụ theo thời gian thực.
Vì sao quan trọng với AI: Các tác nhân cần bối cảnh tươi mới, không phải dữ liệu cũ từ tác vụ batch đêm qua. Khi một khách hàng hỏi "Mặt hàng này còn hàng không?", câu trả lời phải phản ánh những thay đổi tồn kho từ vài giây trước, chứ không phải ảnh chụp của ngày hôm qua. Kiến trúc hướng sự kiện bảo đảm các tác nhân luôn làm việc với thông tin hiện hành.
Ví dụ thực địa: Một tổ chức bán lẻ đã thay quy trình trích xuất–biến đổi–nạp (ETL) theo lô hằng đêm bằng luồng sự kiện dựa trên Kafka. Các sự kiện hành vi khách hàng (lượt xem trang, thêm vào giỏ, mua hàng) chảy liên tục tới cơ sở dữ liệu vector, cập nhật các vector nhúng sản phẩm gần như theo thời gian thực. Tác nhân gợi ý có thể phản ứng với các sản phẩm đang thịnh hành trong vài phút thay vì vài ngày, dẫn đến tỷ lệ chuyển đổi tăng lên.
Yêu cầu dữ liệu:
- Nền tảng luồng sự kiện (Kafka, Amazon Kinesis).
- Nắm bắt thay đổi dữ liệu (change data capture — CDC) từ các hệ thống nguồn.
- Khung xử lý luồng (Flink, Spark Streaming) để biến đổi dữ liệu.
- Cập nhật cơ sở dữ liệu vector với độ trễ thấp.
Hình 1-9 trực quan hóa mẫu này.
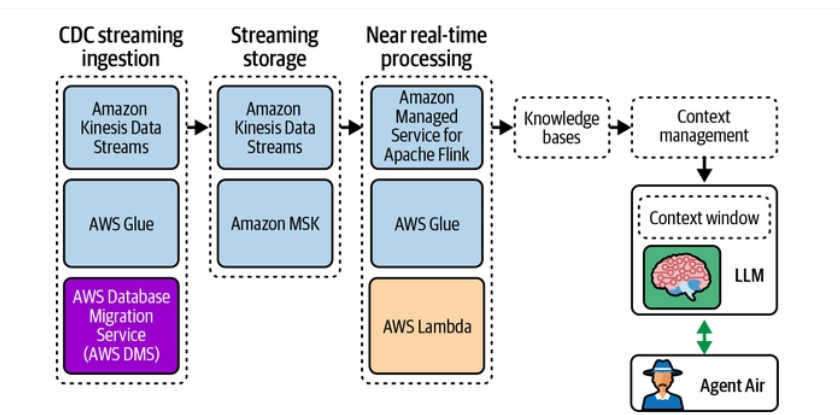
Chú thích Hình 1-9. Nền tảng hướng sự kiện cho AI thời gian thực. Sơ đồ minh họa luồng xử lý gần thời gian thực: nạp dữ liệu kiểu CDC streaming → lưu trữ luồng (Amazon Kinesis Data Streams, Amazon MSK) → xử lý (AWS Glue, Amazon Managed Service for Apache Flink, AWS DMS, AWS Lambda) → cơ sở tri thức và quản lý bối cảnh → cửa sổ ngữ cảnh → LLM → tác nhân.
[Ghi chú: Hình đã được cắt riêng vùng hình (lưu cục bộ trong assets/); trang nguồn đầy đủ trên Google Drive: https://drive.google.com/file/d/1BxOoif5-Ai20URYeGEKXyNHgTKe23ah5/view]
Làm mới bối cảnh thời gian thực: Những lần triển khai tinh vi nhất mở rộng mẫu này để liên tục cập nhật các vector nhúng khi tài liệu nguồn thay đổi. Khi một thông số sản phẩm được cập nhật, đường ống nhúng tự động tái tạo các vector và cập nhật chỉ mục tìm kiếm ngữ nghĩa, bảo đảm các tác nhân không bao giờ truy xuất thông tin lỗi thời.
Mẫu 3: Lakehouse như nền tảng AI hợp nhất
Đó là gì: Kiến trúc lakehouse hội tụ data lake và data warehouse thành một nền tảng hợp nhất, hỗ trợ cả khối lượng công việc phân tích lẫn AI. Được xây dựng trên các định dạng bảng mở (open table format) như Apache Iceberg, Delta Lake và Apache Hudi, lakehouse cung cấp các giao dịch ACID, khả năng tiến hóa lược đồ (schema evolution), và "du hành thời gian" (time travel — khả năng truy vấn các ảnh chụp lịch sử của dữ liệu) ngay trên kho lưu trữ data lake — kết hợp sự linh hoạt của lake với độ tin cậy của warehouse.
Vì sao quan trọng với AI: Các kiến trúc truyền thống buộc tổ chức phải chọn giữa data lake (linh hoạt, phi cấu trúc) và data warehouse (có cấu trúc, hiệu năng cao). GenAI cần cả hai: tài liệu phi cấu trúc cho RAG, dữ liệu có cấu trúc cho phân tích, và khả năng kết nối chúng một cách liền mạch. Lakehouse cho phép điều này.
Ví dụ thực địa: Một tổ chức y tế đã hợp nhất 15 năm dữ liệu nghiên cứu lâm sàng — kết quả thử nghiệm có cấu trúc, các bài báo nghiên cứu phi cấu trúc, hồ sơ bệnh nhân, và tài liệu pháp lý — vào một lakehouse dựa trên Iceberg. Các tác nhân nghiên cứu của họ nay có thể truy vấn xuyên mọi loại dữ liệu qua một giao diện duy nhất, kết nối kết quả thử nghiệm có cấu trúc với ghi chú nghiên cứu phi cấu trúc. Thời gian chuẩn bị dữ liệu giảm từ nhiều tuần xuống còn vài giờ.
Yêu cầu dữ liệu:
- Định dạng bảng mở (Iceberg, Delta Lake, Hudi) cho lưu trữ hợp nhất.
- Truy cập đa công cụ (Spark, Trino, Athena) cho các khối lượng công việc đa dạng.
- Quản trị hợp nhất (Lake Formation, Unity Catalog) trên toàn bộ dữ liệu.
- Hỗ trợ nhiều loại dữ liệu (có cấu trúc, bán cấu trúc, phi cấu trúc).
Hình 1-10 minh họa mẫu này.
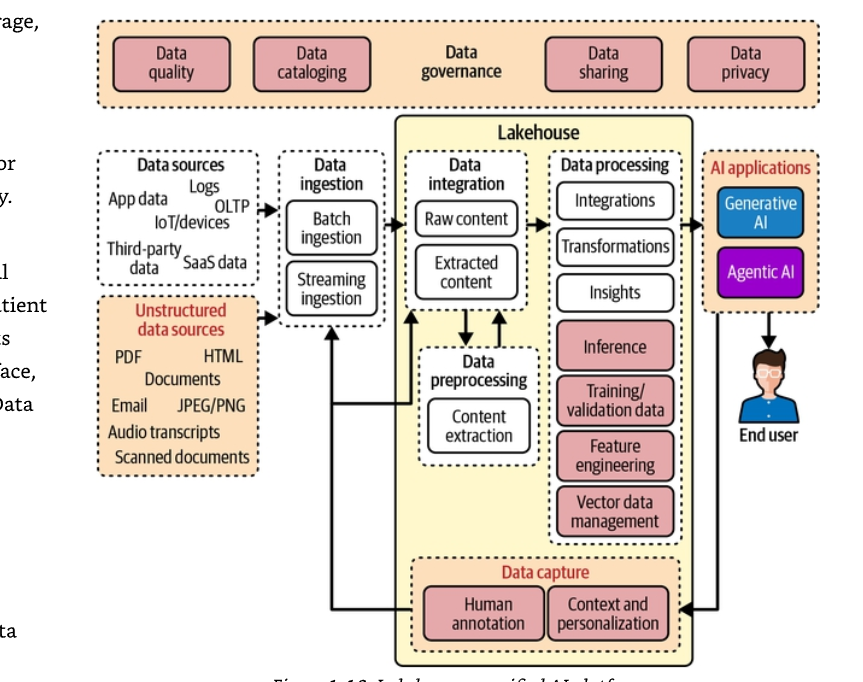
Chú thích Hình 1-10. Lakehouse như nền tảng AI hợp nhất. Sơ đồ tổng thể gồm các lớp quản trị (chất lượng dữ liệu, lập danh mục, quản trị, chia sẻ, quyền riêng tư) bao quanh luồng: nguồn dữ liệu (OLTP, IoT, dữ liệu ứng dụng, bên thứ ba, SaaS, nguồn phi cấu trúc như HTML, tài liệu, JPEG/PNG, PDF, email, bản ghi âm, tài liệu quét) → nạp dữ liệu (batch/streaming/trích xuất nội dung) → tích hợp và xử lý (tiền xử lý, trích xuất nội dung, kỹ thuật đặc trưng, quản lý dữ liệu vector, chú thích của con người) → ứng dụng AI (Generative AI, Agentic AI, suy luận, insight, cá nhân hóa theo bối cảnh).
[Ghi chú: Hình đã được cắt riêng vùng hình (lưu cục bộ trong assets/); trang nguồn đầy đủ trên Google Drive: https://drive.google.com/file/d/1cqgAhphUmASYWgRoHKdpmW4O-XAPF75p/view]
Tiến hóa đa phương thức (multimodal): Các tổ chức dẫn đầu đang mở rộng lakehouse để hỗ trợ dữ liệu đa phương thức — văn bản, hình ảnh, âm thanh, video và dữ liệu có cấu trúc trong một nền tảng duy nhất. Điều này cho phép các tác nhân suy luận xuyên các phương thức, phân tích hình ảnh sản phẩm cùng với đánh giá của khách hàng và dữ liệu bán hàng, hoặc đối chiếu bản ghi âm với các chỉ số có cấu trúc của tổng đài.
Mẫu 4: Tìm kiếm ngữ nghĩa như lớp truy vấn mới
Đó là gì: Tìm kiếm ngữ nghĩa thay thế truy xuất dựa trên từ khóa truyền thống bằng tìm kiếm tương đồng dựa trên vector. Tài liệu được chuyển thành các vector nhúng nhiều chiều nắm bắt ý nghĩa, cho phép truy xuất dựa trên sự tương đồng về khái niệm thay vì khớp từ chính xác.
Vì sao quan trọng với AI: Các tác nhân dựa trên RAG chỉ tốt ngang với hệ thống truy xuất của chúng. Khi một người dùng hỏi "Chúng ta xử lý các yêu cầu về quyền riêng tư dữ liệu của châu Âu như thế nào?", tìm kiếm theo từ khóa có thể bỏ sót những tài liệu bàn về "tuân thủ GDPR" hay "quy định bảo vệ dữ liệu EU". Tìm kiếm ngữ nghĩa hiểu rằng đây là các khái niệm liên quan và truy xuất tất cả tài liệu phù hợp.
Ví dụ thực địa: Một công ty sản xuất đã xây dựng một lớp tìm kiếm ngữ nghĩa trên 30 năm thông số kỹ thuật. Tác nhân thiết kế của họ nay có thể tìm các linh kiện tương tự xuyên suốt hàng thập kỷ tài liệu, ngay cả khi thuật ngữ đã thay đổi. Kỹ sư đặt câu hỏi bằng ngôn ngữ tự nhiên ("Tìm vật liệu nhẹ phù hợp cho ứng dụng nhiệt độ cao") và nhận về các thông số phù hợp từ những tài liệu chưa từng dùng đúng những từ đó.
Yêu cầu dữ liệu:
- Cơ sở dữ liệu vector (Pinecone, OpenSearch, pgvector, v.v.) để lưu vector nhúng.
- Mô hình nhúng (ví dụ text-embedding-ada-002, Titan Embeddings) để vector hóa tài liệu.
- Khả năng tìm kiếm lai (hybrid search) kết hợp truy xuất ngữ nghĩa và từ khóa.
- Lọc theo siêu dữ liệu để kiểm soát truy cập và tinh chỉnh độ liên quan.
Hiểu biết khi triển khai: Những lần triển khai hiệu quả nhất sử dụng tìm kiếm lai, kết hợp tương đồng ngữ nghĩa với khớp từ khóa và bộ lọc siêu dữ liệu. Điều này bảo đảm các tác nhân truy xuất được những tài liệu vừa liên quan về mặt khái niệm vừa khớp chính xác các tiêu chí cụ thể (khoảng thời gian, loại tài liệu, mức phân loại bảo mật).
Mẫu 5: Tài sản số sẵn sàng cho tác nhân (agent-ready)
Đó là gì: Các tổ chức đang thiết kế lại tài sản số của mình — website, sản phẩm, API và tài liệu — để được các tác nhân AI tiêu thụ, chứ không chỉ con người. Điều này bao gồm đánh dấu dữ liệu có cấu trúc (Schema.org), API đọc được bằng máy, và tài liệu thân thiện với tác nhân, cho phép khám phá và tương tác tự chủ.
Vì sao quan trọng với AI: Trong nền kinh tế do tác nhân dẫn dắt đang nổi lên, khách hàng sẽ không tự duyệt website của bạn — tác nhân của họ sẽ làm điều đó. Nếu thông tin sản phẩm của bạn không đọc được bằng máy, tác nhân của đối thủ sẽ gợi ý sản phẩm của họ thay vào đó. Tài sản sẵn sàng cho tác nhân bảo đảm doanh nghiệp của bạn vẫn có thể được khám phá và tiếp cận trong một thế giới được AI làm trung gian.
Ví dụ thực địa: Một công ty thương mại điện tử đã tái cấu trúc danh mục sản phẩm với đánh dấu Schema.org, tạo các đặc tả OpenAPI cho mọi dịch vụ, và xây dựng một lớp API có thể truy cập bởi tác nhân. Khi các tác nhân mua sắm truy vấn "Tìm ghế văn phòng công thái học dưới 500 đô-la có giao hàng vào ngày hôm sau", hệ thống đáp lại bằng dữ liệu sản phẩm có cấu trúc mà tác nhân có thể trực tiếp so sánh và hành động. Doanh số do tác nhân dẫn dắt nay chiếm 12% doanh thu và đang tăng.
Yêu cầu dữ liệu:
- Đánh dấu dữ liệu có cấu trúc (Schema.org, JSON-LD) cho nội dung.
- Thiết kế ưu tiên API (API-first) với đặc tả OpenAPI/GraphQL.
- Tài liệu thân thiện với tác nhân (đọc được bằng máy, không chỉ cho con người).
- Xác thực và giới hạn tần suất (rate limiting) cho truy cập của tác nhân.
- Phân tích sử dụng để hiểu các mẫu hành vi của tác nhân.
Mệnh lệnh chiến lược: Mẫu này thể hiện một sự dịch chuyển căn bản trong cách các tổ chức nghĩ về sự hiện diện số của mình. Cũng như thiết kế ưu tiên di động (mobile-first) trở nên thiết yếu trong kỷ nguyên điện thoại thông minh, thiết kế sẵn sàng cho tác nhân đang trở nên then chốt trong kỷ nguyên AI. Những tổ chức trì hoãn cuộc chuyển đổi này có nguy cơ trở nên vô hình trước các tác nhân sẽ làm trung gian cho những tương tác khách hàng trong tương lai.
Từ các mẫu đến thực hành
Năm mẫu này không loại trừ lẫn nhau — những lần triển khai thành công nhất kết hợp nhiều mẫu. Ví dụ, một tổ chức bán lẻ có thể dùng đồ thị tri thức để kết nối dữ liệu khách hàng và sản phẩm (mẫu 1), luồng sự kiện để giữ dữ liệu đó luôn cập nhật (mẫu 2), một lakehouse để hợp nhất nguồn có cấu trúc và phi cấu trúc (mẫu 3), tìm kiếm ngữ nghĩa cho việc truy xuất của tác nhân (mẫu 4), và API sẵn sàng cho tác nhân để truy cập từ bên ngoài (mẫu 5).
Hiểu biết then chốt là các mẫu này giải quyết sự lệch pha căn bản giữa kiến trúc dữ liệu truyền thống và yêu cầu của GenAI. Các hệ thống truyền thống được tối ưu cho những nhà phân tích con người chạy truy vấn SQL trên dữ liệu có cấu trúc. Các hệ thống GenAI cần hiểu biết ngữ nghĩa, bối cảnh thời gian thực, suy luận liên miền, và truy cập tự chủ — những năng lực đòi hỏi các cách tiếp cận kiến trúc khác biệt về căn bản.
Những tổ chức triển khai thành công các mẫu này thường có chung một số đặc điểm: họ bắt đầu với một mẫu duy nhất gắn với tình huống sử dụng có giá trị cao nhất, chứng minh giá trị nhanh chóng (thường trong ba đến sáu tháng), rồi mở rộng sang các mẫu khác khi năng lực AI của họ trưởng thành. Họ không chờ giải pháp hoàn hảo — họ xây dựng, học hỏi và lặp lại.
Cách tiếp cận lặp này đối với việc triển khai kiến trúc phản ánh một khác biệt sâu xa hơn giữa GenAI và các dự án học máy (ML) truyền thống. Để triển khai thành công các mẫu kiến trúc nêu trên, các tổ chức cũng phải hiểu vòng đời phát triển GenAI khác biệt căn bản như thế nào so với các cách tiếp cận ML truyền thống. Những khác biệt về quy trình này tác động trực tiếp đến việc các mẫu kiến trúc nên được triển khai như thế nào và khi nào.
Vòng đời phát triển: ML so với GenAI
Hiểu được những khác biệt căn bản giữa vòng đời phát triển học máy truyền thống và GenAI là điều thiết yếu đối với các tổ chức muốn vượt khỏi thử nghiệm để tiến tới triển khai vận hành. Những khác biệt này lý giải vì sao các thực hành ML thành công lại thường thất bại khi áp dụng cho các triển khai GenAI.
Vòng đời phát triển học máy truyền thống
Vòng đời phát triển ML truyền thống, thể hiện trong Hình 1-11, đi theo một khuôn mẫu đã được thiết lập vững chắc qua nhiều thập kỷ thực hành.
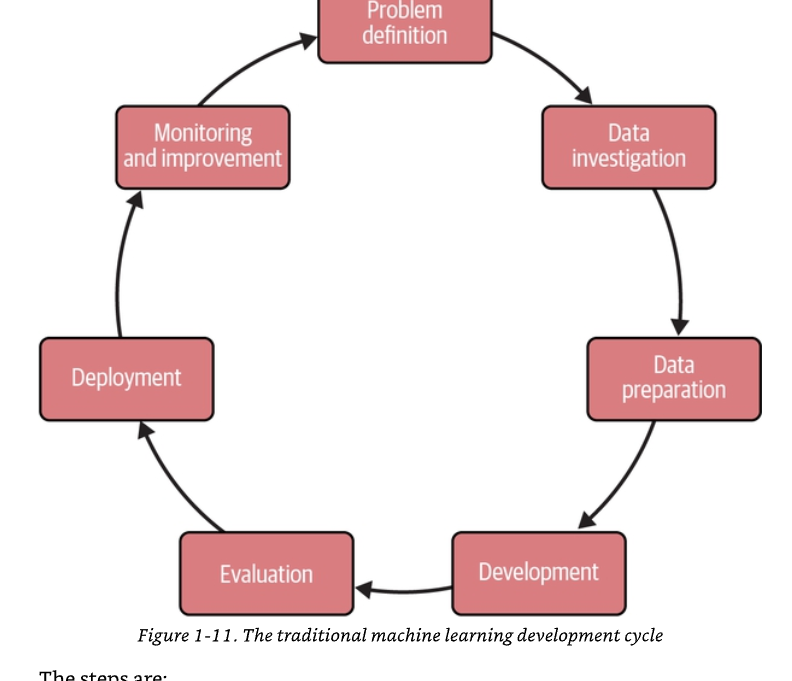
Chú thích Hình 1-11. Vòng đời phát triển học máy truyền thống, gồm các bước theo vòng lặp: định nghĩa bài toán (problem definition) → khảo sát dữ liệu (data investigation) → chuẩn bị dữ liệu (data preparation) → phát triển (development) → đánh giá (evaluation) → triển khai (deployment) → giám sát và cải thiện (monitoring and improvement), rồi quay lại.
[Ghi chú: Hình đã được cắt riêng vùng hình (lưu cục bộ trong assets/); trang nguồn đầy đủ trên Google Drive: https://drive.google.com/file/d/1guZJp-1QYLTuo0wV5TOlKhl2KcjPT1wA/view]
Các bước gồm:
-
Định nghĩa bài toán. Ở giai đoạn đầu này, các đội ngũ diễn đạt rõ ràng thách thức kinh doanh và xác định các kết quả cụ thể, đo lường được. Điều này thiết lập phạm vi và tiêu chí thành công cho toàn bộ dự án. Các yêu cầu then chốt gồm: bài toán kinh doanh được định nghĩa rõ với các chỉ số cụ thể; phạm vi hẹp tập trung vào một tác vụ dự đoán hoặc phân loại duy nhất; định nghĩa tường minh về đầu vào và đầu ra; tiêu chí thành công rõ ràng dựa trên độ chính xác (accuracy), độ chuẩn xác (precision), độ bao phủ (recall), v.v.
-
Khảo sát dữ liệu. Trong giai đoạn khám phá này, các nhà khoa học dữ liệu thăm dò các nguồn dữ liệu sẵn có, hiểu cấu trúc của chúng, và đánh giá chất lượng cùng mức độ liên quan với bài toán đã xác định. Các hoạt động chính gồm: phân tích dữ liệu có cấu trúc từ các hệ thống doanh nghiệp; nhận diện và chọn lọc các đặc trưng (feature) liên quan; thực hiện phân tích thống kê để hiểu phân phối dữ liệu; xác định các tập huấn luyện, kiểm định và kiểm tra.
-
Chuẩn bị dữ liệu. Giai đoạn tiền xử lý then chốt này biến dữ liệu thô thành định dạng phù hợp cho các thuật toán học máy, xử lý các vấn đề chất lượng và tạo các đầu vào được tối ưu. Các hoạt động chính gồm: kỹ thuật đặc trưng (feature engineering) để tạo đầu vào cho mô hình; làm sạch và chuẩn hóa dữ liệu; xử lý giá trị thiếu và ngoại lai (outlier); tạo các tập dữ liệu cân bằng cho huấn luyện.
-
Phát triển. Trong giai đoạn phát triển mô hình, các nhà khoa học dữ liệu chọn và triển khai các thuật toán phù hợp, tinh chỉnh tham số, và cải thiện hiệu năng theo từng vòng lặp dựa trên kết quả kiểm định. Giai đoạn này gồm: lựa chọn thuật toán phù hợp (random forest, gradient boosting, v.v.); tinh chỉnh và tối ưu siêu tham số (hyperparameter); huấn luyện mô hình trên các tập dữ liệu đã gán nhãn; cải thiện theo từng vòng lặp dựa trên kết quả kiểm định.
-
Đánh giá. Giai đoạn đánh giá kiểm thử nghiêm ngặt hiệu năng mô hình dựa trên các chỉ số khách quan, sử dụng dữ liệu giữ riêng (held-out) để bảo đảm độ tin cậy và hiệu quả. Các tác vụ chính gồm: kiểm thử nghiêm ngặt trên dữ liệu kiểm tra giữ riêng; đo lường hiệu năng bằng các chỉ số đã thiết lập; so sánh với các mô hình cơ sở (baseline); kiểm định ý nghĩa thống kê.
-
Triển khai. Trong giai đoạn triển khai, mô hình đã được kiểm định sẽ được chuẩn bị để đưa vào vận hành, tích hợp với các hệ thống hiện có, và lập tài liệu cho các đội vận hành. Các hoạt động chính gồm: tuần tự hóa (serialization) và đóng gói mô hình; tích hợp với hệ thống vận hành; thiết lập suy luận theo lô hoặc thời gian thực; tạo tài liệu và bàn giao cho vận hành.
-
Giám sát và cải thiện. Giai đoạn cuối và diễn ra liên tục này thiết lập các quy trình giám sát liên tục để bảo đảm hiệu năng bền vững và cho phép cải tiến theo từng vòng lặp. Nó gồm: giám sát hiệu năng theo các chỉ số đã thiết lập; phát hiện trôi (drift detection) và huấn luyện lại mô hình; kiểm thử A/B cho các cải tiến mô hình; thiết lập các vòng phản hồi cho cải tiến liên tục.
Vòng đời truyền thống này phù hợp với các tác vụ dự đoán và phân loại có đầu vào và đầu ra được định nghĩa rõ. Nó phụ thuộc nhiều vào dữ liệu có cấu trúc và kỹ thuật đặc trưng tường minh, với thành công được đo bằng các chỉ số hiệu năng khách quan. Quá trình này vốn mang tính lặp, với những hiểu biết từ khâu giám sát và cải thiện được đưa ngược về khâu định nghĩa bài toán để thúc đẩy tinh chỉnh liên tục.
Vòng đời phát triển GenAI
Ngược lại, vòng đời phát triển GenAI, thể hiện trong Hình 1-12, đưa ra những khuôn mẫu và yêu cầu khác biệt về căn bản.
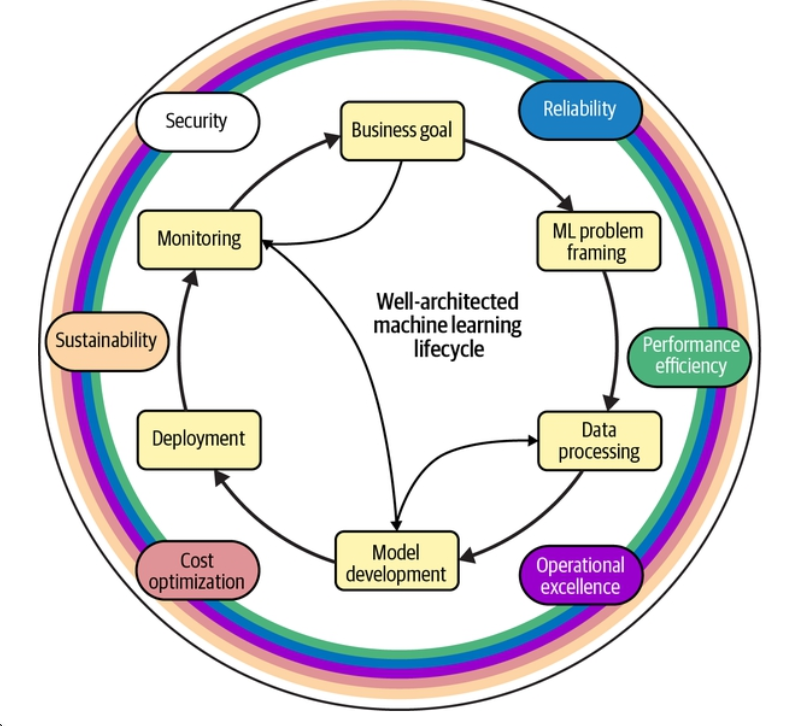
Chú thích Hình 1-12. Vòng đời phát triển AI tạo sinh, được mô tả như một "vòng đời học máy được kiến trúc tốt" (well-architected machine learning lifecycle) xoay quanh mục tiêu kinh doanh (business goal): khung định hình bài toán ML (ML problem framing) → xử lý dữ liệu (data processing) → phát triển mô hình (model development) → triển khai (deployment) → giám sát (monitoring), với các trụ cột bao quanh: độ tin cậy (reliability), bảo mật (security), tối ưu chi phí (cost optimization), hiệu quả vận hành (operational excellence), hiệu năng (performance efficiency), tính bền vững (sustainability).
[Ghi chú: Hình đã được cắt riêng vùng hình (lưu cục bộ trong assets/); trang nguồn đầy đủ trên Google Drive: https://drive.google.com/file/d/1LAm5ZV1IWOIzcmzuzUawS6KzknsCd8wh/view]
Vòng đời này cũng có thể chia thành bảy giai đoạn:
-
Định nghĩa tình huống sử dụng và lựa chọn mô hình. Giai đoạn đầu tiên này tập trung vào việc xác định các mục tiêu rộng hơn (ví dụ "cải thiện dịch vụ khách hàng") và lựa chọn các mô hình nền tảng phù hợp (GPT, Claude, Llama, v.v.) khớp với yêu cầu của tình huống sử dụng và các ràng buộc của tổ chức. Các tác vụ bổ sung gồm: cân nhắc năng lực, giới hạn và thiên kiến (bias) của mô hình; đánh giá các phương án lưu trữ (dịch vụ API so với tự lưu trữ); định nghĩa tiêu chí thành công vượt ra ngoài các chỉ số truyền thống.
-
Tích hợp tri thức và kỹ thuật bối cảnh. Giai đoạn đặc thù của GenAI này liên quan đến việc kết nối các nguồn tri thức doanh nghiệp với mô hình nền tảng, bảo đảm thông tin liên quan được biểu diễn và truy cập đúng cách. Đây là nơi năm mẫu kiến trúc được mô tả trong "Những gì các tổ chức dẫn đầu đang xây dựng hôm nay" trở nên then chốt. Các tác vụ chính gồm: nhận diện các nguồn tri thức doanh nghiệp; phát triển các chiến lược xử lý tài liệu và chia nhỏ (chunking); tạo vector nhúng và lựa chọn cơ sở dữ liệu vector; làm giàu siêu dữ liệu và thiết kế chiến lược truy xuất; tích hợp các nguồn dữ liệu có cấu trúc và phi cấu trúc.
-
Kỹ thuật câu lệnh và thiết kế hệ thống. Giai đoạn thiết kế then chốt này tập trung vào việc tạo ra các chỉ dẫn hiệu quả cho mô hình và thiết lập các khung để bảo đảm phản hồi và rào chắn phù hợp. Nó gồm: thiết kế các câu lệnh và chỉ dẫn hệ thống hiệu quả; tạo các ví dụ few-shot và mẫu (template); phát triển các cơ chế đánh giá và lọc; tích hợp với công cụ và API bên ngoài; triển khai các rào chắn (guardrail) và biện pháp an toàn.
-
Tinh chỉnh và tùy biến (tùy chọn). Trong giai đoạn tùy chọn nhưng mạnh mẽ này, các mô hình nền tảng được điều chỉnh cho các lĩnh vực hoặc tác vụ cụ thể thông qua huấn luyện chuyên biệt bổ sung. Nó bao gồm: tạo các tập dữ liệu tinh chỉnh; lựa chọn các kỹ thuật tinh chỉnh phù hợp; sử dụng các phương pháp tinh chỉnh tiết kiệm tham số (LoRA, QLoRA); đánh giá hiệu năng của mô hình đã tinh chỉnh; phân tích đánh đổi giữa cách tiếp cận tinh chỉnh và RAG.
-
Đánh giá và căn chỉnh (alignment). Giai đoạn này kết hợp cả các chỉ số khách quan lẫn đánh giá của con người để bảo đảm đầu ra đáp ứng các tiêu chuẩn về chất lượng, an toàn và căn chỉnh trên nhiều kịch bản đa dạng. Nó gồm: con người đánh giá đầu ra về chất lượng và mức độ liên quan; "đội đỏ" (red teaming) để tìm lỗ hổng an toàn và bảo mật; bảo đảm căn chỉnh với các giá trị và hướng dẫn của tổ chức; kiểm thử trên các kịch bản đa dạng và trường hợp biên; đánh giá tỷ lệ bịa đặt (hallucination) và độ chính xác thực tế.
-
Triển khai và tích hợp. Giai đoạn triển khai tập trung vào việc tích hợp hệ thống GenAI với các quy trình làm việc hiện có, đồng thời thiết lập giám sát, cơ chế phản hồi và đào tạo người dùng phù hợp. Các tác vụ chính gồm: tích hợp với các quy trình và hệ thống hiện có; triển khai giám sát và ghi nhật ký (logging); thiết lập các cơ chế thu thập phản hồi; đào tạo người dùng và quản lý thay đổi; triển khai các kiểm soát quản trị và tuân thủ.
-
Học hỏi và cải thiện liên tục. Giai đoạn diễn ra liên tục này nhấn mạnh bản chất động của các hệ thống GenAI, với việc thu thập phản hồi liên tục và cập nhật thường xuyên cả hệ thống lẫn các cơ sở tri thức của nó. Nó gồm: thu thập và phân tích phản hồi người dùng; giám sát hiệu năng mô hình và các mẫu sử dụng; nhận diện các kiểu lỗi (failure mode) và trường hợp biên; cập nhật thường xuyên các cơ sở tri thức và bối cảnh; thích ứng với nhu cầu và kỳ vọng đang thay đổi của người dùng.
Bảng 1-3 tóm tắt những khác biệt mang tính cấu trúc giữa vòng đời phát triển ML truyền thống và GenAI.
Bảng 1-3. Những khác biệt then chốt giữa vòng đời phát triển ML và GenAI
| Khía cạnh | Vòng đời ML truyền thống | Vòng đời phát triển GenAI |
|---|---|---|
| Phạm vi bài toán | Tác vụ dự đoán hẹp, được định nghĩa rõ | Tác vụ tạo sinh và suy luận rộng, mở |
| Yêu cầu dữ liệu | Tập dữ liệu có cấu trúc, đã gán nhãn | Nguồn tri thức đa dạng, cả có cấu trúc lẫn phi cấu trúc |
| Phát triển mô hình | Mô hình tùy chỉnh xây từ đầu | Điều chỉnh các mô hình nền tảng đã huấn luyện trước |
| Trọng tâm kỹ thuật | Kỹ thuật đặc trưng | Kỹ thuật bối cảnh và thiết kế câu lệnh |
| Phương pháp đánh giá | Chỉ số khách quan (accuracy, F1, v.v.) | Đánh giá chủ quan và đánh giá của con người |
| Mẫu triển khai | Triển khai mô hình tĩnh với huấn luyện lại định kỳ | Hệ thống động với cập nhật tri thức liên tục |
| Tiêu chí thành công | Chỉ số hiệu năng định lượng | Sự hài lòng của người dùng và giá trị kinh doanh |
| Kiểu lỗi | Suy giảm hiệu năng từ từ | Lỗi nghiêm trọng (bịa đặt, đầu ra gây hại) |
| Nhu cầu quản trị | Tài liệu hóa và giám sát mô hình | Kiểm soát toàn diện về an toàn, đạo đức và căn chỉnh |
Hệ quả đối với hạ tầng dữ liệu
Những khác biệt về vòng đời phát triển nêu trong Bảng 1-3 tác động trực tiếp đến các yêu cầu hạ tầng dữ liệu, tạo ra những thách thức căn bản cho các tổ chức muốn tận dụng các khoản đầu tư ML hiện có cho ứng dụng GenAI. Năm mẫu kiến trúc đã xem xét ở trên giải quyết những hệ quả này:
Quản lý tri thức so với kho đặc trưng (feature store) : ML truyền thống dựa vào các kho đặc trưng với những đặc trưng có cấu trúc, đã được thiết kế, trong khi GenAI đòi hỏi các hệ thống quản lý tri thức toàn diện giúp duy trì bối cảnh và quan hệ. Một công ty viễn thông phát hiện những đặc trưng được thiết kế kỹ lưỡng của họ (như "thời lượng cuộc gọi trung bình") lại không phù hợp cho trợ lý dịch vụ khách hàng GenAI — các đặc trưng đó đã tước đi sự phong phú về bối cảnh cần thiết cho những phản hồi hữu ích. Giải pháp: Đồ thị tri thức (mẫu 1) gìn giữ các quan hệ và bối cảnh mà kho đặc trưng loại bỏ.
Truy cập dữ liệu tĩnh so với động : Các mô hình ML truy cập những tập dữ liệu tĩnh chỉ thay đổi trong những lần huấn luyện lại định kỳ, nhưng GenAI cần nhận thức theo thời gian thực. Hệ thống GenAI của một ngân hàng toàn cầu tiếp tục cung cấp thông tin chính sách lỗi thời trong nhiều tuần sau một bản cập nhật quy định, tạo ra rủi ro tuân thủ. Giải pháp: Kiến trúc hướng sự kiện (mẫu 2) bảo đảm các tác nhân luôn làm việc với thông tin hiện hành.
Xử lý theo lô so với tương tác : Các quy trình ML tối ưu cho thông lượng thông qua xử lý theo lô, nhưng GenAI đòi hỏi xử lý tương tác với độ trễ thấp. Đường ống dữ liệu chạy qua đêm của một công ty sản xuất không thể hỗ trợ trợ lý bảo trì GenAI vốn cần thời gian phản hồi dưới một giây. Giải pháp: Kiến trúc lakehouse (mẫu 3) hỗ trợ cả phân tích theo lô lẫn khối lượng công việc AI tương tác.
Lưu trữ có cấu trúc so với theo bối cảnh : Dữ liệu ML truyền thống được tối ưu cho lưu trữ dạng bảng, nhưng GenAI đòi hỏi thông tin phi cấu trúc, giàu bối cảnh. Hệ thống của một nhà cung cấp dịch vụ y tế lưu các mã chẩn đoán nhưng không thể duy trì bối cảnh tường thuật của lịch sử bệnh nhân. Giải pháp: Tìm kiếm ngữ nghĩa (mẫu 4) cho phép truy xuất dựa trên ý nghĩa, không chỉ dựa trên cấu trúc.
Cải thiện theo chỉ số so với theo phản hồi : Các hệ thống ML cải thiện thông qua tối ưu chỉ số, nhưng GenAI tiến hóa thông qua phản hồi liên tục của người dùng và học hỏi liên tục. Hệ thống gợi ý của một tổ chức bán lẻ cải thiện dựa trên các chỉ số chuyển đổi, nhưng trợ lý mua sắm GenAI của họ cần tiếp nhận phản hồi chủ quan và liên tục cập nhật tri thức về sản phẩm. Giải pháp: Các kiến trúc sẵn sàng cho tác nhân (mẫu 5) bao gồm các vòng phản hồi và cơ chế học hỏi liên tục.
Tiến hóa kiến trúc trong thực tế: Từ ETL truyền thống đến đường ống sẵn sàng cho GenAI
Để thực sự mở khóa tiềm năng biến đổi của GenAI, các doanh nghiệp phải tiến hóa vượt ra ngoài các mô hình AI/ML và dữ liệu lớn truyền thống thể hiện trong Hình 1-13 và 1-14. AI tạo sinh đòi hỏi một cách tiếp cận hoàn toàn mới về việc dữ liệu được lưu trữ, xử lý, truy xuất và quản trị như thế nào. Mở khóa toàn bộ tiềm năng của nó đòi hỏi một sự thay đổi trong tư duy — từ các đường ống có cấu trúc, định hướng theo lô sang các kiến trúc linh hoạt, thời gian thực, nhận biết bối cảnh, được thiết kế cho nội dung phi cấu trúc và động.
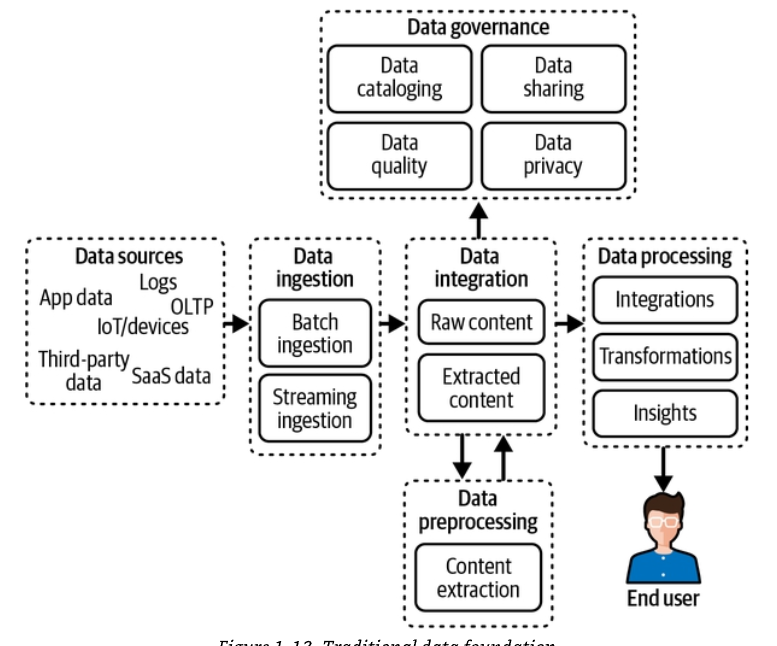
Chú thích Hình 1-13. Nền tảng dữ liệu truyền thống. Sơ đồ: nguồn dữ liệu (dữ liệu ứng dụng, nhật ký, OLTP, IoT, bên thứ ba, SaaS) → nạp dữ liệu (batch/streaming) → tích hợp dữ liệu (integrations, transformations, trích xuất nội dung) → xử lý dữ liệu → ứng dụng AI (Generative AI, Agentic AI, insight, end user), với các lớp quản trị bao quanh (chất lượng, lập danh mục, quản trị, chia sẻ, quyền riêng tư).
[Ghi chú: Hình đã được cắt riêng vùng hình (lưu cục bộ trong assets/); trang nguồn đầy đủ trên Google Drive (trang này chứa cả Hình 1-13 và 1-14): https://drive.google.com/file/d/1HyXPG2DdeRH8aO6K6oGUuyACWPajyqHm/view]
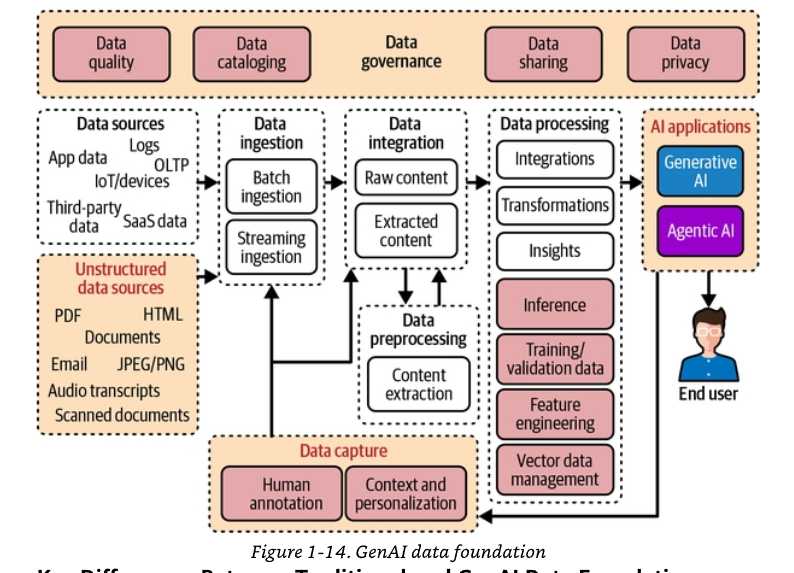
Chú thích Hình 1-14. Nền tảng dữ liệu GenAI. So với Hình 1-13, mô hình này bổ sung các nguồn dữ liệu phi cấu trúc (PDF, HTML, tài liệu, email, JPEG/PNG, bản ghi âm, tài liệu quét) và mở rộng khâu tiền xử lý dữ liệu (trích xuất nội dung, kỹ thuật đặc trưng, dữ liệu huấn luyện/kiểm định, thu thập dữ liệu, chú thích của con người, quản lý dữ liệu vector, bối cảnh và cá nhân hóa) để phục vụ suy luận và các ứng dụng GenAI/Agentic AI.
[Ghi chú: Hình đã được cắt riêng vùng hình (lưu cục bộ trong assets/); trang nguồn đầy đủ trên Google Drive (cùng trang nguồn với Hình 1-13): https://drive.google.com/file/d/1rD7JT8xpdAkLzrAt0nA66_Tct0CguJGU/view]
Những khác biệt then chốt giữa nền tảng dữ liệu truyền thống và GenAI
Trước khi đi vào một ví dụ thực tế, hãy điểm nhanh những khác biệt then chốt. Bảng 1-4 cung cấp một cái nhìn tổng quan.
Bảng 1-4. Những khác biệt then chốt giữa nền tảng dữ liệu truyền thống và GenAI
| Khía cạnh | Nền tảng dữ liệu truyền thống | Nền tảng dữ liệu GenAI |
|---|---|---|
| Loại dữ liệu | Chủ yếu có cấu trúc, một phần phi cấu trúc | Chủ yếu phi cấu trúc với quan hệ phức tạp |
| Yêu cầu lược đồ (schema) | Cần lược đồ cứng nhắc | Linh hoạt về lược đồ, nhấn mạnh vector nhúng |
| Yêu cầu bối cảnh | Bối cảnh hạn chế, thường xử lý từng bản ghi đơn lẻ | Quan hệ bối cảnh phong phú xuyên các nguồn dữ liệu |
| Trọng tâm quản trị | Kiểm soát truy cập và tuân thủ | Đạo đức, phát hiện thiên kiến, và sử dụng có trách nhiệm |
| Mẫu truy vấn | Truy vấn có thể dự đoán, tường minh | Truy xuất theo ngữ nghĩa, dựa trên tương đồng, nhận biết bối cảnh |
| Phương pháp truy xuất | Khớp chính xác, dựa trên từ khóa | Dựa trên tương đồng, hiểu biết ngữ nghĩa |
| Chế độ xử lý | Chủ yếu theo lô, một phần streaming | Thời gian thực, tương tác, với cửa sổ ngữ cảnh động |
| Chiều mở rộng quy mô | Khối lượng (hàng petabyte dữ liệu có cấu trúc) | Bối cảnh (duy trì quan hệ ở quy mô lớn) |
| Mô hình lưu trữ | Định hướng bảng (hàng/cột) | Dựa trên vector với quan hệ ngữ nghĩa |
| Tần suất cập nhật | Làm mới định kỳ | Tích hợp liên tục các tri thức mới |
Ví dụ thực tế: Tiến hóa từ Kimball đến kiến trúc Medallion rồi đến kiến trúc sẵn sàng cho GenAI
Các tổ chức đang triển khai trong thực tế cuộc tiến hóa kiến trúc cần thiết cho thành công GenAI như thế nào? Hãy xem xét một nghiên cứu tình huống cụ thể minh họa cho cuộc chuyển đổi này.
Thách thức: các bảng dữ kiện (fact table) hàng tỷ dòng trong kỷ nguyên GenAI
Một nhà bán lẻ toàn cầu với lịch sử giao dịch vượt 3 tỷ dòng đang di chuyển từ lược đồ hình sao (star schema) Kimball truyền thống sang kiến trúc medallion với các lớp dữ liệu đồng (bronze — thô), bạc (silver — đã làm sạch và chuẩn hóa) và vàng (gold — đã tuyển chọn), như minh họa trong Hình 1-15, đồng thời xây dựng những ứng dụng GenAI đầu tiên của mình.
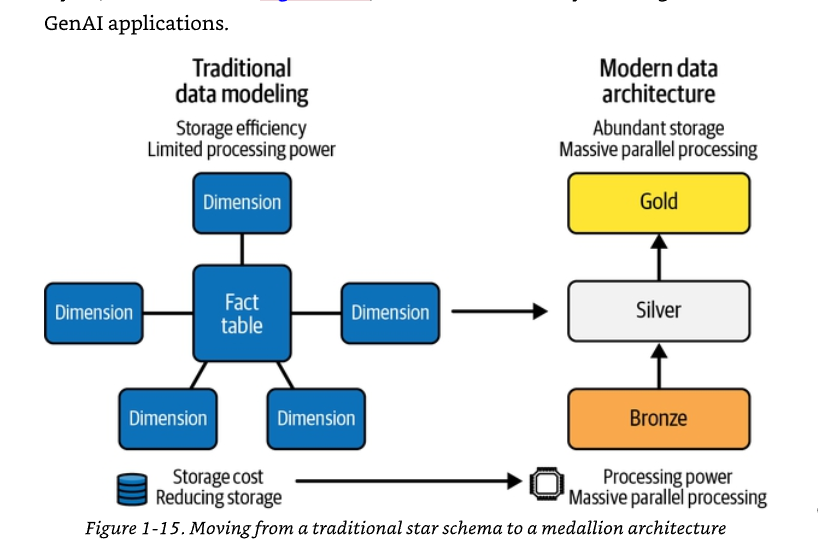
Chú thích Hình 1-15. Chuyển từ lược đồ hình sao (star schema) truyền thống sang kiến trúc medallion. Bên trái — mô hình hóa dữ liệu truyền thống (đề cao hiệu quả lưu trữ, năng lực xử lý hạn chế) với bảng dữ kiện (fact table) và các bảng chiều (dimension). Bên phải — kiến trúc dữ liệu hiện đại (modern data architecture) với lưu trữ dồi dào và xử lý song song quy mô lớn, gồm ba lớp: bronze, silver, gold.
[Ghi chú: Hình đã được cắt riêng vùng hình (lưu cục bộ trong assets/); trang nguồn đầy đủ trên Google Drive (trang chứa Hình 1-15 và đoạn mã SQL mô hình chiều): https://drive.google.com/file/d/15caGMpuUZUhft6x92x5lUfqLWn4lzC5M/view]
Mô hình hiện có trông như sau:
-- Mô hình chiều truyền thống với các bảng fact và dimension riêng biệt
CREATE TABLE gold.fact_sales (
transaction_id BIGINT,
date_key INT,
product_key INT,
store_key INT,
customer_key INT,
quantity INT,
amount DECIMAL(12,2)
);
CREATE TABLE gold.dim_product (
product_key INT,
product_id VARCHAR(50),
product_name VARCHAR(100),
category VARCHAR(50),
subcategory VARCHAR(50),
brand VARCHAR(50)
);
CREATE TABLE gold.dim_store (
store_key INT,
store_id VARCHAR(20),
store_name VARCHAR(100),
region_id VARCHAR(10),
city VARCHAR(50),
state VARCHAR(2)
);
Cách tiếp cận truyền thống này, dù hiệu quả cho báo cáo lịch sử, lại đặt ra một số thách thức cho các ứng dụng GenAI:
- Mô tả và chi tiết sản phẩm bị giới hạn trong các trường có cấu trúc.
- Không có sự hiểu biết ngữ nghĩa về quan hệ giữa các sản phẩm.
- Không hỗ trợ truy vấn ngôn ngữ tự nhiên về sản phẩm.
- Không hỗ trợ dữ liệu hình ảnh hay nội dung phong phú.
- Cập nhật theo lô, dễ dẫn đến dữ liệu lỗi thời.
Giải pháp: cách tiếp cận lai (hybrid) để sẵn sàng cho GenAI
Tổ chức này đã triển khai một cách tiếp cận lai vừa gìn giữ các tài sản chiều cốt lõi — bảo đảm các định nghĩa nghiệp vụ nhất quán trên toàn doanh nghiệp — vừa tạo ra các cấu trúc dữ liệu được tối ưu cho GenAI:
- Các bảng dữ kiện được phi chuẩn hóa (denormalized), xây dựng theo mục đích, gắn với các miền nghiệp vụ cụ thể.
- Các thiết kế được tối ưu cho cả phân tích của con người lẫn việc tiêu thụ bởi AI.
Cho phần triển khai của mình, họ tạo ra hai loại tài sản lớp gold:
-- Đối với dữ liệu trong giới hạn SPICE (< 1 tỷ dòng)
CREATE TABLE gold.daily_aggregated AS
SELECT
date_key,
region_id,
SUM(amount) as daily_total,
COUNT(DISTINCT customer_id) as customer_count
FROM silver.transactions
GROUP BY 1,2,3;
-- Đối với dữ liệu chi tiết vượt giới hạn SPICE
-- Dùng chế độ truy vấn trực tiếp (direct query)
CREATE VIEW gold.transaction_details AS
SELECT * FROM silver.transactions;
Để làm phẳng (flatten) dữ liệu cho việc tiêu thụ bởi AI, họ tạo các khung nhìn (view) phi chuẩn hóa dành riêng cho các ứng dụng GenAI:
CREATE TABLE gold.store_performance AS
SELECT
t.transaction_id, t.transaction_date, t.amount,
p.product_name, p.category, p.subcategory, p.product_category,
s.store_name, s.region_id, s.city, s.state
FROM silver.transactions t
JOIN silver.products p ON t.product_id = p.product_id
JOIN silver.stores s ON t.store_id = s.store_id;
Kiến trúc đường ống dữ liệu được tăng cường cho GenAI
Để hỗ trợ các ứng dụng GenAI, tổ chức đã triển khai một đường ống dữ liệu toàn diện vượt ra ngoài ETL truyền thống. Đường ống này hiện thực hóa cả năm mẫu đã giới thiệu trước đó:
# Mã Python cho một đường ống dữ liệu bán lẻ sẵn sàng cho GenAI
# 1. Trích xuất dữ liệu sản phẩm và giao dịch toàn diện
def extract_retail_data():
# Trích xuất dữ liệu có cấu trúc từ các nguồn truyền thống
structured_data = extract_from_database("SELECT * FROM source.products")
# Trích xuất dữ liệu phi cấu trúc từ nhiều nguồn
product_descriptions = extract_from_cms("product_descriptions")
product_images = extract_from_asset_manager("product_images")
customer_reviews = extract_from_reviews_system("customer_reviews")
social_media_mentions = extract_from_social_platforms("brand_mentions")
return {
"structured": structured_data,
"descriptions": product_descriptions,
"images": product_images,
"reviews": customer_reviews,
"social": social_media_mentions
}
# 2. Xử lý và làm giàu dữ liệu cho việc tiêu thụ bởi GenAI
def process_for_genai(raw_data):
# Xử lý dữ liệu có cấu trúc
products_df = process_structured_data(raw_data["structured"])
# Tạo vector nhúng văn bản cho mô tả sản phẩm (Mẫu 4: Tìm kiếm ngữ nghĩa)
description_embeddings = generate_embeddings(
raw_data["descriptions"],
model="text-embedding-ada-002"
)
# Trích đặc trưng từ hình ảnh sản phẩm (Mẫu 3: Lakehouse đa phương thức)
image_features = process_images_with_vision_model(raw_data["images"])
# Phân tích cảm xúc và trích chủ đề từ đánh giá
review_insights = analyze_reviews_with_nlp(raw_data["reviews"])
# Xử lý mạng xã hội để đo cảm xúc về thương hiệu
social_sentiment = analyze_social_sentiment(raw_data["social"])
# Tạo vector nhúng sản phẩm hợp nhất
unified_embeddings = create_multimodal_embeddings(
text=description_embeddings,
images=image_features,
reviews=review_insights,
social=social_sentiment
)
return {
"structured_data": products_df,
"embeddings": unified_embeddings,
"metadata": extract_metadata(raw_data),
"relationships": identify_product_relationships(products_df, unified_embeddings)
}
# 3. Lưu trữ trong kiến trúc lai được tối ưu cho GenAI
def store_genai_data(processed_data):
# Lưu dữ liệu có cấu trúc trong warehouse truyền thống (cho báo cáo)
store_in_warehouse(processed_data["structured_data"])
# Lưu vector nhúng trong cơ sở dữ liệu vector (Mẫu 4: Tìm kiếm ngữ nghĩa)
store_in_vector_db(
embeddings=processed_data["embeddings"],
metadata=processed_data["metadata"]
)
# Lưu quan hệ trong cơ sở dữ liệu đồ thị (Mẫu 1: Đồ thị tri thức)
store_in_graph_db(processed_data["relationships"])
# Cập nhật chỉ mục tìm kiếm thời gian thực cho các ứng dụng AI
update_search_index(processed_data)
# Tạo đồ thị tri thức cho suy luận phức tạp (Mẫu 1)
update_knowledge_graph(processed_data["relationships"])
# 4. Triển khai cập nhật thời gian thực cho các ứng dụng GenAI
def setup_realtime_genai_pipeline():
# Thiết lập trình lắng nghe sự kiện cho cập nhật sản phẩm (Mẫu 2: Hướng sự kiện)
setup_event_listeners([
"product_updates",
"inventory_changes",
"price_updates",
"new_reviews",
"social_mentions"
])
# Triển khai nắm bắt thay đổi dữ liệu cho dữ liệu có cấu trúc (Mẫu 2)
setup_cdc_pipeline()
# Theo dõi hệ thống quản lý nội dung để phát hiện cập nhật mô tả
monitor_cms_changes()
[Ghi chú OCR: Đoạn mã Python ở trên được phục dựng từ OCR của ảnh trang sách; một số ký tự (dấu ngoặc, dấu bằng, dấu phẩy) trong ảnh gốc bị nhòe nên đã được biên tập lại cho đúng cú pháp Python. Vui lòng đối chiếu với mã gốc trong sách nếu cần chính xác tuyệt đối.]
Kết quả và lợi ích
Khi sau đó họ triển khai một trợ lý AI để trả lời các câu hỏi nghiệp vụ, cách tiếp cận lai này tỏ ra vô cùng giá trị:
- AI có thể truy cập hiệu quả dữ liệu chuyên biệt theo miền trong khi vẫn duy trì các định nghĩa nhất quán trên toàn doanh nghiệp.
- Những truy vấn ngôn ngữ tự nhiên như "Cho tôi xem các sản phẩm tương tự áo khoác mùa đông bán chạy nhất của chúng ta" trở nên khả thi nhờ tìm kiếm ngữ nghĩa (mẫu 4).
- Bối cảnh tồn kho thời gian thực cho phép AI cung cấp thông tin tình trạng còn hàng chính xác (mẫu 2).
- Những hiểu biết liên miền nảy sinh từ việc kết nối dữ liệu sản phẩm với đánh giá của khách hàng và cảm xúc trên mạng xã hội (mẫu 1).
Ví dụ, khi một quản lý cửa hàng hỏi trợ lý AI "Doanh số hôm nay thấp hơn dự báo 15%, tôi nên làm gì?", hệ thống có thể đáp lại: "Mẫu hình doanh số hôm nay tương tự những gì ta thấy quý trước trong đợt gián đoạn chuỗi cung ứng. Dựa trên dữ liệu lịch sử, việc khuyến mãi các sản phẩm bổ trợ trong nhóm X và Y thường giúp phục hồi 8–12% phần thiếu hụt. Mức tồn kho hiện tại đủ để hỗ trợ chiến lược này."
Các chiến lược mở rộng quy mô cho kỷ nguyên AI
Khi khối lượng dữ liệu của nhà bán lẻ tăng từ hàng tỷ lên hàng nghìn tỷ dòng, họ đã triển khai một số chiến lược để duy trì hiệu năng:
Mô hình hóa theo miền (domain-driven modeling) : Tạo các tập dữ liệu gold riêng cho các đội bán hàng (merchandising), vận hành cửa hàng và tài chính (mẫu 1, tiến hóa data mesh).
Phân vùng có cân nhắc (thoughtful partitioning) : Phân vùng dữ liệu giao dịch theo ngày và theo khu vực (mẫu 3).
Các lớp tổng hợp (aggregation layers) : Xây các bản tổng hợp theo ngày, tuần và tháng cho những truy vấn phổ biến.
Làm giàu siêu dữ liệu (metadata enrichment) : Thêm mô tả nghiệp vụ rõ ràng cho tất cả các trường (mẫu 5).
Tối ưu vector (vector optimization) : Triển khai các chỉ mục vector phân cấp để tìm kiếm tương đồng nhanh hơn (mẫu 4).
Chiến lược bộ nhớ đệm (caching strategies) : Triển khai bộ nhớ đệm thông minh cho các vector nhúng được truy cập thường xuyên (mẫu 2).
Vì sao điều này quan trọng: Nền tảng dữ liệu cho thành công của AI
Cách tiếp cận này làm cho logic nghiệp vụ của tổ chức trở nên dễ tiếp cận đối với cả các công cụ trí tuệ kinh doanh (business intelligence — BI) truyền thống lẫn các ứng dụng GenAI. Sự minh bạch khi đặt các phép tính trong lớp biến đổi dữ liệu thay vì trong các thủ tục (procedure) của cơ sở dữ liệu đã cải thiện việc lập tài liệu và cuối cùng là độ chính xác của các bảng điều khiển (dashboard) cũng như các insight do AI tạo ra.
Bằng cách chuyển logic nghiệp vụ phức tạp từ những thủ tục mờ đục sang các phép biến đổi minh bạch trong lớp gold, họ đã tạo ra một nguồn chân lý duy nhất (single source of truth) mà cả công cụ trực quan hóa lẫn các mô hình AI đều có thể tận dụng một cách nhất quán.
Khi việc triển khai GenAI của nhà bán lẻ mở rộng, họ phát hiện rằng các quyết định về kiến trúc dữ liệu của mình có những hệ quả sâu rộng:
- Chất lượng dữ liệu trở nên tối quan trọng. Các hệ thống AI khuếch đại mọi điểm thiếu nhất quán hay sai sót trong dữ liệu.
- Việc gìn giữ bối cảnh là then chốt. Duy trì quan hệ giữa các phần tử dữ liệu cho phép AI suy luận tinh vi hơn (mẫu 1).
- Cập nhật thời gian thực là thiết yếu. Dữ liệu lỗi thời dẫn đến những phản hồi AI lạc hậu, làm xói mòn niềm tin của người dùng (mẫu 2).
- Sự phong phú của siêu dữ liệu giúp AI hoạt động tốt hơn. Dữ liệu được lập tài liệu kỹ giúp các hệ thống AI cung cấp phản hồi chính xác và phù hợp hơn (mẫu 5).
Cuộc tiến hóa từ mô hình hóa chiều Kimball truyền thống đến kiến trúc sẵn sàng cho GenAI này minh chứng cho những bước thực tế mà các tổ chức phải thực hiện để bắc cầu nối khoảng cách giữa các ứng dụng AI thử nghiệm và các hệ thống sẵn sàng vận hành mang lại giá trị kinh doanh thực sự. Quan trọng hơn, nó cho thấy năm mẫu kiến trúc được giới thiệu trong chương này phối hợp với nhau trong thực tế như thế nào để tạo nên một nền tảng dữ liệu GenAI toàn diện.
Chuẩn bị cho tương lai do tác nhân dẫn dắt
Mặc dù các cách tiếp cận triển khai đã bàn tới nay giải quyết những nhu cầu hiện tại của GenAI, khi nhìn vượt ra ngoài những triển khai GenAI của hôm nay để hướng tới một tương lai ngày càng được định hình bởi các tác nhân AI tự chủ, các tổ chức phải chuẩn bị hạ tầng dữ liệu của mình cho những dịch chuyển căn bản hơn trong cách thông tin được truy cập, xử lý và hành động. Phần này khám phá những xu hướng then chốt sẽ định hình mức độ sẵn sàng dữ liệu trong một thế giới do tác nhân dẫn dắt, đồng thời đưa ra định hướng cho các tổ chức muốn tạo lợi thế cho mình trong bối cảnh mới đang hình thành này. Một lần nữa, năm mẫu kiến trúc đã trình bày có thể hỗ trợ việc điều hướng quá trình chuyển đổi đó.
"Jeeves đi mua sắm": Trải nghiệm tiêu dùng qua trung gian tác nhân
Một trong những kịch bản mang tính biến đổi sâu sắc nhất nảy sinh từ AI tác nhân là điều ta có thể gọi là mô hình "Jeeves đi mua sắm" (Jeeves does the shopping) — trong đó các tác nhân AI đóng vai trung gian giữa người tiêu dùng và doanh nghiệp, thay đổi tận gốc cách sản phẩm và dịch vụ được khám phá, đánh giá và mua sắm.
Trong kịch bản này:
- Người tiêu dùng ủy thác quyết định mua sắm cho các tác nhân AI vốn hiểu rõ sở thích, giới hạn ngân sách và nhu cầu của họ.
- Tác nhân thương lượng trực tiếp với doanh nghiệp thay cho người tiêu dùng, so sánh các lựa chọn giữa nhiều nhà cung cấp.
- Tiếp thị truyền thống trở nên kém hiệu quả khi tác nhân lọc bỏ nội dung quảng cáo dựa trên các tiêu chí khách quan.
- Thuộc tính của sản phẩm và dịch vụ trở thành những yêu cầu máy đọc được (machine-readable) thay vì những lời chào mời cảm tính.
- Tính minh bạch về giá tăng vọt, vì tác nhân có thể so sánh tức thì các lựa chọn giữa các nhà cung cấp.
Đối với các tổ chức, đặc biệt trong lĩnh vực bán lẻ và dịch vụ tiêu dùng, sự dịch chuyển này đòi hỏi phải suy nghĩ lại căn bản về mức độ sẵn sàng dữ liệu trên nhiều phương diện:
- Thông tin sản phẩm: Mọi thuộc tính sản phẩm phải được cấu trúc ở định dạng máy đọc được để tác nhân có thể phân tích và so sánh (mẫu 5).
- Mô hình định giá: Các hệ thống định giá động phải được thiết kế để tương tác với tác nhân AI thông qua các giao diện chuẩn hóa (mẫu 5).
- Hệ thống tồn kho: Dữ liệu tồn kho thời gian thực phải sẵn sàng cho tác nhân nhằm ngăn ngừa thất bại trong khâu giao hàng (mẫu 2).
- Thỏa thuận mức dịch vụ (SLA): Các cam kết về hiệu năng phải được hình thức hóa theo cách mà tác nhân có thể kiểm chứng và buộc thực thi (mẫu 5).
Tối ưu hóa công cụ tìm kiếm: Từ từ khóa đến tối ưu hóa cho tác nhân
Khi các tác nhân AI ngày càng làm trung gian cho việc khám phá thông tin và ra quyết định, tối ưu hóa công cụ tìm kiếm (search engine optimization — SEO) truyền thống sẽ tiến hóa thành một bộ môn mới mà ta có thể gọi là tối ưu hóa cho tác nhân (agent optimization — AO).
Sự chuyển đổi này thay đổi tận gốc cách các tổ chức phải cấu trúc dữ liệu để có thể được khám phá và phù hợp, như minh họa trong Bảng 1-5.
Bảng 1-5. SEO truyền thống so với tối ưu hóa cho tác nhân
| SEO truyền thống | Tối ưu hóa cho tác nhân (AO) |
|---|---|
| Tối ưu hóa từ khóa | Tối ưu hóa dữ liệu có cấu trúc |
| Nội dung dễ đọc cho con người | Chuẩn hóa thuộc tính máy đọc được |
| Uy tín từ liên kết ngược (backlink) | Chứng chỉ tin cậy có thể kiểm chứng |
| Các chỉ số tương tác người dùng | Các chỉ số hiệu năng khách quan |
| Lời chào mời cảm tính | Đề xuất giá trị định lượng được |
Sự dịch chuyển này đòi hỏi các tổ chức phải:
- Triển khai đánh dấu dữ liệu có cấu trúc một cách toàn diện bằng các chuẩn như Schema.org và các bản thể luận (ontology) đặc thù ngành (mẫu 5).
- Phát triển các chỉ số hiệu năng máy đọc được mà tác nhân có thể kiểm chứng độc lập.
- Tạo các giao diện chuẩn hóa cho tương tác của tác nhân, cho phép so sánh và thương lượng tự động (mẫu 5).
- Thiết lập các cơ chế tin cậy có thể kiểm chứng để tác nhân dùng đánh giá độ tin cậy và chất lượng (mẫu 1).
- Duy trì vệ sinh dữ liệu hoàn hảo, vì những điểm thiếu nhất quán mà con người có thể bỏ qua sẽ khiến sản phẩm bị loại khỏi phạm vi cân nhắc của tác nhân.
Tác nhân không có lòng trung thành: Chuẩn bị cho sự minh bạch triệt để
Có lẽ hệ quả sâu sắc nhất của một thế giới do tác nhân dẫn dắt là các tác nhân AI không có lòng trung thành cố hữu với bất kỳ thương hiệu, nhà cung cấp hay nền tảng cụ thể nào. Khác với người tiêu dùng là con người vốn hình thành lòng trung thành dựa trên kết nối cảm xúc, trải nghiệm quá khứ hay đơn giản là quán tính, tác nhân ra quyết định hoàn toàn dựa trên tiêu chí tối ưu hóa và dữ liệu sẵn có. Điều này tạo ra một thị trường được định hình bởi sự minh bạch triệt để và so sánh khách quan, trong đó:
- Chi phí chuyển đổi tiệm cận về không, vì tác nhân có thể đánh giá tức thì các phương án thay thế mà không vướng ràng buộc cảm xúc.
- Quan hệ trong quá khứ mang lại lợi thế tối thiểu, trừ khi chúng chuyển hóa thành những sản phẩm vượt trội một cách khách quan.
- Giá trị thương hiệu bắt nguồn từ hiệu năng có thể kiểm chứng thay vì từ những liên tưởng cảm xúc.
- Phí ẩn hay vấn đề chất lượng không thể bị che giấu bằng tiếp thị hoặc thao túng tâm lý.
- Giá trị phải định lượng được một cách rõ ràng theo những tiêu chí mà tác nhân có thể xử lý và so sánh.
Đối với các tổ chức quen cạnh tranh dựa trên lòng trung thành thương hiệu, kết nối cảm xúc hay sự bất cân xứng thông tin, đây là một thách thức mang tính sống còn. Thành công trong một thế giới do tác nhân dẫn dắt đòi hỏi tái cấu trúc dữ liệu và vận hành xoay quanh việc cung cấp giá trị khách quan có thể chịu được sự soi xét của thuật toán. Đây chính là lúc năm mẫu kiến trúc trở nên thiết yếu — chúng tạo nền tảng để cạnh tranh trong một thị trường minh bạch triệt để.
Lái tự động doanh nghiệp: Vận hành và ra quyết định tự chủ
Vượt ra ngoài các tương tác với người tiêu dùng, AI tác nhân cho phép cái mà ta có thể gọi là "lái tự động doanh nghiệp" (business autopilot) — việc thực thi tự chủ các quy trình kinh doanh cốt lõi với sự can thiệp tối thiểu của con người. Khả năng này đang xuất hiện trên khắp các chức năng:
- Chuỗi cung ứng: Quản lý tồn kho, lựa chọn nhà cung cấp và tối ưu hóa logistics một cách tự chủ (mẫu 1, 2, 3).
- Tiếp thị: Tự động tạo chiến dịch, nhắm mục tiêu và tối ưu hóa hiệu quả (mẫu 2, 4, 5).
- Dịch vụ khách hàng: Giải quyết vấn đề trọn vẹn từ đầu đến cuối mà không cần chuyển lên cấp con người (mẫu 1, 4, 5).
- Vận hành tài chính: Tự động quản lý dòng tiền, ra quyết định đầu tư và phòng ngừa rủi ro (mẫu 1, 2, 3).
- Phát triển sản phẩm: Ưu tiên hóa tính năng và lặp thiết kế do AI dẫn dắt (mẫu 1, 3, 4).
Để các hoạt động tự chủ này vận hành hiệu quả, tổ chức phải phát triển hạ tầng dữ liệu hỗ trợ:
- Các ranh giới quyết định rõ ràng và khung phân quyền xác định nơi nào và cách nào tác nhân được phép hành động tự chủ (mẫu 5).
- Các hệ thống giám sát thời gian thực theo dõi hành động và kết quả của tác nhân (mẫu 2).
- Các cơ chế phản hồi cho phép học hỏi và cải tiến liên tục (mẫu 5).
- Các công cụ diễn giải (explainability) giúp con người hiểu được quyết định của tác nhân (mẫu 1).
- Các khả năng can thiệp/ghi đè cho phép con người vào cuộc khi cần thiết (mẫu 5).
Danh mục kiểm tra mức độ sẵn sàng dữ liệu cho tương lai do tác nhân dẫn dắt
Để chuẩn bị cho tương lai do tác nhân dẫn dắt, các tổ chức nên đánh giá mức độ sẵn sàng dữ liệu của mình theo những phương diện then chốt sau:
Khả năng truy cập dữ liệu có cấu trúc
- Mọi thuộc tính sản phẩm/dịch vụ đều có ở định dạng máy đọc được.
- Các API cung cấp quyền truy cập chuẩn hóa tới mọi dữ liệu kinh doanh liên quan.
- Cập nhật dữ liệu thời gian thực sẵn có qua các luồng sự kiện (event stream).
- Siêu dữ liệu toàn diện mô tả ý nghĩa và bối cảnh của mọi thành phần dữ liệu.
Tính minh bạch về hiệu năng
- Các chỉ số hiệu năng then chốt được định nghĩa và đo lường một cách khách quan.
- Dữ liệu hiệu năng lịch sử có thể truy cập và kiểm chứng.
- Các cam kết mức dịch vụ được hình thức hóa và máy đọc được.
- Việc giám sát hiệu năng diễn ra liên tục và minh bạch.
Tin cậy và kiểm chứng
- Nguồn gốc dữ liệu (data provenance) được theo dõi và kiểm chứng được.
- Các quy trình đảm bảo chất lượng được lập tài liệu và có thể truy cập.
- Các chứng nhận từ bên thứ ba sẵn có ở định dạng máy đọc được.
- Các chứng chỉ tin cậy được chuẩn hóa và kiểm chứng được.
Khả năng tương tác với tác nhân
- Các giao diện chuẩn hóa sẵn sàng cho truy vấn và giao dịch của tác nhân.
- Các giao thức thương lượng được định nghĩa cho giá cả và điều khoản.
- Các cơ chế phản hồi được thiết lập cho chất lượng dịch vụ.
- Các quy trình xử lý ngoại lệ được thiết lập cho những tình huống bất thường.
Quản trị và kiểm soát
- Các khung quyền hạn rõ ràng được định nghĩa cho hành động của tác nhân.
- Nhật ký kiểm toán (audit trail) được duy trì cho mọi tương tác của tác nhân.
- Các cơ chế ghi đè sẵn sàng cho sự can thiệp của con người.
- Đảm bảo tuân thủ các yêu cầu quản trị và quy định pháp lý đang thay đổi.
Những tổ chức chủ động giải quyết các yếu tố sẵn sàng này sẽ ở vị thế thuận lợi để phát triển mạnh trong nền kinh tế do tác nhân dẫn dắt đang hình thành, trong khi những tổ chức chần chừ có thể thấy mình ngày càng bị gạt ra rìa khi các giao dịch qua trung gian tác nhân trở thành chuẩn mực. Năm mẫu kiến trúc giới thiệu trong chương này cung cấp nền tảng kỹ thuật để đạt được mức sẵn sàng đó.
Bản thiết kế: Hướng dẫn triển khai
Sự tăng trưởng bùng nổ của AI tạo sinh đã tạo ra cả những cơ hội chưa từng có lẫn những thách thức đáng kể cho các tổ chức trên mọi ngành. Như chúng ta đã khám phá xuyên suốt chương này, khoảng cách giữa các bản thử nghiệm khái niệm và các triển khai vận hành thành công phần lớn bắt nguồn từ nền tảng dữ liệu chưa đầy đủ — nhưng khoảng cách này hoàn toàn có thể bắc cầu.
Bắt đầu từ đâu
Điểm khởi đầu của bạn phụ thuộc vào mức độ trưởng thành dữ liệu hiện tại và tham vọng GenAI của tổ chức.
Nếu bạn chỉ mới bắt đầu (giai đoạn thử nghiệm)
Bắt đầu với: Mẫu 4 (tìm kiếm ngữ nghĩa) + mẫu 3 (lakehouse).
Tại sao: Tìm kiếm ngữ nghĩa mang lại giá trị tức thì cho các tình huống truy xuất tài liệu và quản lý tri thức, trong khi lakehouse cung cấp nền tảng lưu trữ hợp nhất bạn sẽ cần cho các mẫu về sau.
Thời gian: 3–4 tháng để có tình huống vận hành đầu tiên.
Ví dụ tình huống: Tìm kiếm trong cơ sở tri thức nội bộ, hỏi-đáp tài liệu, trợ lý chính sách/quy trình.
Chỉ số thành công: Giảm hơn 50% thời gian tìm thông tin.
Nếu bạn đã có GenAI cơ bản đang chạy (giai đoạn thí điểm)
Bổ sung: Mẫu 2 (kiến trúc hướng sự kiện) + mẫu 1 (đồ thị tri thức).
Tại sao: Kiến trúc hướng sự kiện đảm bảo tác nhân làm việc với thông tin hiện hành, còn đồ thị tri thức cho phép suy luận liên miền, mở khóa những tình huống phức tạp hơn.
Thời gian: 4–6 tháng để nâng cấp các ứng dụng hiện có.
Ví dụ tình huống: Tác nhân dịch vụ khách hàng với bối cảnh thời gian thực, tối ưu hóa chuỗi cung ứng, phân tích liên chức năng.
Chỉ số thành công: Mở rộng từ tình huống đơn miền sang đa miền.
Nếu bạn đang mở rộng quy mô vận hành (giai đoạn tăng trưởng)
Bổ sung: Mẫu 5 (sẵn sàng cho tác nhân) + các năng lực nâng cao trên tất cả các mẫu.
Tại sao: Thiết kế sẵn sàng cho tác nhân định vị bạn cho nền kinh tế do tác nhân dẫn dắt sắp tới, còn các năng lực nâng cao (data mesh, đa phương thức, làm tươi bối cảnh thời gian thực) cho phép vận hành tự chủ.
Thời gian: 6–12 tháng để chuyển đổi hoàn toàn sang sẵn sàng cho tác nhân.
Ví dụ tình huống: Tác nhân mua sắm tự chủ, các chức năng lái tự động doanh nghiệp, trải nghiệm khách hàng qua trung gian tác nhân.
Chỉ số thành công: Cho phép tác nhân vận hành tự chủ với sự can thiệp tối thiểu của con người.
Cây quyết định: Chọn mẫu nào trước?
Hãy bắt đầu bằng việc xác định tình huống mang lại giá trị cao nhất. Điều đó sẽ dẫn bạn đến mẫu nên khởi đầu:
Truy xuất tài liệu/tri thức? → Bắt đầu với mẫu 4 (tìm kiếm ngữ nghĩa)
- Thắng nhanh với các kho tài liệu sẵn có.
- Nền tảng cho các tác nhân dựa trên RAG.
- Thời gian tới vận hành: 3–4 tháng.
Hiểu biết liên miền? → Bắt đầu với mẫu 1 (đồ thị tri thức)
- Kết nối các nguồn dữ liệu rời rạc.
- Cho phép suy luận tinh vi.
- Thời gian tới vận hành: 4–6 tháng.
Hỗ trợ ra quyết định thời gian thực? → Bắt đầu với mẫu 2 (hướng sự kiện)
- Đảm bảo tác nhân làm việc với dữ liệu hiện hành.
- Ngăn ngừa vấn đề thông tin lỗi thời.
- Thời gian tới vận hành: 3–5 tháng.
Phân tích + AI hợp nhất? → Bắt đầu với mẫu 3 (lakehouse)
- Hợp nhất hạ tầng dữ liệu.
- Hỗ trợ cả khối lượng công việc BI lẫn AI.
- Thời gian tới vận hành: 4–6 tháng.
Truy cập của tác nhân bên ngoài? → Bắt đầu với mẫu 5 (sẵn sàng cho tác nhân)
- Định vị cho nền kinh tế do tác nhân dẫn dắt.
- Cho phép các tương tác tự chủ.
- Thời gian tới vận hành: 6–9 tháng.
Hãy nhớ: Những triển khai thành công nhất luôn kết hợp nhiều mẫu. Hãy bắt đầu với một mẫu, chứng minh giá trị thật nhanh (3–6 tháng), rồi mở rộng sang các mẫu khác khi năng lực AI của bạn trưởng thành dần.
Kế hoạch hành động của bạn
Trong 30 ngày tới:
- Đánh giá mức độ trưởng thành dữ liệu hiện tại của bạn theo năm mẫu.
- Xác định tình huống GenAI mang lại giá trị cao nhất.
- Chọn mẫu khởi đầu dựa trên cây quyết định.
- Tập hợp một đội liên chức năng (kỹ thuật dữ liệu, AI/ML, các bên liên quan nghiệp vụ).
- Định nghĩa các chỉ số thành công vượt ra ngoài hiệu năng kỹ thuật để hướng tới giá trị kinh doanh.
Trong 90 ngày tới:
- Triển khai mẫu đầu tiên cho một tình huống tập trung.
- Thiết lập các vòng phản hồi với người dùng cuối.
- Lập tài liệu các bài học và quyết định kiến trúc.
- Bắt đầu lập kế hoạch cho mẫu thứ hai.
- Xây dựng năng lực tổ chức thông qua đào tạo và quản trị thay đổi.
Trong 6–12 tháng tới:
- Mở rộng sang nhiều mẫu khi các tình huống trưởng thành.
- Nhân rộng các triển khai thành công ra toàn tổ chức.
- Thiết lập các khung quản trị cho hoạt động của tác nhân.
- Chuẩn bị cho tương lai do tác nhân dẫn dắt bằng dữ liệu máy đọc được.
- Đo lường và truyền đạt giá trị kinh doanh để đảm bảo nguồn đầu tư tiếp tục.
Tóm tắt
Ở Chương 2, chúng ta sẽ đi sâu vào việc triển khai kỹ thuật của khung dữ liệu sẵn sàng cho AI, cung cấp các mẫu kiến trúc chi tiết, lựa chọn công nghệ và mô hình quản trị giúp triển khai vận hành thành công. Chúng ta sẽ khám phá các dịch vụ cụ thể của Amazon Web Services (AWS), các cách tiếp cận triển khai và các thực hành tốt nhất cho các tổ chức ở những giai đoạn khác nhau trong hành trình AI của họ.
Cửa sổ cơ hội để tạo lợi thế cạnh tranh rất hẹp. Những tổ chức xây dựng nền tảng dữ liệu sẵn sàng cho AI ngay bây giờ sẽ dẫn đầu trong nền kinh tế do tác nhân dẫn dắt, trong khi những tổ chức duy trì cách tiếp cận truyền thống có nguy cơ trở nên vô hình trước các tác nhân sẽ làm trung gian cho những tương tác khách hàng trong tương lai.
Câu hỏi không phải là có nên chuẩn bị cho tương lai do tác nhân dẫn dắt hay không — mà là liệu bạn đã sẵn sàng khi nó đến hay chưa.
Chương 2. Khung Dữ liệu cho các Ứng dụng GenAI và AI Tác tử (Agentic AI)
Trong chương này, chúng ta sẽ cung cấp một lộ trình toàn diện để xây dựng một khung dữ liệu sẵn sàng cho AI (AI-ready data framework), được thiết kế riêng cho những nhu cầu phức tạp của các ứng dụng GenAI cấp doanh nghiệp. Chúng ta sẽ:
- Khảo sát kiến trúc cốt lõi và các thành phần thiết yếu của nó, để hiểu mỗi mảnh ghép hỗ trợ thế nào cho một hệ thống AI có khả năng mở rộng, thời gian thực và giàu ngữ cảnh.
- Đi sâu vào từng tầng của khung, hé lộ cách logic nghiệp vụ, chất lượng dữ liệu, bảo mật và sự cộng tác được lồng ghép xuyên suốt.
- Khám phá các cân nhắc khi triển khai cùng những thực hành tốt nhất, bao gồm hướng dẫn hành động cụ thể để vượt qua các thách thức thường gặp trong tích hợp, quản trị và thích ứng dữ liệu.
- Nghiên cứu các ví dụ thực tế và tình huống điển hình (case study), minh họa cách những tổ chức hàng đầu đã chuyển đổi hệ sinh thái dữ liệu của họ để khai phá trọn vẹn tiềm năng của GenAI.
Chương này thiết lập các nguyên tắc nền tảng cho dữ liệu sẵn sàng cho AI và trình bày những chiến lược thực tiễn sẽ làm nền móng cho hành trình GenAI của bạn. Khi tiến xa hơn, hãy luôn ghi nhớ rằng thành công thực sự của GenAI không chỉ được quyết định bởi các mô hình tiên tiến, mà bởi sức mạnh và khả năng thích ứng của hạ tầng dữ liệu bên dưới. Khung mà bạn xây dựng ở đây sẽ là nền tảng cho mọi đổi mới GenAI và sự xuất sắc trong vận hành về sau.
Giới thiệu: Xây dựng nền móng cho Dữ liệu Sẵn sàng cho AI
Trong thế giới của AI tạo sinh (generative AI), thành công không chỉ nằm ở việc sở hữu những mô hình tinh vi nhất hay những prompt khôn khéo nhất. Nó nằm ở việc có một nền móng vững chắc, có thể tin cậy cung cấp đúng dữ liệu, vào đúng thời điểm, ở đúng định dạng. Hãy hình dung nó như việc xây một ngôi nhà — ai cũng trầm trồ trước kiến trúc đẹp và nội thất, nhưng chính phần móng mới quyết định ngôi nhà có trụ vững với thời gian hay không. Tương tự, trong khi Claude, ChatGPT và các mô hình ngôn ngữ lớn (LLM) khác làm ta kinh ngạc bởi năng lực của chúng, thì chính khung dữ liệu bên dưới mới quyết định một triển khai GenAI cấp doanh nghiệp sẽ thành công hay thất bại.
Các triển khai doanh nghiệp gần đây cho thấy một thực tế phũ phàng: nghiên cứu ngành từ Gartner và các đơn vị khác chỉ ra rằng phần lớn thất bại của các dự án AI và GenAI bắt nguồn từ vấn đề chất lượng, mức độ sẵn sàng và quản trị dữ liệu — chứ không phải từ giới hạn của mô hình. Điều này không có gì đáng ngạc nhiên. Hầu hết tổ chức đều tin rằng họ đã có dữ liệu sẵn sàng cho generative AI. Thực tế? Họ chưa. Các thực hành dữ liệu hiện hữu, vốn được dựng cho phân tích và báo cáo truyền thống, đơn giản là không thể hỗ trợ generative AI nếu thiếu một cuộc chuyển đổi căn bản.
Một nghiên cứu do AWS tài trợ (Chief Data Officer study) làm nổi bật một thách thức cốt lõi: 93% giám đốc dữ liệu (CDO) cho rằng có một chiến lược dữ liệu rõ ràng là điều thiết yếu để hiện thực hóa giá trị từ generative AI, nhưng 57% thừa nhận họ chưa điều chỉnh chiến lược dữ liệu để hỗ trợ nó ở quy mô lớn. Trên thực tế, điều này nghĩa là tương đối ít tổ chức có dữ liệu sạch, được quản trị tốt và dễ truy cập — được cấu trúc để hỗ trợ huấn luyện, tinh chỉnh (fine-tuning) và mở rộng các giải pháp AI — trong khi phần lớn thông tin của họ vẫn phân mảnh, thiếu nhất quán, hoặc bị khóa trong các silo.
Các LLM công khai như GPT-4 và Claude đã mở rộng khả năng tiếp cận những năng lực AI tiên tiến, nhưng cũng nuôi dưỡng một ngộ nhận rằng thành công của GenAI chủ yếu phụ thuộc vào việc chọn đúng mô hình hay soạn prompt khéo léo. Sự thật phức tạp hơn thế. Các ứng dụng GenAI và agentic AI cấp doanh nghiệp phải xử lý:
- Khối lượng khổng lồ dữ liệu độc quyền
- Các yêu cầu phức tạp về bảo mật và tuân thủ
- Tích hợp với những hệ thống hiện có
- Nhu cầu xử lý thời gian thực
- Học hỏi và thích ứng liên tục
Trên thực tế, yếu tố tạo khác biệt then chốt thường là liệu tổ chức có thể cung cấp các pipeline dữ liệu đáng tin cậy, được chuẩn bị tốt để nuôi và duy trì các hệ thống AI của họ hay không.
Sự tiến hóa của các Khung Dữ liệu
Sự tiến hóa của các khung dữ liệu, từ những hệ thống truyền thống đến các kiến trúc sẵn sàng cho GenAI và agentic AI, phản ánh một chuỗi các bước phát triển mang tính chuyển đổi trong xử lý, quản lý và tích hợp dữ liệu (xem Hình 2-1).
Hình 2-1. Sự tiến hóa của các khung dữ liệu (2015–nay): từ thời kỳ đầu tập trung xử lý big data (2015–2019), qua giai đoạn chuyển tiếp thời gian thực và tối ưu AI (2020–2022), tới kỷ nguyên tích hợp GenAI (2022–nay) và kỷ nguyên agentic AI với quản lý dữ liệu tự chủ (2024–nay).
Thời kỳ đầu (2015–2019)
Trong những ngày đầu của big data, các khung như Hadoop và Apache Spark được xây để xử lý khối lượng dữ liệu khổng lồ, chủ yếu thông qua các phương pháp hướng theo lô (batch-oriented). Hadoop với khả năng lưu trữ phân tán cho phép mở rộng và xử lý theo lô tiết kiệm chi phí, còn Spark giới thiệu xử lý trong bộ nhớ (in-memory) để phân tích nhanh hơn. Các đặc điểm chính của thời kỳ này gồm:
- Tập trung vào xử lý big data: Các khung được tối ưu để xử lý những tập dữ liệu lớn, chủ yếu là dữ liệu có cấu trúc.
- Kiến trúc hướng theo lô: Việc xử lý dữ liệu thường được thực hiện theo lô, ít hỗ trợ phân tích thời gian thực.
- Hỗ trợ hạn chế cho dữ liệu phi cấu trúc: Hầu hết giải pháp chật vật khi tiếp nhận dữ liệu phi cấu trúc như văn bản, hình ảnh, video.
- Năng lực quản trị cơ bản: Tính năng quản trị dữ liệu còn sơ khai, thường giới hạn ở kiểm soát truy cập cơ bản và kiểm toán (auditing).
Những thích ứng đầu tiên đã được thực hiện để hỗ trợ các khối lượng công việc AI và máy học, đặt nền móng cho những bước tiến về sau.
Thời kỳ chuyển tiếp (2020–2022)
Khi các kiểu dữ liệu và yêu cầu nghiệp vụ tiến hóa, các khung bắt đầu tích hợp những năng lực tiên tiến hơn. Giai đoạn này được đánh dấu bởi sự dịch chuyển sang xử lý dữ liệu thời gian thực và hỗ trợ tốt hơn cho các kiểu dữ liệu đa dạng. Những bước phát triển đáng chú ý gồm:
- Giới thiệu xử lý thời gian thực: Các khung bắt đầu hỗ trợ dữ liệu luồng (streaming), cho phép phân tích và ra quyết định gần như tức thời.
- Tăng cường hỗ trợ dữ liệu phi cấu trúc: Các giải pháp bắt đầu cung cấp công cụ thời gian thực như nền tảng phân tích luồng (Apache Kafka, Apache Flink) và các công cụ tìm kiếm, lập chỉ mục thời gian thực (Elasticsearch) có khả năng phân tích thông tin phi cấu trúc.
- Cải thiện tính năng quản trị: Quản trị dữ liệu nâng cao — gồm theo dõi nguồn gốc (lineage tracking), thực thi chính sách và tuân thủ — trở thành tiêu chuẩn.
- Những tối ưu hóa đầu tiên dành riêng cho AI: Các khung bắt đầu được điều chỉnh để phục vụ riêng cho khối lượng công việc AI và máy học.
Kỷ nguyên GenAI (2022–nay)
Kỷ nguyên GenAI được đánh dấu bởi sự trỗi dậy và phổ cập của các mô hình generative AI như LLM và Transformer đa phương thức (multimodal). Các hệ thống này được thiết kế để tạo ra nội dung mới — văn bản, hình ảnh, âm thanh và video — bằng cách học từ những tập dữ liệu khổng lồ, đa dạng. Các bước tiến chính về khung trong kỷ nguyên này gồm:
- Tích hợp liền mạch xuyên các nguồn: Các khung bắt đầu cho phép truy cập thống nhất tới dữ liệu có cấu trúc, bán cấu trúc và phi cấu trúc, từ cả nguồn nội bộ lẫn bên ngoài, hỗ trợ nhu cầu huấn luyện quy mô lớn của các mô hình tạo sinh.
- Luồng dữ liệu liên tục, thích ứng: Việc nạp và xử lý dữ liệu thời gian thực trở thành tiêu chuẩn, hỗ trợ các chu kỳ học liên tục mà generative AI yêu cầu và đảm bảo mô hình luôn cập nhật, phù hợp.
- Quản trị và bảo mật dữ liệu nâng cao: Khi các mô hình tạo sinh trở nên trọng yếu với doanh nghiệp, các khung tiến hóa để đảm bảo chất lượng dữ liệu, nguồn gốc, quyền riêng tư và tuân thủ quy định ở quy mô lớn.
- Nền tảng nhận thức ngữ cảnh và cơ sở tri thức: Việc tích hợp sớm các cơ sở tri thức và dữ liệu ngữ cảnh cho phép các mô hình tạo sinh đưa ra đầu ra phù hợp, chính xác và sát với nghiệp vụ hơn.
- Khả năng mở rộng cho khối lượng công việc AI: Các kiến trúc dữ liệu được thiết kế để mở rộng hiệu quả, đáp ứng nhu cầu tính toán và lưu trữ khổng lồ khi huấn luyện và triển khai các mô hình tạo sinh.
Kỷ nguyên Agentic AI (2024–nay)
Kỷ nguyên agentic AI kế thừa nền móng của GenAI nhưng giới thiệu các tác tử AI (AI agent) có khả năng tự ra quyết định, thích ứng thời gian thực và thực thi tác vụ nhiều bước với sự can thiệp tối thiểu của con người. Các khung tiếp tục tiến hóa để đáp ứng những đòi hỏi đặc thù của các hệ thống tiên tiến này, với các năng lực gồm:
- Quản lý dữ liệu tự chủ: Tự động hóa do AI dẫn dắt nay đảm nhận việc khám phá dữ liệu, giám sát chất lượng và tối ưu hóa, giảm can thiệp thủ công và đẩy nhanh đổi mới.
- Nhận thức ngữ cảnh và đồ thị tri thức: Việc tích hợp đồ thị tri thức (knowledge graph) và dữ liệu ngữ cảnh phong phú trao cho các tác tử agentic AI sự thấu hiểu sâu hơn về quy trình, mối quan hệ và ý định của tổ chức, hỗ trợ suy luận và lập kế hoạch tinh vi hơn.
- Điều phối cộng tác và mô-đun hóa: Các khung hỗ trợ điều phối nhiều tác tử chuyên biệt, mỗi tác tử xử lý một khía cạnh khác nhau của các quy trình phức tạp, cho phép giải quyết vấn đề theo kiểu cộng tác và thích ứng linh hoạt.
- Học thích ứng, thời gian thực: Các hệ thống agentic AI liên tục học và điều chỉnh hành động dựa trên phản hồi thời gian thực và điều kiện thay đổi, được hỗ trợ thêm bởi các công cụ giám sát và gỡ lỗi có khả năng phục hồi.
- Bảo mật và tuân thủ ở quy mô doanh nghiệp: Với mức tự chủ tăng lên, các khung thực thi quản trị, quyền riêng tư và khả năng kiểm toán nghiêm ngặt hơn nữa để đảm bảo vận hành AI an toàn, có đạo đức và tuân thủ trên toàn doanh nghiệp.
- Khả năng mở rộng chưa từng có (Unprecedented scalability): Các kiến trúc được thiết kế cho điện toán phân tán, có khả năng mở rộng để xử lý sự phức tạp và khối lượng dữ liệu ngày càng tăng liên quan đến các ứng dụng agentic AI tự chủ.
Tóm lại, các khung dữ liệu đã phát triển từ các giải pháp dữ liệu lớn theo lô (batch-oriented) sang kiến trúc tối ưu cho AI thời gian thực — đỉnh điểm là kỷ nguyên agentic AI ngày nay, nơi các hệ thống dữ liệu là nền tảng không thể thiếu để kích hoạt các tác tử tự chủ, thông minh thúc đẩy chuyển đổi doanh nghiệp.
Nhu cầu về Hướng Tiếp Cận Mới: Các Yêu Cầu Cốt Lõi cho Dữ Liệu AI-Ready
Khi các tổ chức chuyển đổi từ các sáng kiến generative AI thử nghiệm sang triển khai quy mô doanh nghiệp, những yêu cầu đặt ra cho các khung dữ liệu đã tăng lên đáng kể. Sự phổ cập nhanh chóng của GenAI và agentic AI trong môi trường doanh nghiệp đã làm nổi bật nhu cầu cấp thiết về một hướng tiếp cận mới trong quản lý và hạ tầng dữ liệu. Thành công trong kỷ nguyên mới này đòi hỏi nhiều hơn là chỉ lưu trữ và truy xuất thông tin — nó đòi hỏi một sự chuyển dịch cơ bản về cách dữ liệu được thu thập, kết nối và ngữ cảnh hóa.
Để hỗ trợ sự tiến hóa này, một khung dữ liệu hiện đại phải đáp ứng một số yêu cầu quan trọng — tạo thành nền tảng toàn diện cho dữ liệu AI-ready. Các yêu cầu này được thiết kế để đáp ứng những thách thức đặc thù mà GenAI và agentic AI đặt ra, bao gồm nhu cầu về thông tin giàu ngữ cảnh, xử lý thời gian thực và khả năng học thích ứng.
Hình 2-2 minh họa các yêu cầu cốt lõi và nguyên tắc dẫn hướng để tạo ra môi trường dữ liệu AI-ready, giúp các hệ thống generative AI và agentic AI học hỏi, thích ứng và tạo ra giá trị ở quy mô lớn:
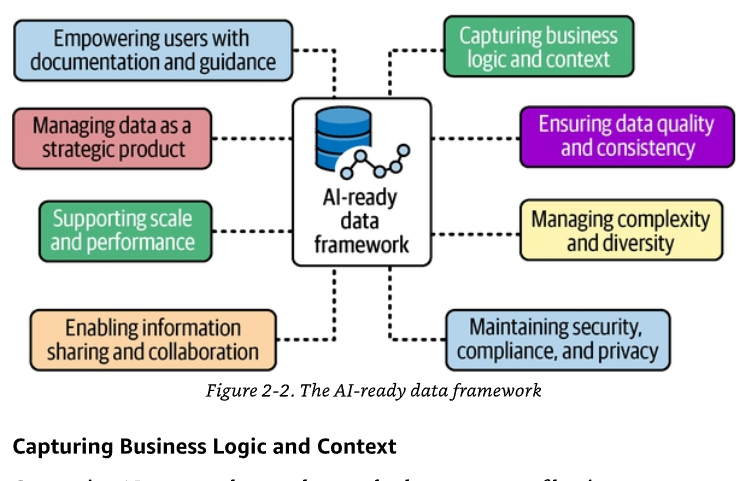
- Nắm bắt logic nghiệp vụ và ngữ cảnh (Capturing business logic and context)
- Đảm bảo chất lượng và nhất quán dữ liệu (Ensuring data quality and consistency)
- Quản lý sự phức tạp và đa dạng (Managing complexity and diversity)
- Duy trì bảo mật, tuân thủ và quyền riêng tư (Maintaining security, compliance, and privacy)
- Tạo điều kiện chia sẻ thông tin và cộng tác (Enabling information sharing and collaboration)
- Hỗ trợ mở rộng quy mô và hiệu suất (Supporting scale and performance)
- Quản lý dữ liệu như một sản phẩm chiến lược (Managing data as a strategic product)
- Trao quyền cho người dùng bằng tài liệu và hướng dẫn (Empowering users with documentation and guidance)
Trong các trang tiếp theo, chúng ta sẽ khám phá từng trụ cột này một cách chi tiết. Qua đó, chúng ta sẽ xây dựng một khung toàn diện cho dữ liệu AI-ready — khung này sẽ là cơ sở cho các phần tiếp theo của chương, nơi chúng ta đào sâu hơn vào các chiến lược triển khai thực tiễn, các thực hành tốt nhất và các nghiên cứu điển hình từ những tổ chức hàng đầu đang chuyển đổi hệ sinh thái dữ liệu của họ để khai thác tối đa tiềm năng của GenAI và agentic AI.
Nắm Bắt Logic Nghiệp Vụ và Ngữ Cảnh (Capturing Business Logic and Context)
Generative AI không chỉ cần hiểu kết quả của các quyết định kinh doanh mà còn phải hiểu các quy trình tư duy, sự đánh đổi và logic đằng sau chúng. Các hệ thống dữ liệu truyền thống thường chỉ ghi lại kết quả cuối cùng — hạn chế khả năng của AI trong việc thực sự nắm bắt trí tuệ tổ chức. Để giải quyết điều này, một khung dữ liệu AI-ready cần:
Nhận diện mô hình nghiệp vụ (Recognize business patterns)
Ghi lại cách thức đưa ra quyết định — cân nhắc phản hồi khách hàng, ràng buộc kỹ thuật, cơ hội thị trường và mục tiêu kinh doanh — để AI có thể học được lý lẽ đằng sau các hành động, không chỉ là kết quả cuối cùng.
Bảo tồn ngữ cảnh (Preserve context)
Quy trình ra quyết định phải được ghi kèm đầy đủ ngữ cảnh, bao gồm dữ liệu hỗ trợ, kinh nghiệm quá khứ, lịch sử khách hàng và các ưu tiên nghiệp vụ đang thay đổi. Điều này giúp AI hiểu không chỉ điều gì hiệu quả mà còn tại sao nó hiệu quả.
Theo dõi sự tiến hóa (Track evolution)
Tri thức nghiệp vụ là thứ luôn thay đổi. Ghi lại cách thức tri thức và nhu cầu khách hàng biến đổi theo thời gian, để AI có thể học hỏi từ lịch sử và khả năng thích ứng của tổ chức.
Đảm Bảo Chất Lượng và Nhất Quán Dữ Liệu (Ensuring Data Quality and Consistency)
Một nền tảng dữ liệu vững chắc là điều kiện thiết yếu để duy trì các tiêu chuẩn cao về chất lượng và tính nhất quán của dữ liệu trong toàn tổ chức. Các biện pháp thực hành cốt lõi gồm:
Bảo toàn tính toàn vẹn dữ liệu (Preserving data integrity)
Duy trì độ chính xác và độ tin cậy khi dữ liệu di chuyển giữa các nguồn và hệ thống khác nhau.
Chuẩn hóa định dạng dữ liệu (Standardizing data formats)
Sử dụng các định dạng và cách biểu diễn nhất quán để đảm bảo tích hợp liền mạch và khả năng tương tác giữa các hệ thống.
Triển khai cơ chế xác nhận (Implementing validation mechanisms)
Phát hiện và sửa chữa các bất thường để đảm bảo dữ liệu luôn đáng tin cậy cho các mô hình AI.
Quản Lý Sự Phức Tạp và Đa Dạng (Managing Complexity and Diversity)
Môi trường dữ liệu hiện đại ngày càng phức tạp, với vô số loại dữ liệu, nguồn và mối quan hệ khác nhau. Một khung hiệu quả cần:
Đáp ứng các loại dữ liệu đa dạng (Accommodate diverse data types)
Hỗ trợ cả dữ liệu có cấu trúc lẫn phi cấu trúc, từ các hệ thống nội bộ đến các nguồn bên ngoài.
Điều phối các luồng dữ liệu phức tạp (Orchestrate complex data flows)
Quản lý hiệu quả việc di chuyển và chuyển đổi dữ liệu qua nhiều nền tảng và hệ thống.
Bao gồm các góc nhìn đa dạng (Include diverse perspectives)
Phản ánh các phân khúc khách hàng, điều kiện thị trường và phương thức ra quyết định khác nhau để giảm thiên kiến và mở rộng hiểu biết của AI.
Quản lý các phụ thuộc phức tạp (Manage intricate dependencies)
Giải quyết các mối quan hệ và sự phụ thuộc trong và giữa các tập dữ liệu để đảm bảo tính mạch lạc và liên quan.
Duy Trì Bảo Mật, Tuân Thủ và Quyền Riêng Tư (Maintaining Security, Compliance, and Privacy)
Với áp lực quản lý ngày càng tăng và tính nhạy cảm của dữ liệu doanh nghiệp, bảo mật và tuân thủ là điều không thể thương lượng. Các tổ chức phải:
Thực thi các biện pháp kiểm soát bảo mật mạnh mẽ (Enforce robust security controls)
Bảo vệ tài sản dữ liệu khỏi truy cập trái phép và rò rỉ.
Đảm bảo tuân thủ quy định (Ensure regulatory adherence)
Tuân thủ các luật và quy định liên quan ở mọi phạm vi pháp lý.
Bảo vệ quyền riêng tư trong khi duy trì giá trị (Protect privacy while preserving value)
Xây dựng các quy tắc rõ ràng cho việc xử lý dữ liệu cá nhân và nhạy cảm, cân bằng giữa yêu cầu bảo vệ quyền riêng tư và nhu cầu về thông tin giàu ngữ cảnh.
Duy trì nhật ký kiểm toán (Maintain audit trails)
Hỗ trợ tính minh bạch và trách nhiệm giải trình thông qua nhật ký chi tiết về các truy cập và thay đổi dữ liệu.
Tạo Điều Kiện Chia Sẻ Thông Tin và Cộng Tác (Enabling Information Sharing and Collaboration)
Generative AI tìm thấy những hiểu biết có giá trị nhất khi vượt qua ranh giới giữa các phòng ban. Để tối đa hóa tiềm năng của mình, các tổ chức phải:
Phá vỡ các silo dữ liệu (Break down data silos)
Thúc đẩy chia sẻ thông tin giữa các nhóm để AI có thể nhận ra các mô hình và mối liên hệ xuyên suốt tổ chức.
Tạo điều kiện thay vì hạn chế (Enable rather than restrict)
Cung cấp cho các nhóm quyền truy cập nhanh chóng, có quản trị vào dữ liệu để đẩy nhanh quá trình tạo ra hiểu biết và đổi mới.
Hỗ Trợ Mở Rộng Quy Mô và Hiệu Suất (Supporting Scale and Performance)
Các triển khai GenAI cấp doanh nghiệp đòi hỏi các khung có thể mở rộng hiệu quả và đảm bảo hiệu suất cao. Các năng lực thiết yếu gồm:
Xử lý khối lượng dữ liệu khổng lồ (Handling massive data volumes)
Mở rộng quy mô để đáp ứng khối lượng dữ liệu tăng trưởng nhanh mà không suy giảm hiệu suất.
Cung cấp xử lý thời gian thực (Providing real-time processing)
Hỗ trợ các hiểu biết và hành động kịp thời với xử lý dữ liệu thời gian thực.
Tối ưu hóa việc sử dụng tài nguyên (Optimizing resource utilization)
Tối đa hóa hiệu quả và tối thiểu hóa chi phí trong quản lý và xử lý dữ liệu.
Quản Lý Dữ Liệu Như Một Sản Phẩm Chiến Lược (Managing Data as a Strategic Product)
Dữ liệu là một sản phẩm có giá trị, không ngừng tiến hóa và cần được quản lý chủ động. Các tổ chức nên:
Theo dõi nhu cầu và cách sử dụng dữ liệu (Track data usage and needs)
Giám sát cách các nhóm sử dụng dữ liệu và cải thiện giá trị của nó một cách có hệ thống.
Tạo phiên bản và phát triển dữ liệu (Version and evolve data)
Lưu giữ các phiên bản lịch sử của dữ liệu để thể hiện sự thay đổi của các quyết định và logic nghiệp vụ theo thời gian.
Gắn nhãn chất lượng cho dữ liệu (Brand quality data)
Đánh dấu rõ ràng dữ liệu đáp ứng các tiêu chuẩn chất lượng và quản trị để khuyến khích sử dụng đúng cách.
Trao Quyền cho Người Dùng Bằng Tài Liệu và Hướng Dẫn (Empowering Users with Documentation and Guidance)
Tài liệu hướng dẫn hiệu quả là điều kiện thiết yếu cho cả người dùng lẫn AI. Các tổ chức nên:
Tạo các hướng dẫn rõ ràng và khả thi (Create clear, actionable guides)
Cung cấp tài liệu súc tích kết nối dữ liệu với các quyết định kinh doanh và làm nổi bật những điều quan trọng nhất.
Giữ tài liệu luôn cập nhật (Keep documentation current)
Cập nhật hướng dẫn khi dữ liệu và quy trình thay đổi, đảm bảo AI và người dùng luôn làm việc với thông tin mới nhất.
Khung Cốt Lõi cho Dữ Liệu AI-Ready (A Core Framework for AI-Ready Data)
Khung cốt lõi cho dữ liệu AI-ready được trình bày ở đây là một hướng tiếp cận toàn diện để xây dựng và duy trì hạ tầng dữ liệu có khả năng hỗ trợ các hệ thống generative AI và agentic AI tiên tiến trong môi trường doanh nghiệp. Thay vì coi quản lý dữ liệu là một loạt thách thức kỹ thuật riêng lẻ, khung này cung cấp một góc nhìn tích hợp giải quyết toàn bộ phổ yêu cầu để AI thành công. Trong phần này, chúng ta sẽ xem xét từng thành phần của khung một cách chi tiết, khám phá các yếu tố cốt lõi, thực hành tốt nhất khi triển khai và các ứng dụng thực tế. Bằng cách xem xét cách các tổ chức hàng đầu đã triển khai thành công các khái niệm này, bạn sẽ có được những hiểu biết thực tiễn để chuyển đổi hệ sinh thái dữ liệu của riêng mình.
Việc khám phá sẽ cho thấy cách các thành phần liên kết với nhau tạo ra một nền tảng vững chắc, có khả năng mở rộng và thích ứng — không chỉ hỗ trợ các sáng kiến AI hiện tại mà còn kích hoạt đổi mới trong tương lai. Dù bạn đang bắt đầu hành trình AI hay muốn nâng cao các năng lực hiện có, khung này cung cấp một hướng tiếp cận có cấu trúc để xây dựng và duy trì các hệ thống dữ liệu AI-ready mang lại giá trị kinh doanh lâu dài.
Nắm Bắt Logic Nghiệp Vụ và Ngữ Cảnh — Chi Tiết (Capturing Business Logic and Context)
Khi các tổ chức mở rộng quy mô các hệ thống GenAI và agentic AI, khả năng nắm bắt và vận hành hóa logic nghiệp vụ và ngữ cảnh trở thành nhân tố nền tảng quyết định thành công. Các hệ thống dữ liệu truyền thống thường không mã hóa được lý lẽ, sự đánh đổi và tri thức chuyên môn (domain knowledge) thúc đẩy các quyết định kinh doanh — khiến các mô hình AI mù quáng trước "lý do tại sao" đằng sau dữ liệu. Như minh họa trong Hình 2-3, thành phần này của khung giải quyết những khoảng trống đó bằng cách trình bày cách nắm bắt, cấu trúc và đưa logic nghiệp vụ cùng ngữ cảnh vào môi trường dữ liệu doanh nghiệp một cách có hệ thống — trao quyền cho các hệ thống GenAI và agentic AI để cung cấp những hiểu biết chính xác, có thể giải thích và khả thi.
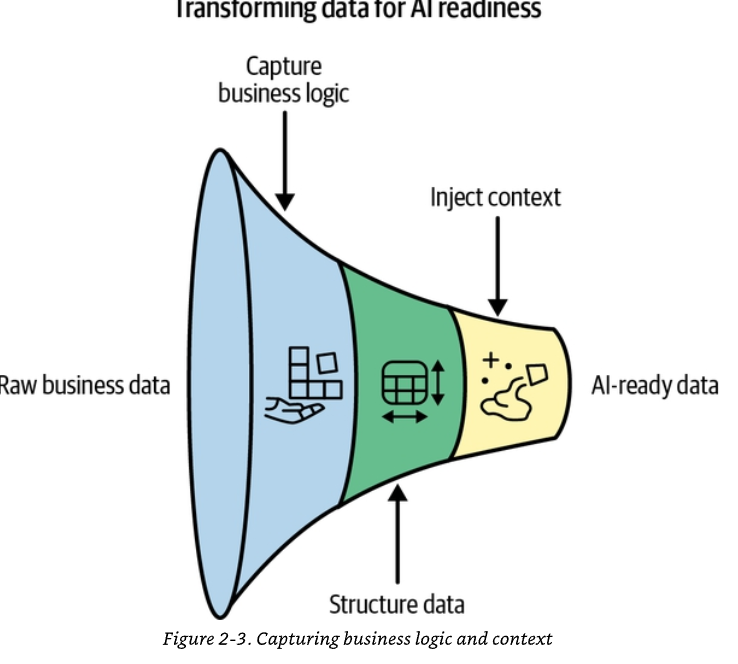
Hình 2-3. Chuyển đổi dữ liệu thô thành dữ liệu AI-ready qua 3 bước: Nắm bắt logic nghiệp vụ (Capture business logic) → Đưa ngữ cảnh vào (Inject context) → Cấu trúc hóa dữ liệu (Structure data).
Phần này phác thảo các thành phần thiết yếu cho phép vận hành hóa có hệ thống logic nghiệp vụ và ngữ cảnh trong khung dữ liệu AI-ready. Những yếu tố này là nền tảng để các hệ thống GenAI và agentic AI cung cấp những hiểu biết chính xác, có thể giải thích và thích ứng.
Các yếu tố then chốt
Định nghĩa siêu dữ liệu ngữ cảnh và từ điển nghiệp vụ (Define contextual metadata and business glossaries)
Một khung vững chắc để nắm bắt logic nghiệp vụ và ngữ cảnh bắt đầu từ siêu dữ liệu ngữ cảnh (contextual metadata) và từ điển nghiệp vụ (business glossaries). Các từ điển này cung cấp cho mô hình AI các định nghĩa, ví dụ sử dụng, nguồn gốc và nhãn danh mục để làm rõ cách dữ liệu nên được hiểu trong môi trường độc đáo của từng tổ chức. Bằng cách chuẩn hóa thuật ngữ và ánh xạ các khái niệm nghiệp vụ vào các trường dữ liệu, tổ chức đảm bảo cả con người lẫn AI chia sẻ hiểu biết nhất quán về ý nghĩa và mục đích của dữ liệu. Ví dụ, một công ty dịch vụ tài chính có thể dùng từ điển nghiệp vụ để định nghĩa "điểm rủi ro khách hàng" (customer risk score) nhất quán trong tất cả các phòng ban, đảm bảo mọi mô hình được huấn luyện trên dữ liệu này đều diễn giải các yếu tố rủi ro đồng nhất.
Thiết lập cấu trúc phân cấp và phân loại (Establish hierarchical structures and taxonomies)
Các cấu trúc phân cấp — như phân loại học (taxonomies) và từ vựng kiểm soát (controlled vocabularies) — tổ chức dữ liệu thành các danh mục và danh mục con có logic, giúp mô hình AI dễ hiểu ngữ cảnh và các phụ thuộc hơn. Những cấu trúc này giúp AI suy luận về các khái niệm rộng hơn và hẹp hơn, hỗ trợ các công cụ phân tích và đề xuất tinh tế hơn. Ví dụ, một tổ chức bán lẻ có thể triển khai phân loại sản phẩm theo danh mục, danh mục con và đơn vị lưu kho (SKU), cho phép hệ thống đề xuất do AI hỗ trợ gợi ý sản phẩm liên quan dựa trên hành vi khách hàng.
Hình thức hóa các bản thể luận và quy tắc nghiệp vụ (Formalize ontologies and business rules)
Các bản thể luận (ontologies) hình thức hóa logic nghiệp vụ bằng cách mã hóa các quy tắc, ràng buộc và mối quan hệ giữa các thực thể dữ liệu. Điều này giúp mô hình AI suy luận về các tình huống nghiệp vụ phức tạp như tiêu chí đủ điều kiện, luồng phê duyệt hay tuân thủ quy định. Bản thể luận còn hỗ trợ thích ứng động, cho phép các hệ thống agentic AI cập nhật logic khi yêu cầu nghiệp vụ thay đổi. Ví dụ, một công ty dược phẩm có thể dùng bản thể luận để mô hình hóa mối quan hệ giữa các loại thuốc, bệnh và con đường sinh học, trao quyền cho AI dự đoán tương tác thuốc và đẩy nhanh quá trình khám phá thuốc mới.
Xây dựng đồ thị tri thức cho ngữ cảnh thống nhất (Construct knowledge graphs for unified context)
Đồ thị tri thức (knowledge graphs) tích hợp siêu dữ liệu, từ điển, phân loại học và bản thể luận thành một biểu diễn thống nhất, có thể đọc bởi máy về tri thức tổ chức. Chúng kết nối các nguồn dữ liệu rời rạc, cho phép mô hình AI duyệt qua các mối quan hệ phức tạp và truy cập thông tin giàu ngữ cảnh ở quy mô lớn. Đồ thị tri thức đặc biệt có giá trị cho các kiến trúc tạo sinh tăng cường truy xuất (RAG — retrieval-augmented generation), nơi mô hình GenAI truy xuất ngữ cảnh liên quan trước khi tạo ra phản hồi.
Kích hoạt học tập và thích ứng liên tục (Enable continuous learning and adaptation)
Các hệ thống agentic AI phát triển mạnh nhờ học tập và thích ứng liên tục. Bằng cách nắm bắt các vòng phản hồi, cập nhật logic nghiệp vụ và làm mới ngữ cảnh khi thông tin mới xuất hiện, tổ chức đảm bảo mô hình AI luôn phù hợp với các ưu tiên nghiệp vụ hiện tại và yêu cầu quy định. Điều này đòi hỏi các cơ chế phiên bản hóa logic nghiệp vụ, theo dõi thay đổi và kiểm toán các đường dẫn quyết định. Ví dụ, một nền tảng thương mại điện tử có thể dùng agentic AI để điều chỉnh động chiến lược giao hàng dựa trên tồn kho thời gian thực, hiệu suất nhà vận chuyển và sở thích khách hàng — mà không cần cập nhật quy tắc thủ công.
Thực hành triển khai tốt nhất
Bây giờ hãy khám phá một số chiến lược thực tiễn và hướng tiếp cận đã được kiểm chứng để triển khai việc nắm bắt logic nghiệp vụ và ngữ cảnh. Phần này cung cấp hướng dẫn khả thi để các tổ chức triển khai và duy trì hiệu quả các thành phần khung này. Các thực hành tốt nhất này đảm bảo tri thức nghiệp vụ được nắm bắt có hệ thống, cấu trúc hóa và cung cấp cho các hệ thống GenAI và agentic AI theo cách tối đa hóa giá trị trong khi giảm thiểu thách thức triển khai:
Tập trung hóa và chuẩn hóa logic nghiệp vụ (Centralize and standardize business logic)
Tập trung hóa logic nghiệp vụ trong một tầng ngữ nghĩa (semantic layer) — thay vì nhúng vào các ứng dụng riêng lẻ hay công cụ BI — đảm bảo tính nhất quán, khả năng tái sử dụng và mở rộng. Hướng tiếp cận này tách rời logic khỏi triển khai, cho phép mô hình AI truy cập một nguồn sự thật duy nhất về các quy tắc và định nghĩa nghiệp vụ. Sử dụng các tầng ngữ nghĩa dựa trên bản thể luận để mô hình hóa các lĩnh vực nghiệp vụ, tận dụng các chuẩn như Ngôn ngữ Bản thể luận Web (OWL — Web Ontology Language) hay Khung Mô tả Tài nguyên (RDF — Resource Description Framework) để đảm bảo khả năng tương tác và tính lâu bền.
Tự động hóa đưa ngữ cảnh vào (Automate context injection)
Tự động hóa việc đưa ngữ cảnh nghiệp vụ vào các pipeline dữ liệu bằng các nền tảng quản lý siêu dữ liệu, đồ thị tri thức, cơ sở tri thức và công nghệ cơ sở dữ liệu vector. Điều này giảm thiểu nỗ lực thủ công và đảm bảo mô hình AI luôn có quyền truy cập vào ngữ cảnh mới nhất. Triển khai các khung điều phối tự động ánh xạ thuật ngữ nghiệp vụ tới ngữ nghĩa dữ liệu, giúp mô hình GenAI hiểu và giải thích phản hồi bằng thuật ngữ nghiệp vụ.
Trao quyền cho các chuyên gia nội dung (Empower subject matter experts)
Thu hút các chuyên gia lĩnh vực để chú thích tập dữ liệu, xác nhận logic nghiệp vụ và tinh chỉnh bản thể luận. Những hiểu biết của họ là thiết yếu để đảm bảo mô hình AI nắm bắt được các sắc thái của quá trình ra quyết định kinh doanh. Thiết lập các quy trình quản trị cho việc chuyên gia đánh giá và phê duyệt các cập nhật logic nghiệp vụ, đảm bảo mọi thay đổi đều có thể truy vết và kiểm toán.
Hỗ trợ luồng công việc thời gian thực và thích ứng (Support real-time and adaptive workflows)
Thiết kế các kiến trúc dữ liệu hỗ trợ cập nhật ngữ cảnh thời gian thực và luồng công việc thích ứng, cho phép các hệ thống agentic AI phản ứng linh hoạt với các điều kiện nghiệp vụ thay đổi. Tận dụng các tầng điều phối và máy chủ Model Context Protocol (MCP) để quản lý trạng thái tác tử, bộ nhớ phiên và chiến lược suy luận trong thời gian thực.
Đảm bảo khả năng giải thích và quản trị (Ensure explainability and governance)
Tích hợp các cơ chế minh bạch và khả năng giải thích vào khung dữ liệu. Minh bạch đảm bảo nguồn gốc dữ liệu, theo dõi chuyển đổi và tuân thủ quy định; trong khi khả năng giải thích mở rộng sự hiển thị này tới các quyết định do AI dẫn dắt — truy vết cách logic nghiệp vụ, các cập nhật ngữ cảnh và suy luận mô hình đã đóng góp vào một kết quả cụ thể. Ghi lại các yếu tố này giúp tổ chức vừa kiểm toán pipeline dữ liệu vừa hiểu quy trình suy luận đằng sau đầu ra AI.
Ví dụ thực tế
Để minh họa ứng dụng thực tiễn của việc nắm bắt logic nghiệp vụ và ngữ cảnh, hãy cùng xem xét một số ví dụ thực tế từ các tổ chức hàng đầu. Những nghiên cứu điển hình này cho thấy cách các yếu tố then chốt của khung đã được triển khai để tạo ra kết quả kinh doanh cụ thể và đổi mới nhờ AI. Bằng cách xem xét các sáng kiến thành công này, bạn sẽ có được những hiểu biết quý giá về cách vượt qua các rào cản phổ biến và điều chỉnh hạ tầng dữ liệu phù hợp với nhu cầu của các hệ thống generative AI và agentic AI tiên tiến:
Bán lẻ: Quản lý tồn kho động (Retail: dynamic inventory management)
Walmart triển khai các hệ thống agentic AI dự báo nhu cầu, đồng bộ tồn kho cấp cửa hàng với các trung tâm phân phối và kích hoạt robot quét kệ tự chủ. Những hệ thống này dựa trên một đồ thị tri thức tích hợp dữ liệu tồn kho, xu hướng bán hàng và chỉ số chuỗi cung ứng — cho phép điều chỉnh chiến lược tồn kho theo thời gian thực và giảm tình trạng hết hàng.
Dịch vụ tài chính: Tư vấn tài chính cá nhân hóa (Financial services: personalized financial advice)
Coach AI của JPMorgan truy xuất thông tin nghiên cứu, dự đoán câu hỏi của khách hàng và đề xuất hành động tốt nhất tiếp theo trong các biến động thị trường. Hệ thống tận dụng một tầng ngữ nghĩa mã hóa logic nghiệp vụ và ngữ cảnh khách hàng, giúp các cố vấn đưa ra khuyến nghị cá nhân hóa, dựa trên dữ liệu ở quy mô lớn.
Y tế: Sàng lọc người hiến tạng (Healthcare: organ donor screening)
Một công ty y tế sử dụng trợ lý GenAI được tăng cường bằng grounding ngữ cảnh để hợp lý hóa quy trình sàng lọc người hiến tạng. Hệ thống AI truy xuất và diễn giải các tiêu chí đủ điều kiện phức tạp từ các tài liệu quy định, cung cấp cho bác sĩ lâm sàng các đánh giá tức thì, giàu ngữ cảnh — giảm thời gian xem xét thủ công.
Dược phẩm: Khám phá thuốc (Pharmaceuticals: drug discovery)
Các công ty dược phẩm sử dụng bản thể luận để mô hình hóa mối quan hệ giữa các loại thuốc, bệnh và con đường sinh học. Điều này giúp mô hình AI dự đoán tương tác thuốc và đẩy nhanh các pipeline khám phá thuốc, tận dụng logic nghiệp vụ được hình thức hóa để thúc đẩy đổi mới.
Tóm tắt
Nắm bắt logic nghiệp vụ và ngữ cảnh là một trụ cột nền tảng của khung dữ liệu AI-ready. Bằng cách mã hóa tri thức chuyên môn, chuẩn hóa thuật ngữ và tích hợp ngữ cảnh trực tiếp vào các kiến trúc dữ liệu, tổ chức giúp các hệ thống GenAI và agentic AI cung cấp những hiểu biết chính xác, có thể giải thích và thích ứng. Các thực hành tốt nhất — như tập trung logic trong các tầng ngữ nghĩa, tự động hóa đưa ngữ cảnh vào và hỗ trợ cập nhật thời gian thực — đảm bảo AI luôn phù hợp với các ưu tiên nghiệp vụ và yêu cầu quy định đang thay đổi. Các ứng dụng thực tế trong bán lẻ, tài chính, y tế và dược phẩm cho thấy giá trị chuyển đổi của hướng tiếp cận này — biến AI từ một hộp đen thành một đối tác ra quyết định đáng tin cậy tạo ra kết quả hữu hình.
Đảm Bảo Chất Lượng và Nhất Quán Dữ Liệu — Chi Tiết (Ensuring Data Quality and Consistency)
Khi các tổ chức ngày càng áp dụng GenAI và agentic AI, chất lượng và tính nhất quán của dữ liệu nền tảng trở thành điều kiện thiết yếu cho hiệu quả và độ tin cậy của chúng. Dữ liệu kém chất lượng có thể dẫn đến các đầu ra AI không chính xác, thiên kiến hoặc thậm chí gây hại — làm xói mòn lòng tin và giá trị kinh doanh. Phần này phác thảo các yếu tố then chốt của một khung chất lượng và nhất quán dữ liệu vững chắc, các thực hành tốt nhất để triển khai và các ví dụ thực tế minh họa (Hình 2-4).
Hình 2-4. Kim tự tháp chất lượng dữ liệu AI-ready: Chất lượng dữ liệu (Data quality — đảm bảo độ chính xác và độ tin cậy) là nền tảng; Nhất quán dữ liệu (Data consistency — duy trì tính đồng nhất giữa các nguồn) ở giữa; Hiệu quả AI (AI effectiveness — nâng cao đầu ra và lòng tin) ở đỉnh.
Các yếu tố then chốt
Hãy cùng xem xét các yếu tố then chốt trong khung đảm bảo chất lượng và nhất quán dữ liệu. Phần này phác thảo các thành phần thiết yếu giúp tổ chức duy trì các tiêu chuẩn cao về tính toàn vẹn và độ tin cậy của dữ liệu trong khung dữ liệu AI-ready. Những yếu tố này là nền tảng để các hệ thống GenAI và agentic AI tạo ra những hiểu biết chính xác, đáng tin cậy và có giá trị:
Duy trì các tiêu chuẩn chất lượng dữ liệu cốt lõi (Uphold core data quality standards)
Đối với các hệ thống AI, chất lượng dữ liệu thường được đánh giá qua nhiều chiều quan trọng:
- Độ chính xác (Accuracy): Dữ liệu phải biểu diễn chính xác các thực thể hoặc sự kiện trong thế giới thực. Dữ liệu không chính xác dẫn đến dự đoán và quyết định AI sai lầm.
- Đầy đủ (Completeness): Tất cả thông tin cần thiết phải hiện diện. Dữ liệu thiếu có thể gây ra thiên kiến hoặc làm giảm hiệu quả mô hình.
- Nhất quán (Consistency): Dữ liệu phải đồng nhất giữa các nguồn và định dạng. Dữ liệu không nhất quán làm phức tạp việc tích hợp và phân tích.
- Kịp thời (Timeliness): Dữ liệu phải cập nhật và phù hợp với ngữ cảnh mà AI vận hành.
- Hợp lệ (Validity): Dữ liệu phải tuân thủ các quy tắc và định dạng đã định nghĩa.
- Duy nhất (Uniqueness): Mỗi điểm dữ liệu phải riêng biệt và không bị trùng lặp.
- Đáng tin cậy (Dependability): Dữ liệu phải đáng tin và không bị thay đổi hay hỏng đột ngột.
- Liên quan (Relevance): Chỉ sử dụng dữ liệu phù hợp với mục tiêu của AI. Dữ liệu không liên quan tạo ra nhiễu và làm giảm hiệu suất mô hình.
Nhúng quản trị và siêu dữ liệu vào kiến trúc nền tảng (Embed governance and metadata into platform architecture)
Quản trị dữ liệu thiết lập các chính sách, vai trò và quy trình để đảm bảo dữ liệu luôn an toàn, tuân thủ và phù hợp với mục đích. Các khung quản trị rất cần thiết cho việc quản lý dữ liệu có cấu trúc, bán cấu trúc và phi cấu trúc, cũng như để hỗ trợ ra quyết định liên chức năng. Quản lý siêu dữ liệu duy trì tài liệu và định nghĩa cho các phần tử dữ liệu, tăng cường tính minh bạch, khả năng khám phá và theo dõi nguồn gốc. Siêu dữ liệu đặc biệt quan trọng đối với GenAI — vốn thường dựa vào nội dung phi cấu trúc.
Quản lý dữ liệu qua toàn bộ vòng đời (Manage data throughout its lifecycle)
Để đảm bảo chất lượng và tuân thủ liên tục, hãy quản lý dữ liệu qua tất cả các giai đoạn vòng đời:
- Thu thập (Collection): Thu thập dữ liệu có cấu trúc, phi cấu trúc và đa phương thức từ các nguồn đáng tin cậy, mang tính đại diện.
- Làm sạch (Cleansing): Loại bỏ trùng lặp, xử lý các giá trị thiếu và sửa lỗi.
- Gán nhãn (Labeling): Thêm nhãn, siêu dữ liệu và ngữ cảnh để phù hợp với nhu cầu học có giám sát và suy luận của tác tử.
- Lưu trữ (Storage): Lưu trữ an toàn các tập dữ liệu và embedding trong kho dữ liệu (warehouse), hồ dữ liệu (lake) hoặc cơ sở dữ liệu vector với các biện pháp kiểm soát quản trị.
- Sử dụng (Usage): Huấn luyện, tinh chỉnh và đánh giá các mô hình tạo sinh; cho phép các hệ thống agentic suy luận, hành động và thích ứng bằng tri thức đã được tuyển chọn.
- Lưu trữ dài hạn/Xóa (Archiving/deletion): Lưu trữ hoặc xóa dữ liệu lỗi thời hoặc không cần thiết để duy trì tính liên quan và tuân thủ.
Hợp nhất các hệ sinh thái dữ liệu phân mảnh (Unify fragmented data ecosystems)
Các hệ thống agentic AI cần truy cập liền mạch vào dữ liệu tích hợp trên toàn doanh nghiệp. Các silo dữ liệu có thể cản trở khả năng hành động tự chủ và cung cấp kết quả phù hợp ngữ cảnh của hệ thống. Các chiến lược và công cụ tích hợp là thiết yếu để hợp nhất các nguồn dữ liệu rời rạc.
Thực hành triển khai tốt nhất
Bây giờ hãy khám phá một số chiến lược thực tiễn và hướng tiếp cận đã được kiểm chứng để triển khai các biện pháp chất lượng và nhất quán dữ liệu vững chắc. Những thực hành tốt nhất này đảm bảo chất lượng dữ liệu được quản lý, giám sát và cải thiện một cách có hệ thống — cho phép các hệ thống GenAI và agentic AI vận hành với thông tin đáng tin cậy và nhất quán:
Thiết lập khung quản trị dữ liệu (Establish a data governance framework)
Xác định rõ thế nào là dữ liệu chất lượng cao đối với tổ chức của bạn và ghi lại các tiêu chuẩn đó. Chỉ định các quản trị viên dữ liệu (data stewards) — cá nhân hoặc nhóm chịu trách nhiệm duy trì chất lượng dữ liệu và thực thi các chính sách quản trị. Ghi chép cẩn thận các chính sách và quy trình để đảm bảo mọi thực hành quản lý dữ liệu đều minh bạch và dễ tiếp cận.
Đánh giá và giám sát chất lượng dữ liệu (Assess and monitor data quality)
Thường xuyên đánh giá dữ liệu theo các chỉ số chất lượng, xác định và ưu tiên các khu vực cần cải thiện. Sử dụng các công cụ tự động để liên tục giám sát các pipeline dữ liệu, phát hiện bất thường và cảnh báo nhóm về các sự cố theo thời gian thực. Tận dụng các nền tảng quan sát dữ liệu (data observability) cung cấp giám sát toàn diện, theo dõi nguồn gốc và khả năng phát hiện bất thường — hỗ trợ giải quyết vấn đề chủ động.
Tự động hóa quản lý chất lượng dữ liệu (Automate data quality management)
Sử dụng các công cụ do AI dẫn dắt để tự động phát hiện và sửa lỗi, chuẩn hóa định dạng và loại bỏ bản ghi trùng lặp. Các tác tử thông minh có thể xác nhận dữ liệu khi dữ liệu đi vào hệ thống. Agentic AI có thể học các định dạng ưu tiên và áp dụng các quy tắc chuẩn hóa trên toàn tổ chức.
Xây dựng văn hóa chất lượng dữ liệu (Foster a culture of data quality)
Giáo dục nhân viên về tầm quan trọng của chất lượng dữ liệu và đào tạo về các thực hành tốt nhất. Airbnb, ví dụ, đã khởi động "Data University" để tăng cường và cải thiện mức độ tương tác với các công cụ dữ liệu. Liên kết các quản trị viên dữ liệu, IT, tuân thủ và người dùng nghiệp vụ vào các sáng kiến chất lượng dữ liệu để đảm bảo sự đồng thuận và áp dụng rộng rãi.
Tận dụng AI để nâng cao chất lượng dữ liệu (Leverage AI for data quality enhancement)
GenAI và agentic AI có thể tự động hóa việc phân tích hồ sơ dữ liệu, phát hiện và sửa lỗi — giảm công sức thủ công và cải thiện độ chính xác. Các tác tử thông minh có thể tự động tạo siêu dữ liệu, theo dõi nguồn gốc và ánh xạ các phụ thuộc lẫn nhau — nâng cao tính minh bạch và tuân thủ. Agentic AI có thể thực thi các chính sách quản trị, phát hiện vi phạm và cảnh báo các bên liên quan theo thời gian thực.
Ví dụ thực tế
Để minh họa ứng dụng thực tiễn của các biện pháp chất lượng và nhất quán dữ liệu, hãy cùng xem xét một số ví dụ thực tế từ các tổ chức hàng đầu. Những nghiên cứu điển hình này cho thấy cách các yếu tố then chốt của khung đã được triển khai để cải thiện hiệu suất AI và kết quả kinh doanh một cách cụ thể:
Y tế: Hồ sơ bệnh nhân chính xác và nhất quán (Healthcare: accurate and consistent patient records)
Trong y tế, duy trì hồ sơ bệnh nhân chính xác và nhất quán là điều sống còn. Các hệ thống agentic AI có thể đối chiếu dữ liệu giữa hồ sơ y tế điện tử (EHR), hệ thống bảo hiểm và nhà thuốc, tự động phát hiện và sửa các mâu thuẫn. Điều này đảm bảo nhân viên y tế có quyền truy cập vào thông tin đáng tin cậy, giảm nguy cơ sai sót y tế và cải thiện kết quả điều trị.
Thương mại điện tử: Danh sách sản phẩm chất lượng cao (Ecommerce: high-quality product listings)
Các nền tảng thương mại điện tử phụ thuộc vào dữ liệu sản phẩm chính xác và cập nhật. Các hệ thống chất lượng dữ liệu do AI dẫn dắt tự động xác nhận, loại bỏ trùng lặp và làm phong phú thêm danh sách sản phẩm — đảm bảo khách hàng nhận được thông tin đáng tin cậy và cải thiện tỷ lệ chuyển đổi.
Dịch vụ tài chính: Phát hiện gian lận và tuân thủ thời gian thực (Financial services: real-time fraud detection and compliance)
Trong fintech, các hệ thống agentic AI phân tích dữ liệu giao dịch thời gian thực để phát hiện hoạt động gian lận và đảm bảo tuân thủ các yêu cầu quy định. Quản trị dữ liệu vững chắc và kiểm tra chất lượng dữ liệu liên tục là thiết yếu để duy trì tính toàn vẹn và độ tin cậy của các hệ thống này.
IoT Công nghiệp: Nền tảng Predix của General Electric (Industrial IoT: General Electric's Predix platform)
Nền tảng Predix của GE sử dụng các công cụ chất lượng dữ liệu tự động để quản lý khối lượng khổng lồ dữ liệu công nghiệp. Các công cụ này thực hiện làm sạch, xác nhận và giám sát dữ liệu liên tục — đảm bảo mô hình AI có quyền truy cập vào dữ liệu chính xác và đáng tin cậy cho bảo trì dự đoán và thông tin vận hành.
Tóm tắt
Đảm bảo chất lượng và nhất quán dữ liệu là một nền tảng cốt lõi của khung dữ liệu AI-ready, đặc biệt đối với các hệ thống GenAI và agentic AI. Bằng cách tập trung vào các chiều chất lượng dữ liệu cốt lõi, triển khai quản trị dữ liệu vững chắc, tận dụng các công cụ tự động và xây dựng văn hóa cải tiến liên tục, các tổ chức có thể khai phá tiềm năng đầy đủ của các công nghệ AI tiên tiến. Các ví dụ thực tế từ y tế, thương mại điện tử, dịch vụ tài chính và IoT công nghiệp cho thấy những lợi ích hữu hình của việc ưu tiên chất lượng dữ liệu như một yêu cầu bắt buộc. Khi các hệ thống AI ngày càng trở nên dễ tiếp cận và có tác động lớn hơn, tầm quan trọng của dữ liệu chất lượng cao và nhất quán sẽ chỉ tiếp tục tăng lên.
Quản Lý Sự Phức Tạp và Đa Dạng — Chi Tiết (Managing Complexity and Diversity)
Các hệ thống AI hiện đại — đặc biệt là GenAI và agentic AI — được xây dựng trên các hệ sinh thái dữ liệu phức tạp và đa dạng hơn bao giờ hết. Sự phức tạp này nảy sinh từ sự bùng nổ của các loại dữ liệu, nguồn và các phụ thuộc phức tạp cần được quản lý để đảm bảo kết quả AI đáng tin cậy, có thể mở rộng và không thiên kiến. Giải quyết những thách thức này đòi hỏi một khung chuyên dụng nắm bắt sự đa dạng, điều phối sự phức tạp và duy trì tính mạch lạc trên toàn bộ cảnh quan dữ liệu (Hình 2-5).
Hình 2-5. Ba luồng hội tụ tạo ra kết quả AI vững chắc: ① Các loại dữ liệu đa dạng (Data types) đòi hỏi quản lý thống nhất; ② Nhiều nguồn dữ liệu (Data sources) cần tích hợp mạch lạc; ③ Các mối quan hệ dữ liệu phức tạp (Data relationships) cần xử lý có cấu trúc.
Các yếu tố then chốt
Đáp ứng các loại dữ liệu đa dạng (Accommodate diverse data types)
Các hệ thống AI phải hỗ trợ cả dữ liệu có cấu trúc (ví dụ: cơ sở dữ liệu, bảng tính) và dữ liệu phi cấu trúc (ví dụ: văn bản, hình ảnh, dữ liệu cảm biến), thường bắt nguồn từ các hệ thống nội bộ và nguồn bên ngoài. Đối với GenAI và agentic AI, điều này có nghĩa là:
- Tích hợp dữ liệu từ nhiều định dạng và phương thức khác nhau (văn bản, hình ảnh, âm thanh, video, chuỗi thời gian, v.v.)
- Đảm bảo tính tương thích và khả năng tương tác giữa các loại dữ liệu — điều quan trọng để huấn luyện các mô hình AI đa phương thức và cho phép các hệ thống agentic hoạt động hiệu quả trong các môi trường đa dạng
- Tận dụng các chuẩn quốc tế và từ vựng chuyên ngành (như ICD-10 cho y tế hoặc ISO-8601 cho thời gian) để duy trì tính nhất quán về ngữ nghĩa giữa các tập dữ liệu
Điều phối các luồng dữ liệu phức tạp (Orchestrate complex data flows)
Quản lý hiệu quả việc di chuyển và chuyển đổi dữ liệu qua nhiều nền tảng và hệ thống là điều thiết yếu do tính chất phân tán của các hệ sinh thái dữ liệu hiện đại. Điều này bao gồm:
- Tự động hóa các quy trình nhập, chuyển đổi và đồng bộ dữ liệu để giảm thiểu can thiệp thủ công và hạn chế lỗi
- Sử dụng các công cụ và pipeline tích hợp dữ liệu có thể xử lý truyền phát thời gian thực, xử lý theo lô và môi trường đám mây lai
- Triển khai theo dõi nguồn gốc dữ liệu (data lineage tracking) vững chắc để đảm bảo khả năng truy vết và minh bạch trong các luồng dữ liệu — điều quan trọng cho tuân thủ và kiểm toán mô hình
Bao gồm các góc nhìn đa dạng (Include diverse perspectives)
Để giảm thiên kiến và mở rộng hiểu biết của AI, điều quan trọng là phản ánh các phân khúc khách hàng, điều kiện thị trường và phương thức ra quyết định khác nhau trong dữ liệu. Điều này đòi hỏi:
- Thu thập và tuyển chọn dữ liệu đại diện cho toàn bộ phổ trải nghiệm, hành vi và nhân khẩu học của người dùng
- Thường xuyên kiểm toán tập dữ liệu để phát hiện các khoảng thiếu đại diện và chủ động thu thập dữ liệu để lấp đầy những khoảng trống đó — hỗ trợ tính công bằng và hòa nhập trong kết quả AI
- Thu hút các bên liên quan từ nhiều nền tảng khác nhau để định hướng các chiến lược thu thập và gán nhãn dữ liệu
Quản lý các phụ thuộc phức tạp (Manage intricate dependencies)
Các tập dữ liệu hiện đại có mối liên hệ với nhau, với các phụ thuộc cả bên trong lẫn giữa các tài sản dữ liệu. Quản lý các phụ thuộc này đảm bảo tính mạch lạc và liên quan. Điều này bao gồm:
- Ánh xạ các mối quan hệ giữa các thực thể dữ liệu, chẳng hạn liên kết giao dịch khách hàng với tồn kho sản phẩm hoặc kết nối dữ liệu cảm biến với nhật ký bảo trì
- Sử dụng siêu dữ liệu và danh mục dữ liệu để ghi lại các phụ thuộc và hỗ trợ phân tích tác động hiệu quả khi có thay đổi
- Áp dụng các thực hành phân loại và quản trị dữ liệu để kiểm soát truy cập, đảm bảo tuân thủ và duy trì tính toàn vẹn dữ liệu khi các phụ thuộc tiến hóa
Thực hành triển khai tốt nhất
Những thực hành tốt nhất này đảm bảo các loại dữ liệu đa dạng được tích hợp liền mạch, các luồng dữ liệu phức tạp được điều phối hiệu quả và các phụ thuộc phức tạp được quản lý tốt — cho phép các hệ thống GenAI và agentic AI khai thác toàn bộ phổ thông tin có sẵn:
Chuẩn hóa phân loại và lập danh mục dữ liệu (Standardize data classification and cataloging)
Phân loại dữ liệu theo loại, nguồn, mức độ nhạy cảm và mức liên quan kinh doanh. Sử dụng các công cụ danh mục dữ liệu hiện đại để cung cấp một cái nhìn thống nhất về tất cả tài sản dữ liệu, nguồn gốc và các phụ thuộc.
Triển khai tích hợp và chuyển đổi dữ liệu tự động (Implement automated data integration and transformation)
Triển khai các pipeline ETL và ELT có thể xử lý các loại dữ liệu và nguồn đa dạng. Tích hợp kiểm tra chất lượng và xác nhận vào mọi giai đoạn để phát hiện bất thường sớm.
Tiến hành kiểm toán đa dạng và thiên kiến (Conduct diversity and bias audits)
Thường xuyên đánh giá tập dữ liệu về tính đa dạng, cân bằng và các nguồn tiềm ẩn của thiên kiến. Thu hút nhóm liên chức năng — chuyên gia lĩnh vực, nhà khoa học dữ liệu và chuyên gia đạo đức — trong việc xem xét các quy trình thu thập và tuyển chọn dữ liệu.
Quản lý siêu dữ liệu và phụ thuộc (Manage metadata and dependencies)
Duy trì siêu dữ liệu toàn diện cho mọi tập dữ liệu, bao gồm thông tin nguồn gốc, tần suất cập nhật và các mối quan hệ với tập dữ liệu khác. Sử dụng công cụ ánh xạ phụ thuộc để trực quan hóa và quản lý tác động của thay đổi trên các tài sản dữ liệu liên kết.
Kích hoạt phản hồi và lặp liên tục (Enable continuous feedback and iteration)
Thiết lập vòng phản hồi giữa nhà xuất bản dữ liệu và người thực hành AI, hỗ trợ tinh chỉnh liên tục dựa trên sử dụng thực tế. Giám sát luồng dữ liệu và phụ thuộc trong môi trường sản xuất bằng nền tảng quan sát để phát hiện và giải quyết sự cố chủ động.
Ví dụ thực tế
Y tế: Tích hợp dữ liệu bệnh nhân đa phương thức (Healthcare: multimodal patient data integration)
Một hệ thống bệnh viện hàng đầu tích hợp dữ liệu EHR có cấu trúc, ghi chú lâm sàng phi cấu trúc, dữ liệu hình ảnh và nguồn dữ liệu cảm biến thời gian thực để cung cấp năng lực cho các mô hình GenAI phục vụ chẩn đoán và chăm sóc cá nhân hóa. Các pipeline tự động điều phối luồng dữ liệu từ các nguồn khác nhau, trong khi danh mục siêu dữ liệu ghi lại các phụ thuộc và đảm bảo tuân thủ quy định về quyền riêng tư.
Thương mại điện tử: Customer 360 và công cụ đề xuất (Ecommerce: Customer 360 and recommendation engines)
Một nhà bán lẻ toàn cầu kết hợp dữ liệu giao dịch, luồng click, nội dung mạng xã hội và đánh giá sản phẩm để xây dựng cái nhìn toàn diện về từng khách hàng. Quản lý đa dạng dữ liệu và phụ thuộc cho phép đề xuất chính xác và trải nghiệm cá nhân hóa, trong khi kiểm toán thường xuyên đảm bảo tính đại diện giữa các phân khúc.
IoT Công nghiệp: Bảo trì dự đoán (Industrial IoT: predictive maintenance)
Một tập đoàn công nghiệp thu thập dữ liệu cảm biến từ hàng nghìn máy móc, tích hợp với nhật ký bảo trì và thông tin chuỗi cung ứng. Các luồng dữ liệu tự động và ánh xạ phụ thuộc cho phép GenAI và agentic AI dự đoán hỏng hóc thiết bị và tối ưu hóa tồn kho — giảm thời gian dừng máy và chi phí.
Khu vực xã hội: Khung dữ liệu đa dạng (Social sector: diversity data frameworks)
Các tổ chức trong khu vực xã hội triển khai các khung để đảm bảo dữ liệu đa dạng được thu thập, xử lý và áp dụng theo cách toàn diện và lấy người dùng làm trung tâm. Điều này bao gồm các tiêu chuẩn toàn ngành, chiến lược bảo vệ quyền riêng tư ở cấp độ tổ chức và cá nhân để thúc đẩy công bằng và đại diện trong các sáng kiến AI.
Tóm tắt
Quản lý sự phức tạp và đa dạng của dữ liệu không chỉ là thách thức kỹ thuật — đây là yêu cầu chiến lược bắt buộc đối với các tổ chức đang xây dựng hệ thống GenAI và agentic AI. Bằng cách đáp ứng các loại dữ liệu đa dạng, điều phối các luồng phức tạp, bao gồm nhiều góc nhìn và quản lý các phụ thuộc, tổ chức có thể đảm bảo các khung dữ liệu AI-ready của mình vững chắc, toàn diện và bền vững. Những thực hành này không chỉ nâng cao hiệu suất và độ tin cậy của AI mà còn thúc đẩy lòng tin và đổi mới trên toàn doanh nghiệp.
Duy Trì Bảo Mật, Tuân Thủ và Quyền Riêng Tư — Chi Tiết (Maintaining Security, Compliance, and Privacy)
Khi các tổ chức mở rộng các hệ thống GenAI và agentic AI, họ phải đối mặt với áp lực quản lý chưa từng có và phải xử lý phù hợp bản chất nhạy cảm của dữ liệu doanh nghiệp. Bảo mật, tuân thủ và quyền riêng tư không phải tùy chọn — chúng là nền tảng để xây dựng lòng tin, tránh rủi ro pháp lý và kích hoạt đổi mới AI có trách nhiệm. Phần này phác thảo các thành phần thiết yếu của khung duy trì bảo mật, tuân thủ và quyền riêng tư trong các môi trường dữ liệu AI-ready.
Hình 2-6. Ba trụ cột giao thoa tạo ra quản trị dữ liệu AI đáng tin cậy: Bảo mật (Security — bảo vệ dữ liệu khỏi truy cập trái phép), Tuân thủ (Compliance — tuân thủ các tiêu chuẩn pháp lý và quy định), và Quyền riêng tư (Privacy — bảo vệ thông tin cá nhân).
Các yếu tố then chốt
Những yếu tố này là nền tảng để các hệ thống GenAI và agentic AI vận hành có trách nhiệm và đạo đức, xây dựng lòng tin và đảm bảo tuân thủ pháp lý trong kỷ nguyên sử dụng dữ liệu chưa từng có:
Thực thi các biện pháp kiểm soát bảo mật mạnh mẽ (Enforce robust security controls)
Ngoài bảo vệ dữ liệu truyền thống, các biện pháp kiểm soát bảo mật phải bao gồm kiểm soát truy cập chi tiết, giảm thiểu mối đe dọa đặc thù cho AI và các guardrail có thể thực thi. Kiến trúc bảo mật nên tích hợp thực thi chính sách trực tiếp vào các luồng làm việc dữ liệu và mô hình để giảm thiểu rủi ro:
- Sử dụng mã hóa (khi lưu trữ và khi truyền dẫn), mã hóa token và các thực hành lưu trữ an toàn để bảo vệ tài sản dữ liệu khỏi truy cập và rò rỉ trái phép
- Triển khai cơ chế xác thực và ủy quyền nghiêm ngặt (kiểm soát truy cập dựa trên vai trò, nguyên tắc đặc quyền tối thiểu, xem xét truy cập định kỳ) để chỉ người dùng và hệ thống được phê duyệt mới có quyền truy cập dữ liệu nhạy cảm
- Giải quyết các rủi ro mới do AI gây ra, chẳng hạn như rò rỉ dữ liệu qua prompt hoặc ghi nhớ mô hình, bằng cách triển khai các công cụ ngăn chặn mất dữ liệu (DLP) có nhận thức AI và giám sát các tương tác mô hình AI
- Áp dụng guardrail nhất quán và thực thi chính sách tự động để chặn mối đe dọa, ngăn vi phạm chính sách và giảm nguy cơ tạo ra hoặc tiết lộ nội dung không mong muốn hay gây hại
Đảm bảo tuân thủ quy định (Ensure regulatory adherence)
Tuân thủ quy định đòi hỏi các chiến lược tuân thủ toàn cầu phối hợp, kiểm soát chính sách tự động và ranh giới chủ quyền dữ liệu rõ ràng:
- Cập nhật liên tục với các quy định đang thay đổi như Quy định Bảo vệ Dữ liệu Chung (GDPR), Luật Trách nhiệm Giải trình và Khả năng Chuyển giao Bảo hiểm Y tế (HIPAA), Luật Quyền riêng tư Người tiêu dùng California (CCPA) và Luật AI EU — đảm bảo xử lý, xử lý và huấn luyện mô hình AI tuân thủ mọi luật hiện hành
- Tận dụng các công cụ tự động để giám sát, thực thi và ghi lại các hoạt động tuân thủ — giảm sai sót thủ công và hợp lý hóa kiểm toán
- Tôn trọng các yêu cầu thẩm quyền về nơi dữ liệu được lưu trữ và xử lý, đặc biệt khi sử dụng môi trường đám mây hoặc lai
Bảo vệ quyền riêng tư trong khi giữ giá trị (Protect privacy while preserving value)
Các tổ chức phải bảo vệ quyền riêng tư cá nhân trong khi duy trì giá trị phân tích và vận hành của dữ liệu. Điều này đòi hỏi kỷ luật dữ liệu, các kỹ thuật ẩn danh và che dữ liệu, và các lựa chọn thiết kế có chủ đích cân bằng giữa bảo vệ quyền riêng tư và giá trị sử dụng về sau:
- Chỉ thu thập dữ liệu cần thiết cho mục tiêu AI và xác định rõ mục đích sử dụng — giảm thiểu phơi nhiễm và rủi ro
- Sử dụng công cụ do AI dẫn dắt để tự động phát hiện, phân loại và ẩn danh dữ liệu cá nhân hoặc nhạy cảm trước khi sử dụng trong mô hình AI hoặc chia sẻ ra ngoài
- Xây dựng các chính sách rõ ràng bảo vệ quyền riêng tư cá nhân trong khi cho phép dữ liệu giàu ngữ cảnh phục vụ AI — đảm bảo yêu cầu quyền riêng tư không cản trở quá mức đổi mới
Duy trì nhật ký kiểm toán (Maintain audit trails)
Ghi log toàn diện và nhật ký kiểm toán là bắt buộc để đảm bảo minh bạch, trách nhiệm giải trình và hỗ trợ giám sát tự động cùng phản ứng sự cố nhanh chóng:
- Ghi lại mọi truy cập, sử dụng và thay đổi dữ liệu — bao gồm ai truy cập dữ liệu nào, khi nào và vì mục đích gì
- Sử dụng nhật ký kiểm toán để hỗ trợ điều tra, chứng minh tuân thủ và xây dựng lòng tin với cơ quan quản lý, đối tác và khách hàng
- Triển khai công cụ tự động theo dõi và báo cáo về luồng dữ liệu, truy cập và vi phạm chính sách — hỗ trợ phản ứng sự cố theo thời gian thực
Thực hành triển khai tốt nhất
Các thực hành tốt nhất này đảm bảo bảo vệ dữ liệu được tích hợp có hệ thống vào các luồng công việc AI, tuân thủ quy định được tự động hóa tối đa và bảo vệ quyền riêng tư trở thành khía cạnh cơ bản trong thiết kế và vận hành hệ thống AI:
Áp dụng khung bảo mật sẵn sàng cho AI (Adopt an AI-ready security framework)
Tích hợp các biện pháp kiểm soát bảo mật và tuân thủ xuyên suốt vòng đời AI — từ nhập dữ liệu và huấn luyện đến triển khai và suy luận — thay vì coi chúng là điều phụ thêm.
Tự động hóa các hoạt động quyền riêng tư và tuân thủ (Automate privacy and compliance operations)
Sử dụng các nền tảng hợp nhất các hoạt động quyền riêng tư và tuân thủ, cung cấp thông tin rủi ro thời gian thực và tự động hóa báo cáo quy định.
Triển khai phân loại dữ liệu có nhận thức AI (Implement AI-aware data classification)
Tự động xác định và gán nhãn dữ liệu nhạy cảm không nên tiếp xúc với huấn luyện hoặc suy luận AI, sử dụng khớp mẫu và học sâu.
Cung cấp giáo dục liên tục và cập nhật chính sách (Provide continuous education and policy updates)
Đào tạo nhân viên về các thực hành tốt nhất về bảo mật và quyền riêng tư, và cập nhật chính sách thường xuyên để phản ánh các mối đe dọa mới và thay đổi quy định.
Chứng nhận các thực hành AI có trách nhiệm (Certify responsible AI practices)
Tìm kiếm các chứng nhận bên ngoài (ví dụ: TRUSTe) để thể hiện cam kết với AI có trách nhiệm và xử lý dữ liệu minh bạch.
Ví dụ thực tế
Dịch vụ tài chính: Thực thi kiểm soát bảo mật mạnh mẽ (Financial services: enforcing robust security controls)
JPMorgan Chase triển khai các hệ thống giám sát tùy chỉnh để phát hiện và ngăn chặn dữ liệu tài chính nhạy cảm rò rỉ qua các tương tác của nhân viên với ChatGPT và các công cụ AI tạo sinh khác. Điều này bao gồm các khả năng ngăn chặn mất dữ liệu có nhận thức AI (AI-aware DLP) có thể xác định nội dung có nguy cơ trong các prompt và chặn chúng theo thời gian thực.
Dịch vụ tài chính: Đảm bảo tuân thủ quy định (Financial services: ensuring regulatory adherence)
Goldman Sachs xây dựng hệ thống giám sát tuân thủ tự động gọi là "AI Guardian" theo dõi tất cả dữ liệu huấn luyện mô hình AI dựa trên các yêu cầu quy định từ nhiều thẩm quyền khác nhau, bao gồm GDPR, CCPA và các quy định tài chính như MiFID II. Hệ thống sử dụng xử lý ngôn ngữ tự nhiên (NLP) để tự động phân loại loại dữ liệu, duy trì bản đồ động về sự phù hợp quy định và có thể tự động điều chỉnh quyền truy cập dữ liệu hoặc tham số mô hình nếu phát hiện rủi ro tuân thủ tiềm ẩn.
Công nghệ: Bảo vệ quyền riêng tư trong khi giữ giá trị (Technology: protecting privacy while preserving value)
Hệ thống học liên kết (federated learning) của Apple cho dự đoán bàn phím bảo vệ quyền riêng tư người dùng bằng cách giữ dữ liệu cá nhân trên thiết bị trong khi vẫn cho phép mô hình AI học hỏi và cải thiện. Hướng tiếp cận này giúp Apple nâng cao khả năng dự đoán văn bản mà không thu thập hoặc lưu trữ dữ liệu người dùng nhạy cảm tập trung.
Tóm tắt
Bảo mật, tuân thủ và quyền riêng tư là những yếu tố không thể tách rời trong hành trình dữ liệu AI-ready. Bằng cách thực thi các biện pháp kiểm soát bảo mật mạnh mẽ, đảm bảo tuân thủ quy định, bảo vệ quyền riêng tư trong khi duy trì giá trị và lưu giữ nhật ký kiểm toán chi tiết, các tổ chức có thể tự tin khai thác sức mạnh của GenAI và agentic AI. Những thực hành này không chỉ giảm rủi ro và hỗ trợ tuân thủ mà còn xây dựng lòng tin thiết yếu cho việc áp dụng AI có trách nhiệm và bền vững.
Tạo Điều Kiện Chia Sẻ Thông Tin và Cộng Tác — Chi Tiết (Enabling Information Sharing and Collaboration)
Generative AI và agentic AI tạo ra giá trị lớn nhất từ khả năng nhận ra các mô hình, tạo ra hiểu biết và tự động hóa các hành động vượt qua ranh giới tổ chức truyền thống. Để khai phá tiềm năng này, tổ chức phải áp dụng một khung ưu tiên chia sẻ thông tin và cộng tác, phá vỡ silo và hỗ trợ quyền truy cập nhanh chóng, có quản trị vào dữ liệu (Hình 2-7).
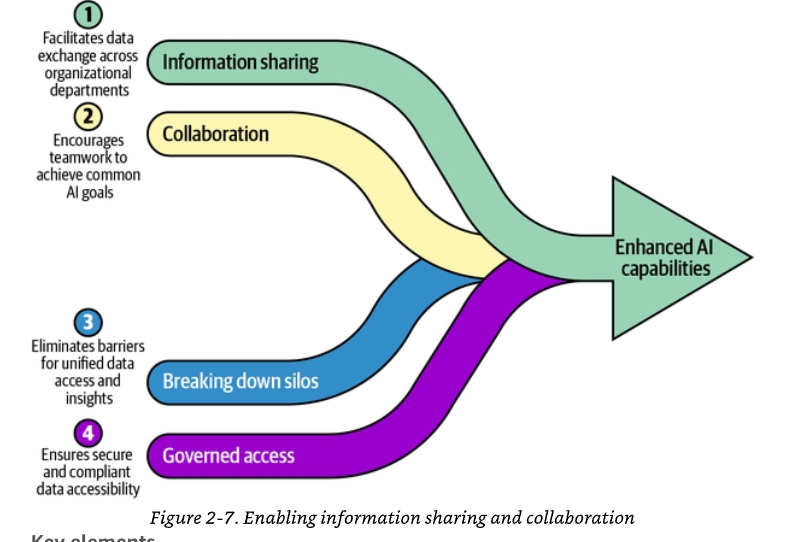
Hình 2-7. Bốn yếu tố hội tụ tạo ra năng lực AI nâng cao: ① Chia sẻ thông tin (Information sharing — thúc đẩy trao đổi dữ liệu xuyên phòng ban); ② Cộng tác (Collaboration — khuyến khích làm việc nhóm để đạt mục tiêu AI chung); ③ Phá vỡ silo (Breaking down silos — loại bỏ rào cản truy cập dữ liệu thống nhất); ④ Truy cập có quản trị (Governed access — đảm bảo khả năng truy cập dữ liệu an toàn và tuân thủ).
Các yếu tố then chốt
Phá vỡ silo dữ liệu (Break down data silos)
Thúc đẩy chia sẻ dữ liệu giữa các phòng ban và triển khai các nền tảng dữ liệu thống nhất được hỗ trợ bởi quản lý siêu dữ liệu và lập danh mục dữ liệu vững chắc:
- Các hệ thống AI hiệu quả nhất khi có thể truy cập dữ liệu từ nhiều đơn vị kinh doanh — bán hàng, marketing, vận hành, tài chính, v.v. — để khám phá những hiểu biết vẫn ẩn trong các tập dữ liệu riêng lẻ
- Triển khai các nền tảng dữ liệu tập trung hoặc liên kết (federated) cho phép các nhóm đóng góp và lấy dữ liệu từ một kho dữ liệu chung chất lượng cao, có quản trị — giảm trùng lặp và không nhất quán
- Sử dụng danh mục dữ liệu doanh nghiệp để các tài sản dữ liệu có thể khám phá và hiểu được giữa các nhóm, đảm bảo ngữ cảnh và nguồn gốc được bảo tồn
Tạo điều kiện thay vì hạn chế (Enable rather than restrict)
Triển khai quyền truy cập tự phục vụ có quản trị, kiểm soát dựa trên vai trò và ngữ cảnh, cùng các nền tảng cộng tác hỗ trợ sử dụng dữ liệu có trách nhiệm:
- Cung cấp cho các nhóm quyền truy cập nhanh, có quản trị vào dữ liệu — cân bằng giữa nhu cầu bảo mật và tuân thủ với yêu cầu linh hoạt và đổi mới
- Triển khai kiểm soát truy cập chi tiết trao quyền cho người dùng truy cập dữ liệu họ cần trong khi bảo vệ tài sản nhạy cảm và đảm bảo tuân thủ
- Áp dụng các nền tảng cộng tác tích hợp với hệ thống quản lý dữ liệu, cho phép cả người dùng kỹ thuật lẫn phi kỹ thuật chia sẻ, chú thích và thảo luận về dữ liệu theo thời gian thực
Thúc đẩy văn hóa cộng tác (Promote a culture of collaboration)
Cung cấp quản lý dữ liệu liên chức năng, tài liệu minh bạch và các vòng phản hồi có cấu trúc để liên tục cải thiện chất lượng và độ tin cậy của dữ liệu:
- Khuyến khích các nhóm kinh doanh và kỹ thuật cùng sở hữu và quản lý tài sản dữ liệu, đảm bảo sự đồng thuận về định nghĩa dữ liệu, tiêu chuẩn chất lượng và chính sách sử dụng
- Duy trì tài liệu rõ ràng và quy trình minh bạch cho việc chia sẻ dữ liệu để người dùng hiểu nguồn gốc, các chuyển đổi và giới hạn của dữ liệu
- Thiết lập cơ chế để người dùng dữ liệu cung cấp phản hồi cho nhà xuất bản dữ liệu, tạo ra vòng cải thiện liên tục và tăng cường lòng tin
Thực hành triển khai tốt nhất
Các thực hành tốt nhất này đảm bảo chia sẻ dữ liệu được hợp lý hóa nhưng vẫn có quản trị, cộng tác được khuyến khích trong khi duy trì bảo mật, và cả người dùng kỹ thuật lẫn phi kỹ thuật đều có thể đóng góp và hưởng lợi từ trí tuệ tập thể của tổ chức:
Áp dụng các nền tảng quản lý dữ liệu do AI hỗ trợ (Adopt AI-powered data management platforms)
Tận dụng các nền tảng tự động hóa việc khám phá dữ liệu, cấp phát quyền truy cập và thực thi chính sách — giúp các nhóm dễ dàng tìm và sử dụng dữ liệu có trách nhiệm.
Tự động hóa giám sát truy cập dữ liệu (Automate data access monitoring)
Sử dụng các công cụ tự động để giám sát và kiểm toán truy cập dữ liệu — đảm bảo tuân thủ trong khi giảm thiểu cản trở cho người dùng hợp lệ.
Chuẩn hóa định dạng và ngữ nghĩa dữ liệu (Standardize data formats and semantics)
Đảm bảo dữ liệu được chia sẻ giữa các phòng ban tuân thủ các chuẩn và từ vựng chung — hỗ trợ tích hợp và diễn giải liền mạch.
Khuyến khích năng lực hiểu biết dữ liệu (Encourage data literacy)
Đầu tư vào các chương trình đào tạo giúp tất cả nhân viên hiểu cách truy cập, diễn giải và sử dụng dữ liệu dùng chung hiệu quả và có trách nhiệm.
Ví dụ thực tế
Truy cập dữ liệu và cộng tác với AI (Data access and collaboration with AI)
Các tổ chức như Paycor và Holiday Inn Club Vacation sử dụng quản lý dữ liệu do AI hỗ trợ để dân chủ hóa quyền truy cập dữ liệu và thúc đẩy cộng tác — hỗ trợ ra quyết định nhanh hơn và có thông tin hơn trong khi duy trì bảo mật và tuân thủ.
Kỹ thuật tác tử AI (AI agent engineering)
Bằng cách điều phối các luồng công việc tác tử thông minh trên các hệ sinh thái lai, Wescom Financial trao quyền cho cả nhóm kỹ thuật lẫn kinh doanh để truy cập và hành động dựa trên dữ liệu đáng tin cậy — đẩy nhanh tự động hóa và đổi mới mà không cần lập trình phức tạp.
Sẵn sàng cho AI (AI readiness)
Khung sẵn sàng AI của Open Data Institute nhấn mạnh tầm quan trọng của đối thoại và phản hồi liên tục giữa nhà xuất bản và người dùng dữ liệu — đảm bảo các thực hành dữ liệu phát triển đáp ứng nhu cầu thực tế và nuôi dưỡng văn hóa dữ liệu cộng tác.
Tóm tắt
Tạo điều kiện chia sẻ thông tin và cộng tác là điều thiết yếu để tối đa hóa tác động của các hệ thống GenAI và agentic AI. Bằng cách phá vỡ silo dữ liệu, cho phép truy cập tự phục vụ có quản trị và nuôi dưỡng văn hóa cộng tác, các tổ chức có thể đẩy nhanh tạo ra hiểu biết, thúc đẩy đổi mới và đảm bảo các sáng kiến AI mang lại giá trị trên toàn doanh nghiệp. Khung này không chỉ hỗ trợ tích hợp kỹ thuật mà còn khuyến khích tư duy tổ chức và các thực hành cần thiết để AI thành công bền vững.
Hỗ Trợ Mở Rộng Quy Mô và Hiệu Suất — Chi Tiết (Supporting Scale and Performance)
Các triển khai GenAI và agentic AI cấp doanh nghiệp đòi hỏi các khung có thể mở rộng hiệu quả và đảm bảo hiệu suất cao. Khi khối lượng dữ liệu tăng vọt và thông tin thời gian thực trở thành yếu tố then chốt, các hướng tiếp cận vững chắc về quy mô và hiệu suất là thiết yếu cho cả độ tin cậy lẫn đổi mới. Phần này phác thảo các yếu tố then chốt, thực hành tốt nhất và các cân nhắc ngữ cảnh để hỗ trợ mở rộng quy mô và hiệu suất trong các môi trường dữ liệu AI-ready (Hình 2-8).
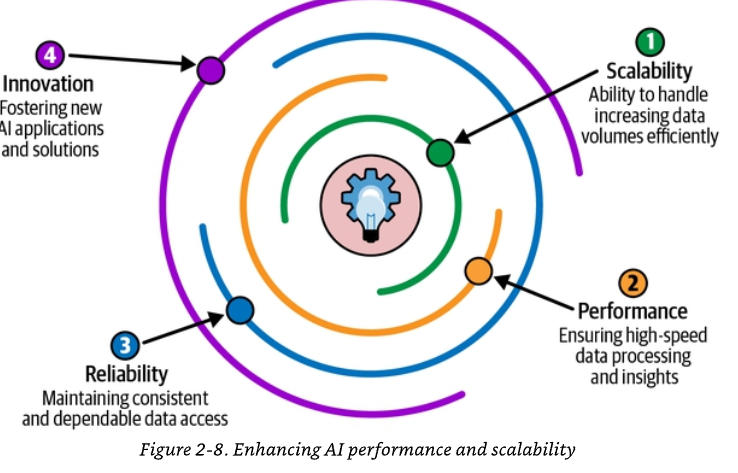
Các Yếu Tố Then Chốt
Chúng ta sẽ xem xét các yếu tố then chốt trong khung hỗ trợ mở rộng quy mô và hiệu suất trong các hệ thống dữ liệu AI-ready. Phần này phác thảo các thành phần thiết yếu giúp các tổ chức xử lý khối lượng dữ liệu lớn, cung cấp khả năng xử lý thời gian thực và tối ưu hóa sử dụng tài nguyên cho các hệ thống GenAI và agentic AI. Các yếu tố này rất quan trọng để đảm bảo hệ thống dữ liệu duy trì hiệu quả, tiết kiệm chi phí và có khả năng cung cấp thông tin hành động ở quy mô doanh nghiệp.
Xử lý khối lượng dữ liệu lớn (Handle massive data volumes)
Thiết kế kiến trúc cho khối lượng dữ liệu lớn với khả năng mở rộng đàn hồi (elastic scalability), nền tảng dữ liệu phân tán và các đường ống nhập liệu hiệu suất cao có khả năng duy trì khối lượng công việc ở quy mô AI:
-
Tất cả các hệ thống phải đáp ứng các tập dữ liệu tăng trưởng nhanh — có cấu trúc, phi cấu trúc và đa phương thức — mà không suy giảm hiệu suất. Điều này đòi hỏi hạ tầng đàn hồi có thể điều chỉnh linh hoạt tài nguyên lưu trữ và tính toán theo nhu cầu.
-
Tận dụng các cơ sở dữ liệu phân tán, data lake và các giải pháp lưu trữ cloud native cho phép xử lý song song và truy cập dữ liệu hiệu quả, kể cả khi khối lượng dữ liệu tăng theo cấp số nhân.
-
Các đường ống nhập liệu thông lượng cao (high-throughput ingestion pipelines) là cần thiết để liên tục cung cấp dữ liệu mới cho cả các mô hình lớn lẫn nhỏ, hỗ trợ cả xử lý theo lô (batch) lẫn luồng (streaming).
Cung cấp khả năng xử lý thời gian thực (Provide real-time processing capabilities)
Kích hoạt xử lý thời gian thực thông qua các đường ống độ trễ thấp (low-latency pipelines), kiến trúc hướng sự kiện (event-driven architectures) và mô hình xử lý edge hoặc hybrid hỗ trợ các hệ thống AI phản hồi nhanh:
-
Các đường ống được tối ưu hóa cho độ trễ tối thiểu — từ nhập dữ liệu đến suy luận mô hình — là yêu cầu bắt buộc để hỗ trợ thông tin và hành động thời gian thực.
-
Áp dụng các khung hướng sự kiện cho phép hệ thống AI phản ứng tức thì với dữ liệu hoặc tín hiệu mới, đặc biệt quan trọng với agentic AI phải tự động phản hồi các môi trường thay đổi.
-
Đối với các ứng dụng đòi hỏi độ trễ cực thấp (ví dụ: IoT, hệ thống tự hành), xử lý dữ liệu tại edge hoặc trong môi trường cloud hybrid có thể giảm độ trễ hơn nữa.
Tối ưu hóa sử dụng tài nguyên (Optimize resource utilization)
Triển khai phân bổ động (dynamic allocation), thiết kế hạ tầng tiết kiệm chi phí và giám sát tích hợp để cân bằng hiệu suất và hiệu quả:
-
Khối lượng công việc AI thường có tính đột biến và khó dự đoán. Các công cụ điều phối tự động (ví dụ: Kubernetes, serverless platforms) có thể phân bổ tài nguyên theo nhu cầu, tối đa hóa hiệu quả và giảm thiểu tài nguyên nhàn rỗi.
-
Đặt tải công việc thông minh, lưu trữ phân tầng (tiered storage) và tối ưu hóa mô hình (ví dụ: quantization, pruning) giúp kiểm soát chi phí trong khi duy trì hiệu suất.
-
Giám sát liên tục hiệu suất hệ thống, mức sử dụng tài nguyên và các điểm nghẽn cổ chai đảm bảo các chiến lược mở rộng quy mô luôn hiệu quả và tối ưu theo thời gian.
Thực Hành Tốt Nhất Khi Triển Khai
Sau đây là các chiến lược thực tiễn và cách tiếp cận đã được kiểm chứng để triển khai hạ tầng dữ liệu có khả năng mở rộng và hiệu suất cao. Phần này cung cấp hướng dẫn hành động để các tổ chức triển khai và duy trì hiệu quả các thành phần khung quan trọng này. Các thực hành tốt nhất đảm bảo kiến trúc dữ liệu có thể thích ứng linh hoạt với nhu cầu ngày càng tăng, hỗ trợ hoạt động độ trễ thấp và quản lý tài nguyên hiệu quả trên các khối lượng công việc AI phức tạp:
Áp dụng kiến trúc cloud native và phân tán (Adopt cloud native and distributed architectures)
Sử dụng các dịch vụ cloud native và khung tính toán phân tán (như Apache Spark, Databricks hoặc các nền tảng AI cloud) để hỗ trợ mở rộng đàn hồi và tính sẵn sàng cao.
Tự động hóa quản lý đường ống dữ liệu (Automate data pipeline management)
Sử dụng các công cụ điều phối để tự động hóa nhập dữ liệu, biến đổi và phân phối, đảm bảo các đường ống có thể mở rộng liền mạch khi khối lượng dữ liệu tăng.
Tận dụng bộ nhớ đệm và phân vùng dữ liệu (Leverage caching and data partitioning)
Sử dụng các chiến lược bộ nhớ đệm và phân vùng dữ liệu thông minh để giảm thời gian truy cập và cân bằng tải trên toàn hạ tầng.
Tích hợp các công cụ phân tích thời gian thực (Integrate real-time analytics engines)
Kết hợp các công cụ phân tích thời gian thực (như Apache Kafka, Flink hoặc các giải pháp cloud native tương đương) để kích hoạt xử lý dữ liệu độ trễ thấp liên tục và phục vụ mô hình.
Liên tục đánh giá chuẩn và tinh chỉnh (Continuously benchmark and tune)
Thường xuyên đánh giá chuẩn hiệu suất hệ thống và tinh chỉnh cấu hình, tận dụng các công cụ giám sát chuyên dụng cho AI để xác định và giải quyết điểm nghẽn.
Ví Dụ Thực Tế
GenAI trong thương mại điện tử (GenAI in ecommerce)
Các nhà bán lẻ lớn sử dụng data lake phân tán và phân tích thời gian thực để cá nhân hóa đề xuất cho hàng triệu người dùng đồng thời, mở rộng quy mô trong các giai đoạn mua sắm cao điểm mà không làm giảm chất lượng dịch vụ.
Agentic AI trong IoT công nghiệp (Agentic AI in industrial IoT)
Các công ty sản xuất triển khai các tác tử AI agentic tại edge để giám sát tình trạng thiết bị theo thời gian thực, kích hoạt hành động bảo trì ngay lập tức và tối ưu hóa sử dụng tài nguyên trên hàng nghìn thiết bị.
Dịch vụ tài chính (Financial services)
Các ngân hàng xử lý hàng tỷ giao dịch mỗi ngày, sử dụng kiến trúc cloud native hướng sự kiện để phát hiện gian lận theo thời gian thực và mở rộng hạ tầng linh hoạt trong các sự kiện lưu lượng cao (ví dụ: Black Friday, mùa thuế).
Tóm Tắt
Hỗ trợ mở rộng quy mô và hiệu suất là yếu tố thiết yếu cho sự thành công của các hệ thống GenAI và agentic AI cấp doanh nghiệp. Bằng cách xử lý khối lượng dữ liệu lớn, kích hoạt xử lý thời gian thực và tối ưu hóa sử dụng tài nguyên, các tổ chức có thể đảm bảo các sáng kiến AI duy trì vững chắc, tiết kiệm chi phí và có khả năng cung cấp thông tin hành động ở bất kỳ quy mô nào. Khung này là nền tảng để khai thác toàn bộ tiềm năng của dữ liệu AI-ready trong các môi trường năng động, giàu dữ liệu.
Quản Lý Dữ Liệu Như Một Sản Phẩm Chiến Lược (Managing Data as a Strategic Product)
Coi dữ liệu như một sản phẩm chiến lược (strategic product) là điều cơ bản để hiện thực hóa toàn bộ tiềm năng của các hệ thống GenAI và agentic AI. Khung được trình bày ở đây nâng tầm quản lý dữ liệu từ một nhiệm vụ kỹ thuật lên thành một kỷ luật toàn doanh nghiệp, nhấn mạnh quản lý tích cực (active stewardship), cải tiến liên tục và — quan trọng nhất — tư duy sản phẩm dữ liệu (data product thinking). Cách tiếp cận này biến đổi cách dữ liệu được tạo ra, duy trì và sử dụng, đảm bảo mang lại giá trị kinh doanh bền vững và sẵn sàng cho AI (Hình 2-9).
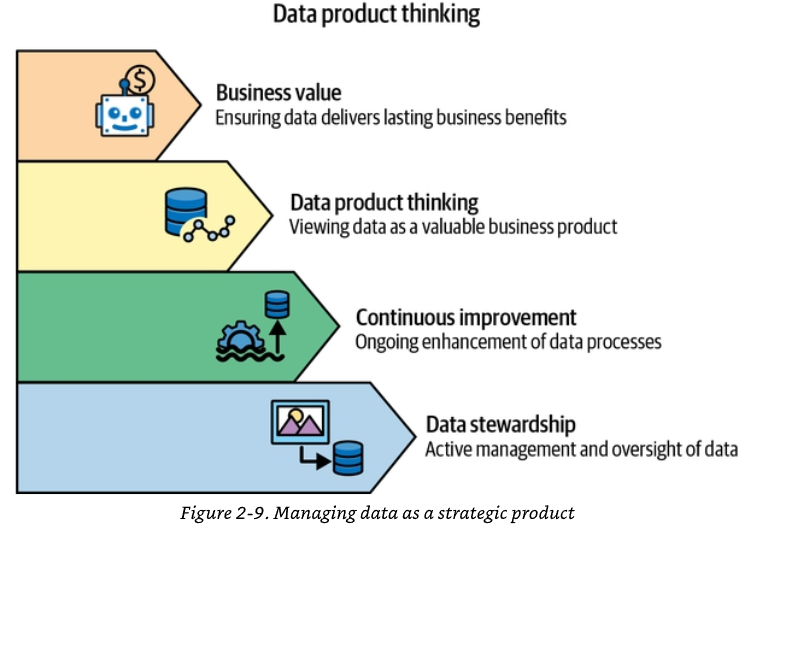
TẠI SAO TƯ DUY SẢN PHẨM DỮ LIỆU LÀ THIẾT YẾU
Tư duy sản phẩm dữ liệu đánh dấu một sự chuyển đổi căn bản: dữ liệu được quản lý có chủ đích như một sản phẩm, chứ không phải được coi như phụ phẩm. Mỗi sản phẩm dữ liệu có chủ sở hữu rõ ràng, người tiêu dùng được xác định, tiêu chuẩn chất lượng đo lường được và vòng đời phù hợp với cả mục tiêu kinh doanh lẫn AI.
Sản phẩm dữ liệu rất quan trọng cho các hệ thống GenAI và agentic AI, đóng vai trò là các container chuyên biệt chứa trí tuệ theo miền chuyên ngành (domain-specific intelligence). Chúng thu hẹp khoảng cách giữa dữ liệu phân tán và các quy trình làm việc liên phòng ban bằng cách hoạt động như các nguồn thông tin ngữ cảnh và chuyên ngành có giới hạn. Điều này cho phép các tác tử truy vấn, diễn giải và hiểu dữ liệu trên các miền khác nhau một cách nhất quán và hiệu quả.
Bằng cách tận dụng một nền tảng sản phẩm dữ liệu thống nhất với các tầng ngữ nghĩa (semantic layers), các tổ chức có thể chuẩn hóa cách các thuật ngữ được định nghĩa và diễn giải, đảm bảo cả LLM lẫn các tác tử AI đều có thể truy cập các chỉ số theo cách nhất quán. Sự chuẩn hóa này đặc biệt quan trọng cho các chức năng liên miền, vì nó hỗ trợ quản trị dữ liệu vững chắc, nâng cao hiểu biết ngữ nghĩa và tạo điều kiện xây dựng đồ thị tri thức (knowledge graphs) liên kết các thực thể trên các miền.
Cuối cùng, sản phẩm dữ liệu giải quyết các thách thức phổ biến về silo dữ liệu và thuật ngữ không nhất quán — những yếu tố thường cản trở hiệu quả của các hệ thống AI trong môi trường kinh doanh phức tạp.
Các Yếu Tố Then Chốt
Chúng ta sẽ xem xét các yếu tố then chốt trong khung quản lý dữ liệu như một sản phẩm chiến lược trong môi trường AI-ready. Phần này phác thảo các thành phần thiết yếu giúp các tổ chức coi dữ liệu như một tài sản có giá trị, quản lý tích cực vòng đời của nó và liên tục cải thiện chất lượng cũng như sự phù hợp cho các ứng dụng AI. Các yếu tố này rất quan trọng để đảm bảo dữ liệu mang lại giá trị kinh doanh bền vững và phù hợp để hỗ trợ các hệ thống GenAI và agentic AI tiên tiến:
Theo dõi mức sử dụng và nhu cầu dữ liệu (Track data usage and needs)
Theo dõi cách các nhóm và hệ thống AI sử dụng dữ liệu để xác định khoảng cách, dư thừa và cơ hội cải thiện. Phân tích có hệ thống các mẫu sử dụng để ưu tiên cải tiến, loại bỏ các tập dữ liệu lỗi thời và đảm bảo đầu tư dữ liệu phù hợp với các yêu cầu kinh doanh và AI không ngừng phát triển.
Phiên bản hóa và phát triển dữ liệu (Version and evolve data)
Duy trì các phiên bản lịch sử của dữ liệu để nắm bắt cách các quyết định, logic kinh doanh và cấu trúc dữ liệu thay đổi theo thời gian. Thực hành này hỗ trợ khả năng kiểm toán, tuân thủ quy định và minh bạch — những yếu tố then chốt cho khả năng giải thích và độ tin cậy của AI.
Gắn nhãn chất lượng dữ liệu (Brand quality data)
Chỉ rõ các tập dữ liệu nào đáp ứng tiêu chuẩn chất lượng và quản trị, giúp người dùng và hệ thống AI dễ dàng xác định dữ liệu "đáng tin cậy". Gắn nhãn dữ liệu theo cách này khuyến khích sử dụng đúng cách và tăng cường sự tin tưởng vào kết quả đầu ra của AI.
Thực Hành Tốt Nhất Khi Triển Khai
Sau đây là các chiến lược thực tiễn và cách tiếp cận đã được kiểm chứng để triển khai các thực hành quản lý sản phẩm dữ liệu. Phần này cung cấp hướng dẫn hành động để các tổ chức triển khai và duy trì hiệu quả các thành phần khung quan trọng này. Các thực hành tốt nhất đảm bảo dữ liệu được tuyển chọn, phiên bản hóa và phát triển có hệ thống, với quyền sở hữu rõ ràng, tiêu chuẩn chất lượng được xác định và các chỉ số giá trị đo lường được phù hợp với cả mục tiêu kinh doanh lẫn AI:
Thiết lập danh mục sản phẩm dữ liệu (Establish data product catalogs)
Sử dụng các danh mục dữ liệu hiện đại (ví dụ: Collibra, DataHub, Atlan) để đăng ký, ghi lại tài liệu và giám sát sản phẩm dữ liệu, giúp chúng có thể khám phá và đáng tin cậy.
Tự động hóa kiểm soát chất lượng và quan sát dữ liệu (Automate data quality and observability)
Tích hợp các công cụ (ví dụ: Soda Core, Great Expectations, Monte Carlo) để tự động hóa kiểm tra chất lượng và quan sát, công bố các mục tiêu mức dịch vụ (SLO) và chỉ số mức dịch vụ (SLI) cho từng sản phẩm dữ liệu.
Xây dựng nhóm liên chức năng (Foster cross-functional teams)
Xây dựng các nhóm lâu dài trải dài qua các vai trò kinh doanh và kỹ thuật, cùng sở hữu vòng đời và cung cấp giá trị của sản phẩm dữ liệu.
Gắn nhãn và chứng nhận dữ liệu đáng tin cậy (Brand and certify trusted data)
Dán nhãn rõ ràng các sản phẩm dữ liệu đáp ứng tiêu chuẩn quản trị và chất lượng, đồng thời cung cấp tính minh bạch về nguồn gốc, mức sử dụng và trạng thái tuân thủ.
Lặp lại với phản hồi (Iterate with feedback)
Liên tục thu thập và hành động dựa trên phản hồi từ người tiêu dùng dữ liệu và các chuyên gia AI để phát triển sản phẩm dữ liệu và giải quyết các nhu cầu mới nổi.
Ví Dụ Thực Tế
Để minh họa ứng dụng thực tiễn của việc quản lý dữ liệu như một sản phẩm chiến lược trong môi trường AI, hãy xem xét một số ví dụ thực tế từ các tổ chức hàng đầu. Các nghiên cứu điển hình này minh chứng cách các yếu tố then chốt của khung này đã được triển khai để thúc đẩy đổi mới, cải thiện ra quyết định và tạo ra các luồng giá trị mới thông qua các sáng kiến AI lấy dữ liệu làm trung tâm:
Theo dõi mức sử dụng và nhu cầu dữ liệu (Tracking data usage and needs)
Các tổ chức tài chính hàng đầu như Capital One đang xây dựng các hệ sinh thái dữ liệu AI-ready cung cấp khả năng quan sát phong phú về cách các nhóm và hệ thống AI sử dụng tài sản dữ liệu. Bằng cách phân tích các mẫu sử dụng trên các tập dữ liệu, họ có thể xác định dữ liệu nào có giá trị nhất cho các ứng dụng AI, khoảng cách nào tồn tại trong phạm vi phủ sóng và tập dữ liệu nào đang không được sử dụng hoặc lỗi thời. Loại quản lý dữ liệu theo định hướng hiểu biết này giảm lưu trữ dư thừa và cải thiện hiệu suất mô hình AI bằng cách cho phép lựa chọn và ưu tiên dữ liệu tốt hơn.
Phiên bản hóa và phát triển dữ liệu (Versioning and evolving data)
LinkedIn đã phát triển DataHub, một nền tảng metadata mã nguồn mở theo dõi các tập dữ liệu, lược đồ, đặc trưng, bảng điều khiển và mô hình AI, cùng với các mối quan hệ và thay đổi của chúng theo thời gian. DataHub cung cấp lịch sử lược đồ và dữ liệu dòng đầu đến cuối (end-to-end data lineage), cho phép các nhóm thấy cách lược đồ phát triển và cách dữ liệu chảy qua các đường ống và hệ thống phân tích. Những khả năng này giúp các nhóm dữ liệu và AI duy trì độ chính xác của mô hình và hỗ trợ khả năng giải thích bằng cách cung cấp tầm nhìn rõ ràng vào các tập dữ liệu, phép biến đổi và các thay đổi lược đồ lịch sử làm nền tảng cho các đề xuất và đầu ra mô hình khác.
Gắn nhãn chất lượng dữ liệu (Branding quality data)
American Express đặt trọng tâm mạnh mẽ vào chất lượng dữ liệu và quản trị để hỗ trợ các sáng kiến AI và phân tích, đặc biệt trong phát hiện gian lận và mô hình rủi ro. Bằng cách đầu tư vào các thực hành quản lý dữ liệu vững chắc và dữ liệu huấn luyện chất lượng cao, công ty đã đạt được những cải tiến đáng kể về độ chính xác phát hiện gian lận và hiệu suất mô hình rủi ro.
Tóm Tắt
Quản lý dữ liệu như một sản phẩm chiến lược — được hỗ trợ bởi tư duy sản phẩm dữ liệu — là yếu tố kích hoạt quan trọng nhất cho dữ liệu AI-ready. Cách tiếp cận này đảm bảo dữ liệu được quản lý tích cực, đáng tin cậy và được xây dựng có mục đích cho AI và giá trị kinh doanh. Bằng cách coi dữ liệu là một sản phẩm, các tổ chức có thể phá vỡ silo, thúc đẩy đổi mới và cung cấp các giải pháp AI đáng tin cậy, tuân thủ và có tác động cao ở quy mô lớn.
Trao Quyền Người Dùng Qua Tài Liệu và Hướng Dẫn (Empowering Users with Documentation and Guidance)
Tài liệu và hướng dẫn là thiết yếu cho cả người dùng lẫn hệ thống AI. Khi việc áp dụng AI tăng tốc, sự phức tạp của các hệ thống dữ liệu ngày càng tăng, và nhu cầu về tài liệu rõ ràng, dễ tiếp cận, đáng tin cậy và cập nhật trở thành yếu tố khác biệt chiến lược. Thành phần cuối cùng này của khung dữ liệu AI-ready đảm bảo rằng dữ liệu không chỉ khả dụng mà còn đáng tin cậy và có thể sử dụng được cho đổi mới được thúc đẩy bởi AI (Hình 2-10).
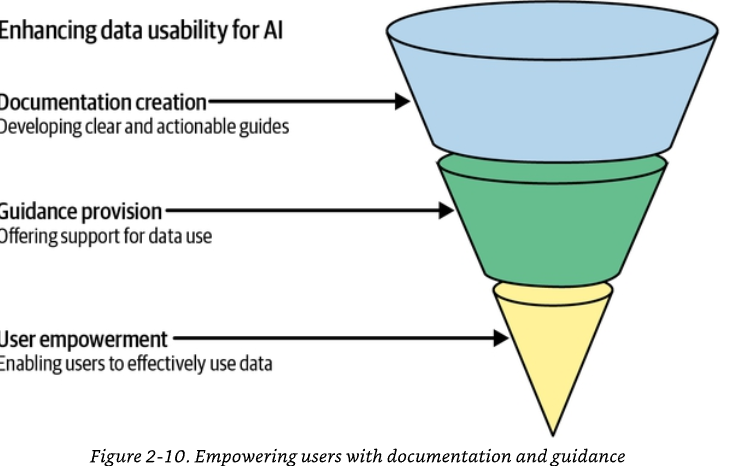
Các Yếu Tố Then Chốt
Chúng ta sẽ xem xét các yếu tố then chốt trong khung trao quyền người dùng qua tài liệu và hướng dẫn trong môi trường dữ liệu AI-ready. Phần này phác thảo các thành phần thiết yếu giúp các tổ chức tạo ra tài liệu chất lượng cao và cập nhật cho cả người dùng lẫn hệ thống AI. Các yếu tố này rất quan trọng để đảm bảo tài sản dữ liệu không chỉ khả dụng mà còn dễ hiểu, hỗ trợ cộng tác hiệu quả và thúc đẩy sử dụng tốt GenAI và agentic AI:
Tạo hướng dẫn rõ ràng, hành động được (Create clear, actionable guides)
Tạo tài liệu kết nối tài sản dữ liệu trực tiếp với các lựa chọn kinh doanh và làm nổi bật những gì quan trọng nhất. Tài liệu nên giải thích nguồn dữ liệu, định nghĩa, các trường hợp sử dụng dự định và bất kỳ quy tắc kinh doanh hoặc phép biến đổi nào được áp dụng. Hướng dẫn rõ ràng giúp người dùng và các chuyên gia AI đưa ra quyết định có thông tin, giảm sự mơ hồ và rủi ro diễn giải sai.
Duy trì tài liệu cập nhật (Keep documentation current)
Tài liệu cập nhật là điều quan trọng để hỗ trợ đào tạo lại mô hình AI, kiểm toán tuân thủ và thích ứng với các thay đổi quy định hoặc vận hành. Liên tục cập nhật hướng dẫn khi dữ liệu, quy trình và nhu cầu kinh doanh phát triển, đảm bảo người dùng và hệ thống AI luôn làm việc với thông tin mới nhất. Duy trì kiểm soát phiên bản và nhật ký thay đổi để theo dõi các cập nhật và đảm bảo tính minh bạch.
Thực Hành Tốt Nhất Khi Triển Khai
Sau đây là các chiến lược thực tiễn và cách tiếp cận đã được kiểm chứng để triển khai các thực hành tài liệu và hướng dẫn vững chắc. Phần này cung cấp hướng dẫn hành động để các tổ chức tạo ra, duy trì và phổ biến tài liệu rõ ràng và cập nhật một cách hiệu quả. Các thực hành tốt nhất này đảm bảo người dùng và hệ thống AI có thể tự tin tận dụng tài sản dữ liệu, hiểu bối cảnh và giới hạn của chúng, và tuân thủ các chính sách quản trị:
Chuẩn hóa thực hành tài liệu (Standardize documentation practices)
Sử dụng mẫu và danh sách kiểm tra để đảm bảo nhất quán trên các tập dữ liệu, bao gồm các phần cho định nghĩa dữ liệu, bối cảnh kinh doanh, chỉ số chất lượng và hướng dẫn sử dụng.
Tích hợp tài liệu với danh mục dữ liệu (Integrate documentation with data catalogs)
Làm cho tài liệu có thể khám phá cùng với tài sản dữ liệu trong các danh mục hoặc cổng thông tin doanh nghiệp để người dùng và hệ thống AI có thể dễ dàng truy cập thông tin họ cần.
Tự động hóa cập nhật tài liệu (Automate documentation updates)
Tận dụng các công cụ quản lý metadata để tự động hóa việc ghi lại các thay đổi lược đồ, dữ liệu dòng và chỉ số chất lượng, giảm nỗ lực thủ công và giảm thiểu thông tin lỗi thời.
Khuyến khích đối thoại liên tục (Encourage continuous dialogue)
Thiết lập các kênh phản hồi để người dùng đề xuất cải tiến hoặc gắn cờ vấn đề, thúc đẩy cách tiếp cận hợp tác đối với tài liệu và quản lý dữ liệu.
Đào tạo nhóm về tiêu chuẩn tài liệu (Train teams on documentation standards)
Đảm bảo cả nhà xuất bản lẫn người tiêu dùng dữ liệu đều hiểu tầm quan trọng của tài liệu và được trang bị để đóng góp vào việc tạo và duy trì tài liệu.
Ví Dụ Thực Tế
Tạo hướng dẫn rõ ràng, hành động được (Creating clear, actionable guides)
Netflix đã xây dựng các cổng thông tin dữ liệu nội bộ trên nền tảng metadata Metacat để giúp tài sản dữ liệu lớn dễ khám phá và dễ hiểu hơn trong toàn công ty. Các cổng thông tin này cung cấp metadata kỹ thuật và kinh doanh về tập dữ liệu và chỉ số (như lược đồ, quyền sở hữu, thẻ và thông tin vòng đời), giúp các nhóm phân tích và sản phẩm tìm đúng dữ liệu và hiểu cách sử dụng trong báo cáo và ra quyết định. Bằng cách cải thiện khám phá dữ liệu và hiểu biết chung về các chỉ số quan trọng, Netflix giảm rủi ro diễn giải sai và giúp thành viên mới nhanh chóng làm việc hiệu quả với dữ liệu.
Duy trì tài liệu cập nhật (Keeping documentation current)
Microsoft cung cấp tài liệu chi tiết, được cập nhật thường xuyên và hướng dẫn vòng đời cho các dịch vụ Azure AI, bao gồm chính sách phiên bản mô hình và nâng cấp giúp khách hàng theo dõi các thay đổi đối với mô hình và API. Azure cũng duy trì nguồn cập nhật tập trung thông báo cho người dùng khi dịch vụ thay đổi hoặc có khả năng mới, giúp giảm độ trễ giữa các bản cập nhật nền tảng và triển khai của khách hàng.
Chuẩn hóa thực hành tài liệu (Standardizing documentation practices)
Nhiều nhóm kỹ thuật cloud, bao gồm cả những nhóm làm việc với Google Cloud, áp dụng phương pháp "tài liệu như mã" (documentation as code) trong đó tài liệu được lưu trữ trong kiểm soát phiên bản cùng với mã nguồn, được xem xét như các thay đổi mã và thường được xác thực bằng kiểm tra tự động. Mẫu chuẩn hóa và nội dung có cấu trúc giúp dễ dàng bao gồm các phần nhất quán như định nghĩa, ví dụ và giới hạn, cải thiện chất lượng tài liệu và giảm thời gian tìm kiếm thông tin.
Tóm Tắt
Trao quyền người dùng qua tài liệu và hướng dẫn là trụ cột nền tảng cho dữ liệu AI-ready. Bằng cách tạo tài liệu rõ ràng, hành động được và cập nhật, các tổ chức đảm bảo cả con người lẫn hệ thống AI đều có thể tự tin tận dụng dữ liệu cho đổi mới, tuân thủ và giá trị kinh doanh. Khung này không chỉ hỗ trợ xuất sắc kỹ thuật mà còn nuôi dưỡng văn hóa minh bạch, tin tưởng và cải tiến liên tục — những thành phần chính cho thành công của AI.
Bản Thiết Kế AI-Ready Data cho Khung Dữ Liệu: Hướng Dẫn Triển Khai Thực Tiễn
Sau đây là một số bản thiết kế hành động (actionable blueprints) để triển khai các hệ thống GenAI và agentic AI trong môi trường doanh nghiệp, dựa trên khung dữ liệu AI-ready toàn diện đã thảo luận trong chương này.
Bản Thiết Kế 1: Công Cụ Trí Tuệ Bối Cảnh Kinh Doanh (Blueprint 1: Business Context Intelligence Engine)
Mục tiêu: Thu thập và vận hành hóa có hệ thống logic kinh doanh, bối cảnh quyết định và tri thức tổ chức cho các hệ thống AI (Hình 2-11).
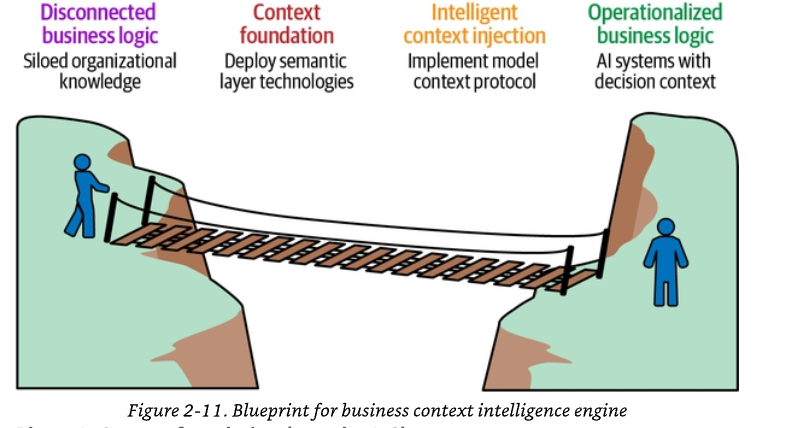
Giai đoạn 1: Xây dựng nền tảng cốt lõi (tháng 1-2)
Thiết lập hạ tầng cốt lõi
- Triển khai công nghệ tầng ngữ nghĩa (semantic layer technologies).
- Triển khai nền tảng đồ thị tri thức (ví dụ: Amazon Neptune).
- Thiết lập hệ thống quản lý từ điển thuật ngữ kinh doanh.
- Tạo cấu trúc phân loại phân cấp (hierarchical taxonomy structures).
Hành động then chốt
- Ghi lại các quy trình ra quyết định cùng cơ sở lý luận hỗ trợ.
- Ánh xạ các khái niệm kinh doanh sang các trường dữ liệu sử dụng từ điển kiểm soát.
- Xây dựng hệ thống theo dõi gia phả quyết định (decision genealogy tracking).
- Tạo các lược đồ metadata ngữ cảnh.
Chỉ số thành công
- 100% thuật ngữ kinh doanh quan trọng được định nghĩa trong từ điển
- Khả năng truy xuất quyết định được triển khai cho năm quy trình kinh doanh hàng đầu
- Đồ thị tri thức kết nối 80% thực thể dữ liệu doanh nghiệp
Giai đoạn 2: Tiêm bối cảnh thông minh (tháng 3-4)
Tầng tự động hóa
- Triển khai các khung điều phối cho ánh xạ bối cảnh.
- Triển khai MCP (Model Context Protocol) cho quản lý trạng thái tác tử.
- Xây dựng hệ thống xác thực logic kinh doanh tự động.
- Tạo cơ chế cập nhật bối cảnh theo thời gian thực.
Công cụ và công nghệ
- Amazon DataZone cho quản lý metadata
- LangGraph, CrewAI và Strands cho điều phối quy trình làm việc
- Cơ sở dữ liệu vector (OpenSearch, Pinecone, FAISS) cho tìm kiếm ngữ nghĩa
- Kiến trúc RAG cho phản hồi AI nhận thức bối cảnh
Bản Thiết Kế 2: Điều Phối Chất Lượng Dữ Liệu Thích Nghi (Blueprint 2: Adaptive Data Quality Orchestration)
Mục tiêu: Duy trì tính toàn vẹn, nhất quán và độ tin cậy của dữ liệu cấp doanh nghiệp xuyên suốt vòng đời AI (Hình 2-12).
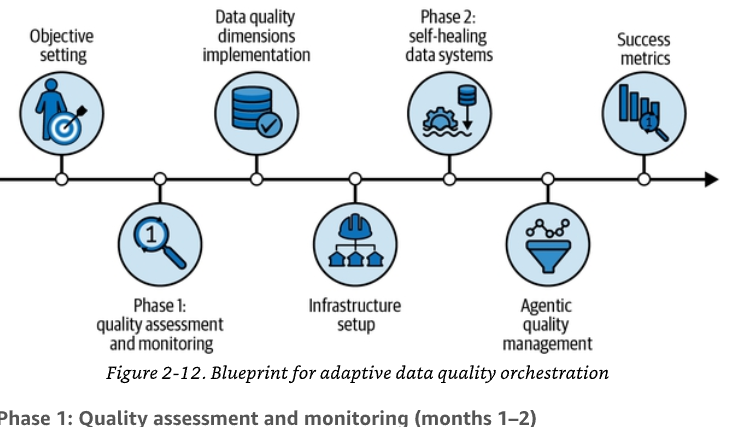
Giai đoạn 1: Đánh giá và giám sát chất lượng (tháng 1-2)
Triển khai các chiều chất lượng dữ liệu
- Độ chính xác: Triển khai Great Expectations để định quy tắc xác thực.
- Đầy đủ: Triển khai phát hiện và gắn cờ dữ liệu thiếu.
- Nhất quán: Chuẩn hóa định dạng sử dụng Apache Iceberg/Delta Lake.
- Kịp thời: Triển khai giám sát độ tươi dữ liệu theo thời gian thực.
- Duy nhất: Xây dựng đường ống loại trùng (deduplication) với khớp dựa trên ML.
Thiết lập hạ tầng
- Monte Carlo cho quan sát dữ liệu
- AWS Glue cho kiểm tra chất lượng tự động
- Apache Airflow cho điều phối đường ống
Giai đoạn 2: Hệ thống tự chữa lành và quản lý tác tử (tháng 3-6)
- Triển khai tác tử AI cho làm sạch dữ liệu tự động.
- Triển khai giám sát chất lượng dữ liệu dự đoán.
- Kích hoạt cập nhật quy tắc xác thực động.
- Xây dựng phân tích tác động tự động cho các vấn đề chất lượng.
Chỉ số thành công
-
95% độ chính xác dữ liệu trên tất cả các nguồn
- <2% giá trị thiếu trong các tập dữ liệu quan trọng
- Cảnh báo chất lượng thời gian thực với thời gian phản hồi <5 phút
-
80% giảm thiểu can thiệp chất lượng dữ liệu thủ công
Bản Thiết Kế 3: Điều Phối Đa Dạng và Phức Tạp Dữ Liệu (Blueprint 3: Orchestrating Data Diversity and Complexity)
Mục tiêu: Thiết lập một hệ sinh thái dữ liệu tự động tích hợp, lập danh mục và giám sát hiệu quả các loại dữ liệu đa dạng trong khi duy trì chất lượng và giảm thiên kiến (Hình 2-13).
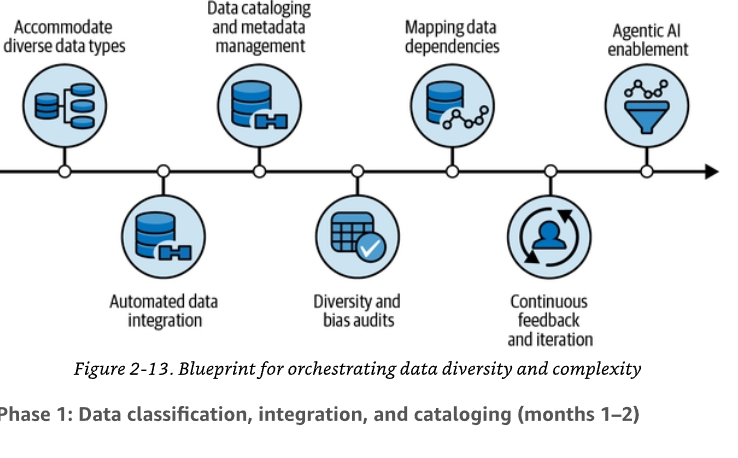
Giai đoạn 1: Phân loại, tích hợp và lập danh mục dữ liệu (tháng 1-2)
Hành động then chốt
- Tích hợp dữ liệu có cấu trúc (cơ sở dữ liệu, bảng tính) và phi cấu trúc (văn bản, hình ảnh, dữ liệu cảm biến) từ cả nguồn nội bộ lẫn bên ngoài.
- Triển khai các đường ống ETL/ELT xử lý được dữ liệu theo lô và streaming (dùng Apache Kafka và Apache NiFi để tự động hóa nhập và biến đổi dữ liệu).
- Triển khai công cụ danh mục dữ liệu hiện đại (ví dụ: AWS Glue, Collibra, DataHub) để phân loại dữ liệu theo loại, nguồn, độ nhạy cảm và mức độ liên quan kinh doanh.
Thiết lập hạ tầng
- SageMaker Lakehouse hoặc Databricks Lakehouse cho truy cập thống nhất vào các nguồn dữ liệu đa loại
- Apache Iceberg cho phân tích có thể mở rộng và định dạng dữ liệu nhất quán
- Nền tảng quản lý metadata (ví dụ: Collibra hoặc Apache Atlas) cho dữ liệu dòng và theo dõi phụ thuộc
Giai đoạn 2: Kiểm toán đa dạng, thiên kiến và quản lý phụ thuộc (tháng 3-4)
Hành động then chốt
- Thường xuyên đánh giá tập dữ liệu về khoảng cách đại diện và các nguồn thiên kiến tiềm năng. Tham gia các nhóm liên chức năng — bao gồm chuyên gia lĩnh vực, nhà khoa học dữ liệu và chuyên gia đạo đức — trong xem xét thu thập và tuyển chọn dữ liệu.
- Sử dụng danh mục metadata và công cụ ánh xạ phụ thuộc để trực quan hóa và quản lý tác động của các thay đổi trên tài sản dữ liệu kết nối với nhau.
- Thiết lập vòng phản hồi giữa nhà xuất bản dữ liệu và các chuyên gia AI, cho phép tinh chỉnh liên tục các thực hành dữ liệu dựa trên sử dụng thực tế.
Kích hoạt Agentic AI
- Triển khai các nền tảng giám sát và quan sát như Amazon Bedrock Agentcore Observability để phát hiện và giải quyết vấn đề chủ động.
- Xây dựng các luồng dữ liệu thích nghi điều chỉnh theo thay đổi về khối lượng, cấu trúc và nhu cầu kinh doanh.
Chỉ số thành công
- 100% tập dữ liệu quan trọng được lập danh mục với đầy đủ metadata và dữ liệu dòng
- Kiểm toán đa dạng được thực hiện hàng quý; khoảng cách đại diện giảm 50% trong năm đầu
- Các đường ống tự động xử lý >90% nguồn dữ liệu mới với can thiệp thủ công tối thiểu
- Tất cả phụ thuộc dữ liệu được ánh xạ và trực quan hóa cho các lĩnh vực kinh doanh ưu tiên cao
Bản Thiết Kế 4: Nền Tảng Dữ Liệu AI Ưu Tiên Bảo Mật (Blueprint 4: Security-First AI Data Platform)
Mục tiêu: Triển khai các kiểm soát bảo mật, tuân thủ và quyền riêng tư vững chắc cho dữ liệu AI-ready (Hình 2-14).
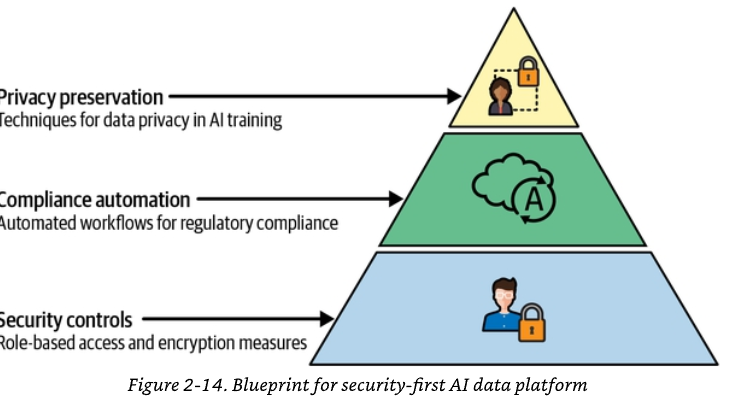
Giai đoạn 1: Kiến trúc bảo mật và kiểm soát truy cập (tháng 1-2)
Hành động then chốt
Thiết lập nền tảng zero-trust: - Triển khai kiến trúc ưu tiên danh tính (identity-first architecture). - Sử dụng kiểm soát truy cập dựa trên vai trò (RBAC) với chính sách đặc quyền tối thiểu cho tất cả tài sản dữ liệu. - Tự động hóa quy trình đăng ký/hủy đăng ký cho người tiêu dùng dữ liệu và các chuyên gia AI.
Triển khai quản lý mã hóa dữ liệu: - Đảm bảo mã hóa AES-256 cho dữ liệu ở trạng thái nghỉ (data lakes, kho dữ liệu, lưu trữ tài liệu) và trong quá trình truyền (API, luồng ETL). - Quản lý bí mật mã hóa (dùng AWS Key Management Service, Azure Key Vault hoặc HashiCorp Vault).
Triển khai ngăn chặn mất dữ liệu nhận thức AI (AI-aware DLP): - Triển khai các công cụ DLP phù hợp cho dữ liệu AI có rủi ro cao và chống tiêm lệnh (prompt injection). - Thường xuyên quét để phát hiện các vụ rò rỉ và chia sẻ dữ liệu trái phép.
Triển khai mã thông báo hóa dữ liệu nhạy cảm: - Sử dụng các giải pháp mã thông báo hóa động cho thông tin cá nhân nhận dạng được (PII), thông tin sức khỏe được bảo vệ (PHI) và dữ liệu tài chính. - Tích hợp với các đường ống ETL/ELT cho che giấu và khôi phục dữ liệu tức thời.
Giai đoạn 2: Tự động hóa tuân thủ và bảo vệ quyền riêng tư (tháng 3-4)
Hành động then chốt
Tự động hóa quản trị quyền riêng tư: - Triển khai TrustArc (hoặc OneTrust) cho thực thi chính sách tự động, quản lý đồng ý và chấm điểm rủi ro quyền riêng tư. - Sử dụng quy trình tuân thủ nhúng cho GDPR, CCPA, HIPAA, v.v.; giám sát liên tục các nguồn cập nhật thay đổi quy định.
Kích hoạt ghi nhật ký kiểm toán bất biến: - Xây dựng tự động hóa dấu vết kiểm toán sử dụng ghi nhật ký chỉ ghi thêm, chống giả mạo (ví dụ: qua Apache Atlas hoặc công cụ cloud native). - Đảm bảo nhật ký sự kiện bao gồm tất cả truy cập, sửa đổi và luồng dữ liệu, hỗ trợ điều tra pháp lý và báo cáo tuân thủ.
Triển khai học máy bảo vệ quyền riêng tư: - Áp dụng các cơ chế quyền riêng tư vi sai (differential privacy) cho dữ liệu huấn luyện mô hình (phương pháp tiêm nhiễu Laplace hoặc Gaussian). - Kích hoạt học liên kết (federated learning) cho các nguồn dữ liệu phân tán để cho phép cập nhật mô hình mà không cần tập trung hóa dữ liệu nhạy cảm. - Tích hợp mã hóa đồng hình (homomorphic encryption) cho tính toán trên dữ liệu đã mã hóa, hỗ trợ các kịch bản quyền riêng tư nâng cao.
Thực thi tối thiểu hóa dữ liệu và giới hạn mục đích: - Triển khai gắn thẻ và kiểm soát truy cập ràng buộc mục đích trên tài sản dữ liệu. - Thiết lập quy trình tự động để thường xuyên xóa dữ liệu không cần thiết hoặc hạn chế sử dụng chỉ cho các mục đích được phép.
Chỉ số thành công
- 100% tập dữ liệu quan trọng được bảo mật qua RBAC và mã hóa AES-256
- Tất cả truy cập và thay đổi được ghi nhật ký ở định dạng bất biến, có thể kiểm toán
- Quy trình tuân thủ tự động đạt 100% phù hợp chính sách quy định
- Dữ liệu nhạy cảm được bảo vệ nhất quán qua DLP, mã thông báo hóa và kiểm soát quyền riêng tư
- Học liên kết và AI bảo vệ quyền riêng tư kích hoạt phân tích trên các tập dữ liệu riêng tư, phân tán
- Giảm >90% can thiệp thủ công cho các hoạt động tuân thủ, kiểm toán và quyền riêng tư
Tóm Tắt Chương 2
Thành công với GenAI và agentic AI không phụ thuộc vào các mô hình phức tạp hay câu lệnh khéo léo, mà phụ thuộc vào việc xây dựng một nền tảng dữ liệu vững chắc. Như đã thảo luận ở đầu chương, các trở ngại chính cho việc áp dụng GenAI hiệu quả bắt nguồn từ hạn chế của dữ liệu — không phải của mô hình. Các khung dữ liệu truyền thống, được xây dựng cho phân tích tĩnh, không thể đáp ứng các yêu cầu về quy mô, phức tạp và khả năng thích nghi mà các hệ thống AI hiện đại đòi hỏi.
Để đạt được GenAI và agentic AI ở quy mô doanh nghiệp, các tổ chức phải suy nghĩ lại căn bản về chiến lược dữ liệu của họ. Điều này bao gồm thu thập logic và bối cảnh kinh doanh, đảm bảo chất lượng và nhất quán dữ liệu nghiêm ngặt, quản lý phức tạp và đa dạng, duy trì bảo mật và tuân thủ vững chắc, kích hoạt cộng tác liền mạch, hỗ trợ khả năng mở rộng và hiệu suất cao, coi dữ liệu là sản phẩm chiến lược và cung cấp tài liệu rõ ràng, hành động được cho người dùng.
Trong các chương tiếp theo, chúng ta sẽ khám phá các chủ đề thiết yếu như chỉnh lý và chuẩn bị dữ liệu (data wrangling and preparation), quản trị dữ liệu, bảo mật, tuân thủ và việc sử dụng cơ sở tri thức và cơ sở dữ liệu vector. Chúng ta cũng sẽ xem xét các kỹ thuật nâng cao cho trích xuất, phân đoạn (chunking) và tối ưu hóa dữ liệu trong các ứng dụng AI.
Cuối cùng, các khung dữ liệu AI-ready vững chắc là nền tảng của thành công GenAI và agentic AI. Bằng cách đầu tư vào các yếu tố nền tảng này, các tổ chức có thể mở khóa các giải pháp AI đáng tin cậy, có thể mở rộng và mang tính chuyển đổi.
Chương 3. Chỉnh Lý và Chuẩn Bị Dữ Liệu cho Ứng Dụng GenAI và Agentic AI (Data Wrangling and Data Preparation for GenAI and Agentic AI Applications)
Hãy tưởng tượng một tổ chức tài chính toàn cầu đã đầu tư hàng triệu đô la vào các mô hình AI tạo sinh tiên tiến, chỉ để phát hiện ra rằng dữ liệu được tuyển chọn cẩn thận của họ — được chuẩn bị kỹ lưỡng cho phân tích truyền thống — thất bại ngay cả với các tác vụ suy luận cơ bản. AI dịch vụ khách hàng của họ gặp khó khăn khi kết nối thông tin trên các hệ thống, các mô hình rủi ro không thể tích hợp hướng dẫn quy định phi cấu trúc, và hệ thống thông tin thị trường tạo ra thông tin kém chính xác do sự không nhất quán ngữ nghĩa trên các nguồn dữ liệu. Bất chấp hạ tầng dữ liệu và khả năng phân tích đẳng cấp thế giới, họ lại rơi vào thế bất lợi cạnh tranh so với các đối thủ linh hoạt hơn đã định hình lại nền tảng dữ liệu của mình cho kỷ nguyên AI.
Kịch bản này đang diễn ra khắp các ngành khi các tổ chức đối mặt với một thực tế khó chịu: các phương pháp chuẩn bị dữ liệu phục vụ tốt trong nhiều thập kỷ về cơ bản không đủ cho các nhu cầu của AI tạo sinh và các hệ thống AI agentic. Khoảng cách này không chỉ là kỹ thuật — nó đại diện cho sự thay đổi mô hình trong cách các tổ chức phải khái niệm hóa, cấu trúc và phát triển tài sản dữ liệu của mình để duy trì tính cạnh tranh trong nền kinh tế được thúc đẩy bởi AI.
Mục Đích và Đối Tượng
Chương này phục vụ như cả hướng dẫn chiến lược lẫn cẩm nang thực tiễn cho các tổ chức điều hướng sự chuyển đổi từ quản lý dữ liệu truyền thống sang các hệ thống tri thức AI-ready. Nó được viết cho đối tượng doanh nghiệp đa dạng, bao gồm:
- Các lãnh đạo điều hành muốn hiểu các hàm ý chiến lược của sự sẵn sàng dữ liệu cho AI
- Các kiến trúc sư dữ liệu và AI chịu trách nhiệm thiết kế hệ thống thông tin thế hệ tiếp theo
- Các nhóm kỹ thuật dữ liệu có nhiệm vụ triển khai và vận hành các đường ống dữ liệu AI-ready
- Các chuyên gia lĩnh vực kinh doanh phải cộng tác với các nhóm kỹ thuật về mô hình hóa ngữ nghĩa
Thay vì tập trung hẹp vào các khái niệm chiến lược hoặc chi tiết triển khai kỹ thuật, chương này tích hợp cả hai quan điểm để cung cấp một khung toàn diện cho sự chuyển đổi thành công. Đến cuối chương này, người đọc sẽ hiểu không chỉ những gì cần thay đổi trong cách tiếp cận chuẩn bị dữ liệu mà còn tại sao những thay đổi này là thiết yếu và cách triển khai chúng hiệu quả.
Mệnh Lệnh Thị Trường (The Market Imperative)
Các số liệu thống kê vẽ nên một bức tranh rõ ràng về cả tính cấp bách lẫn cơ hội. Việc áp dụng GenAI trong doanh nghiệp đã bùng nổ trong hai năm qua, tạo ra áp lực thời gian để các tổ chức thiết lập các nền tảng dữ liệu cần thiết cho thành công cạnh tranh. Đường cong áp dụng nhanh này được thúc đẩy bởi các kết quả kinh doanh thuyết phục trên các ngành:
- Các công ty dịch vụ tài chính báo cáo đạt được cải thiện 45% về sự hài lòng của khách hàng và giảm 40% thời gian giải quyết với việc sử dụng các hệ thống tư vấn được hỗ trợ bởi GenAI.
- Các nghiên cứu điển hình cho thấy các công cụ chẩn đoán và tài liệu hóa được hỗ trợ bởi AI mang lại chẩn đoán nhanh hơn 25-35% và giảm đến 25% chi phí hành chính cho các nhà cung cấp dịch vụ chăm sóc sức khỏe.
- Những người áp dụng phân tích nâng cao và công cụ lập kế hoạch được thúc đẩy bởi AI đã có thể đạt được cải thiện 20-40% về khả năng phục hồi/dịch vụ chuỗi cung ứng và giảm 10-35% chi phí hàng tồn kho.
Tuy nhiên, những kết quả này vẫn còn xa vời với các tổ chức không chuyển đổi hạ tầng dữ liệu của họ. Gartner phát hiện rằng đến cuối năm 2025, ít nhất 50% các dự án AI tạo sinh đã bị từ bỏ sau giai đoạn thử nghiệm khái niệm, chủ yếu do chất lượng dữ liệu kém, kiểm soát rủi ro không đầy đủ, chi phí tăng và giá trị kinh doanh không rõ ràng. Khoảng cách giữa khát vọng và thực thi đang ngày càng rộng, với những người dẫn đầu sớm thiết lập lợi thế cạnh tranh ngày càng khó để những người đến sau vượt qua.
Các tín hiệu đầu tư cũng không kém phần thuyết phục. Thị trường quản trị AI toàn cầu được định giá 309 triệu đô la vào năm 2025 và được dự kiến tăng trưởng lên khoảng 4,8 tỷ đô la vào năm 2034, với tốc độ tăng trưởng hàng năm kép khoảng 36%. Các công ty công nghệ lớn bao gồm Google, Meta, Microsoft và Amazon dự kiến chi tới 630 tỷ đô la vào năm 2026 cho việc xây dựng trung tâm dữ liệu phục vụ hạ tầng AI, tăng 62% so với mức kỷ lục 388 tỷ đô la vào năm 2025.
Lợi Thế Chiến Lược (The Strategic Advantage)
Các tổ chức chuyển đổi thành công khả năng chuẩn bị dữ liệu sẽ đạt được hơn cả sự xuất sắc kỹ thuật — họ sẽ thiết lập lợi thế cạnh tranh bền vững thông qua:
Tốc độ nhận thức (Speed to insight): Rút ngắn thời gian từ thu thập dữ liệu đến thông tin được tạo ra bởi AI từ tuần xuống phút.
Tích hợp tri thức (Knowledge integration): Phá vỡ silo để cho phép suy luận trên các lĩnh vực trước đây bị ngắt kết nối.
Trí tuệ thích nghi (Adaptive intelligence): Xây dựng các hệ thống liên tục học hỏi và phát triển theo các điều kiện kinh doanh thay đổi.
Lợi thế quyết định (Decision advantage): Cung cấp cho người ra quyết định những thông tin liên quan theo ngữ cảnh mà đối thủ cạnh tranh không thể sánh được.
Khả năng phục hồi vận hành (Operational resilience): Tạo ra các hệ thống dữ liệu tự chữa lành duy trì chất lượng và độ tin cậy ở quy mô lớn.
Hành trình chuyển đổi đầy thách thức nhưng thiết yếu. Khi công nghệ GenAI chuyển từ thực nghiệm sang sử dụng sản xuất trên các ngành, cơ hội để thiết lập vị trí dẫn đầu đang thu hẹp nhanh chóng.
Tổng Quan Hành Trình Chuyển Đổi (Transformation Journey Preview)
Hành trình từ quản lý dữ liệu truyền thống sang các hệ thống tri thức AI-ready được minh họa trong Hình 3-1.

Hành trình này theo một lộ trình có thể dự đoán cho hầu hết các tổ chức:
- Đánh giá (Assessment): Hiểu khả năng hiện tại và xác định các khoảng cách quan trọng
- Nền tảng (Foundation): Thiết lập hạ tầng cốt lõi và khung quản trị
- Làm giàu ngữ nghĩa (Semantic enrichment): Xây dựng các tầng biến đổi dữ liệu thành tri thức
- Tích hợp (Integration): Kết nối hệ thống AI với các nguồn tri thức doanh nghiệp
- Tối ưu hóa (Optimization): Nâng cao hiệu suất, chất lượng và trải nghiệm người dùng
- Phát triển (Evolution): Tiến tới các hệ thống tự trị và học liên tục
Chương này cung cấp lộ trình toàn diện để điều hướng từng giai đoạn của hành trình này, kết hợp quan điểm chiến lược với hướng dẫn triển khai thực tiễn.
Hiểu Sự Thay Đổi Mô Hình (Understanding the Paradigm Shift)
Để hiểu quy mô của sự chuyển đổi cần thiết cho các ứng dụng GenAI, chúng ta phải trước tiên xem xét các mô hình đã chi phối chuẩn bị dữ liệu doanh nghiệp trong hai thập kỷ qua. Học máy truyền thống đã tuân theo một phương pháp luận được thiết lập tốt được tối ưu hóa cho các thuật toán học có giám sát tiêu thụ các tập dữ liệu sạch, có cấu trúc và được gán nhãn.
Đường Ống Dữ Liệu Học Máy Đã Được Thiết Lập (The Established Machine Learning Data Pipeline)
Quy trình làm việc truyền thống đã phát triển thành một tiến trình năm giai đoạn tiêu chuẩn đã thúc đẩy vô số triển khai ML thành công trên các ngành:
- Nhập dữ liệu (Data ingestion): Bắt đầu với việc trích xuất thông tin từ nhiều nguồn khác nhau, bao gồm cơ sở dữ liệu quan hệ, API và hệ thống tệp.
- Làm sạch (Cleansing): Giải quyết có hệ thống các giá trị thiếu, ngoại lệ và sự không nhất quán để đảm bảo chất lượng dữ liệu đáp ứng yêu cầu thống kê của thuật toán ML.
- Biến đổi (Transformation): Các phép toán biến đổi theo các mẫu đã thiết lập bao gồm chuẩn hóa, mã hóa biến phân loại và thu nhỏ đặc trưng.
- Kỹ thuật đặc trưng (Feature engineering): Thể hiện đỉnh cao sáng tạo của chuẩn bị dữ liệu truyền thống, nơi chuyên môn lĩnh vực và kỹ thuật thống kê kết hợp để tạo ra các biến dẫn xuất nâng cao hiệu suất mô hình.
- Huấn luyện mô hình (Model training): Hoàn thành chu kỳ khi tập dữ liệu đã chuẩn bị cung cấp cho các thuật toán tối ưu hóa tham số dựa trên các ví dụ được gán nhãn.
Kiến trúc đường ống này đã trưởng thành qua nhiều thập kỷ tinh chỉnh, được hỗ trợ bởi các công cụ mạnh mẽ như AWS Glue, SageMaker Data Wrangler, SQL và các khung ETL, pandas cho thao tác dữ liệu và Apache Airflow cho điều phối quy trình làm việc.
Mô Hình Dữ Liệu Dạng Bảng và Các Hạn Chế (The Tabular Data Paradigm and Its Constraints)
Học máy truyền thống hoạt động trong một mô hình cơ bản hướng về các cấu trúc dữ liệu dạng bảng, nơi thông tin được tổ chức thành các hàng và cột với lược đồ được xác định rõ ràng và mối quan hệ có thể dự đoán. Tuy nhiên, định hướng dạng bảng này tạo ra các giới hạn vốn có khi áp dụng cho các yêu cầu GenAI. Sự tập trung vào trích xuất đặc trưng tối ưu hóa cho hiệu suất thống kê hơn là bảo toàn ngữ nghĩa, thường loại bỏ sự phong phú ngữ cảnh và phức tạp quan hệ mà các hệ thống GenAI đòi hỏi cho các nhiệm vụ suy luận và tạo sinh.
Xem xét ví dụ thực tế về dự đoán giá taxi: các phương pháp ML truyền thống xuất sắc trong thách thức này bằng cách trích xuất các đặc trưng có cấu trúc. Tuy nhiên, cách tiếp cận chuẩn bị dữ liệu tương tự này không thể hỗ trợ một hệ thống GenAI được thiết kế để hiểu các truy vấn ngôn ngữ tự nhiên về tùy chọn vận chuyển, suy luận về các lựa chọn tuyến đường dựa trên điều kiện thời gian thực, hoặc cung cấp các đề xuất theo ngữ cảnh xem xét sở thích người dùng, mẫu giao thông và các yếu tố định giá động.
Cuộc Cách Mạng Khái Niệm trong Xử Lý Dữ Liệu (The Conceptual Revolution in Data Processing)
Các ứng dụng GenAI đòi hỏi một cách tiếp cận hoàn toàn khác ưu tiên hiểu biết ngữ nghĩa hơn tối ưu hóa thống kê. Khi ML truyền thống tìm cách xác định các mẫu dự đoán thông qua các đặc trưng được kỹ thuật, các hệ thống GenAI phải hiểu các mối quan hệ ngữ nghĩa, sắc thái ngữ cảnh và các kết nối tri thức động cho phép suy luận và khả năng tạo sinh.
Sự chuyển đổi cốt lõi liên quan đến việc chuyển từ trích xuất đặc trưng sang biểu diễn tri thức. Các phương pháp truyền thống tối ưu hóa các mối quan hệ toán học giữa các biến, trong khi các hệ thống GenAI phải bảo toàn và nâng cao ý nghĩa ngữ nghĩa nhúng trong nội dung phi cấu trúc, nguồn dữ liệu đa phương thức và các mối quan hệ tri thức động trải dài trên các ranh giới tổ chức và định dạng dữ liệu.
Như minh họa trong Hình 3-2, sự thay đổi mô hình bao gồm nhiều chiều, bao gồm loại dữ liệu, trọng tâm xử lý, mục tiêu đầu ra, kiến trúc và tần suất cập nhật.
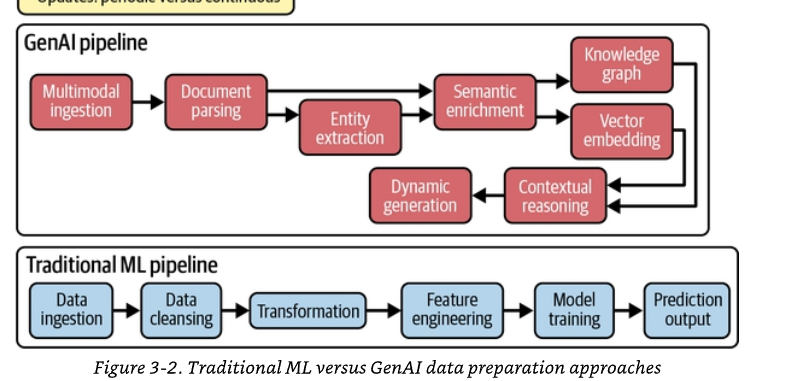
Các Mô Hình Xử Lý Mới và Yêu Cầu Kỹ Thuật (New Processing Paradigms and Technical Requirements)
Quy trình chuẩn bị dữ liệu GenAI giới thiệu các lớp xử lý mới vượt xa ETL truyền thống.
Phân Tích Tài Liệu và Phân Đoạn Ngữ Nghĩa (Document Parsing and Semantic Chunking)
Khả năng phân tích tài liệu phải xử lý các định dạng đa dạng, bao gồm PDF, DOCX, HTML và nội dung đa phương tiện, trong khi bảo toàn cấu trúc ngữ nghĩa và các mối quan hệ ngữ cảnh giúp hệ thống AI hiểu không chỉ nội dung mà còn ý nghĩa và ý định.
Duy trì sự phong phú ngữ cảnh cần thiết cho suy luận AI đòi hỏi sự thay đổi trọng tâm từ tối ưu hóa kỹ thuật sang bảo toàn ngữ nghĩa. Phân đoạn văn bản và phân tách ngữ cảnh đòi hỏi các thuật toán tinh vi duy trì ranh giới ý nghĩa mạch lạc. Các đánh giá gần đây cho thấy chiến lược phân đoạn có thể thay đổi hiệu suất truy xuất hàng chục điểm phần trăm, với các phương pháp nhận thức ngữ nghĩa hoặc cấu trúc thường vượt trội so với các phương pháp có kích thước cố định đơn giản trên các tài liệu phức tạp.
Trích Xuất Thực Thể và Nhúng Vector (Entity Extraction and Vector Embedding)
Trích xuất và gắn thẻ thực thể thông qua nhận dạng thực thể có tên (NER) là thiết yếu để xác định và phân loại các yếu tố ngữ nghĩa trong nội dung phi cấu trúc. Các hệ thống NER dựa trên LLM hiện đại xử lý các biến thể, từ đồng nghĩa và văn bản nhiễu hiệu quả hơn so với các phương pháp truyền thống.
Tạo nhúng vector (vector embedding generation) biến đổi nội dung văn bản và đa phương thức thành các biểu diễn đa chiều cao nắm bắt sự tương đồng ngữ nghĩa và mối quan hệ ngữ cảnh. Các nhúng này cho phép truy xuất dựa trên sự tương đồng tạo thành nền tảng của các hệ thống tạo sinh được tăng cường truy xuất (RAG), cho phép ứng dụng AI truy cập thông tin liên quan dựa trên ý nghĩa thay vì khớp từ khóa.
Tích Hợp Đa Phương Thức và Chuẩn Hóa Ngữ Nghĩa (Multimodal Integration and Semantic Normalization)
Các ứng dụng GenAI hiện đại đòi hỏi tích hợp liền mạch các nguồn dữ liệu có cấu trúc và phi cấu trúc vượt xa các quy trình ETL truyền thống để bao gồm chuẩn hóa ngữ nghĩa và căn chỉnh bản thể học (ontology alignment). Thách thức tích hợp này đòi hỏi đảm bảo ý nghĩa nhất quán trên các định dạng dữ liệu, nguồn và bối cảnh tổ chức đa dạng trong khi bảo toàn các mối quan hệ ngữ nghĩa cho phép hệ thống AI suy luận trên các phương thức khác nhau.
Chuẩn hóa ngữ nghĩa đảm bảo các khái niệm tương tự được biểu diễn nhất quán trên các nguồn dữ liệu khác nhau — ví dụ, "khách hàng", "người dùng" và "chủ tài khoản" tham chiếu đến cùng một thực thể ngữ nghĩa. Quá trình chuẩn hóa này đòi hỏi quản lý bản thể học tinh vi và khả năng ánh xạ ngữ nghĩa mà các quy trình chuẩn bị dữ liệu truyền thống không được thiết kế để hỗ trợ.
Tác Động Kinh Doanh của Sự Thay Đổi Mô Hình (The Business Impact of the Paradigm Shift)
Tác động kinh doanh của sự thay đổi mô hình này vượt xa các chi tiết triển khai kỹ thuật. Các tổ chức điều hướng thành công sự chuyển đổi này đang đạt được các kết quả kinh doanh chưa từng có:
- Các nền tảng trí tuệ thử nghiệm lâm sàng được hỗ trợ bởi AI đã rút ngắn các chu kỳ phân tích và quyết định quan trọng từ vài ngày hoặc thậm chí vài tuần xuống còn vài phút bằng cách tự động hóa nhập và chuẩn hóa dữ liệu thử nghiệm và dữ liệu thực tế.
- Các công ty khách sạn thống nhất dữ liệu khách và sử dụng để cá nhân hóa các ưu đãi đã báo cáo mức chi tiêu trung bình cao hơn 15-20% mỗi lần lưu trú và cải thiện đến 40% trong các lần đặt lại.
- Các nhà sản xuất kết nối dữ liệu vận hành trước đây bị phân tán để thúc đẩy bảo trì dự đoán thường xuyên báo cáo giảm 30-50% thời gian ngừng hoạt động không kế hoạch và khoảng 20-30% chi phí bảo trì thấp hơn.
Những kết quả này không đạt được thông qua cải tiến từng bước đối với hạ tầng dữ liệu hiện có mà thông qua việc xem xét lại căn bản cách dữ liệu được chuẩn bị, làm giàu và cung cấp cho các hệ thống AI.
Tự Đánh Giá: Tổ Chức Của Bạn Đang Ở Đâu? (Self-Assessment: Where Is Your Organization Today?)
Hiểu vị trí hiện tại của tổ chức trong hành trình chuyển đổi này là điều thiết yếu cho việc lập kế hoạch hiệu quả và ưu tiên đầu tư. Khung đánh giá sau giúp bạn đánh giá sự sẵn sàng trên các chiều quan trọng:
Sự sẵn sàng nền tảng dữ liệu (Data foundation readiness): - Chúng tôi duy trì metadata toàn diện cho tất cả tài sản dữ liệu quan trọng. - Kiến trúc dữ liệu của chúng tôi hỗ trợ cả nội dung có cấu trúc lẫn phi cấu trúc. - Chúng tôi đã thiết lập các khả năng lakehouse cho phép truy cập dữ liệu linh hoạt. - Hạ tầng của chúng tôi hỗ trợ xử lý dữ liệu thời gian thực và phân tích streaming.
Khả năng xử lý ngữ nghĩa (Semantic processing capabilities): - Chúng tôi đã triển khai trích xuất thực thể cho nội dung phi cấu trúc. - Các hệ thống của chúng tôi duy trì các mối quan hệ ngữ nghĩa giữa các khái niệm liên quan. - Chúng tôi đã thiết lập các bản thể học cho các lĩnh vực kinh doanh quan trọng. - Chúng tôi có thể tạo và duy trì nhúng vector cho nội dung.
Sự sẵn sàng tích hợp AI (AI integration readiness): - Cơ sở tri thức của chúng tôi hỗ trợ các truy vấn ngôn ngữ tự nhiên. - Chúng tôi đã triển khai các khả năng tìm kiếm vector. - API của chúng tôi cung cấp truy cập thông tin nhận thức ngữ cảnh. - Chúng tôi duy trì dữ liệu dòng toàn diện cho các thông tin được tạo ra bởi AI.
Khung quản trị và chất lượng (Governance and quality framework): - Khung chất lượng của chúng tôi giải quyết sự mạch lạc ngữ nghĩa và độ chính xác thực tế. - Chúng tôi đã thiết lập các quy trình quản trị cho sự phát triển đồ thị tri thức. - Khung tuân thủ của chúng tôi giải quyết các yêu cầu quy định dành riêng cho AI. - Chúng tôi duy trì các dấu vết kiểm toán toàn diện cho hỗ trợ quyết định AI.
Khả năng tổ chức (Organizational capabilities): - Chúng tôi đã thiết lập chuyên môn mô hình hóa ngữ nghĩa. - Các nhóm của chúng tôi hiểu quản lý và tối ưu hóa cơ sở dữ liệu vector. - Chúng tôi đã tích hợp quy trình kỹ thuật dữ liệu và phát triển AI. - Tổ chức của chúng tôi đã thiết lập rõ ràng quyền sở hữu và quản lý dữ liệu.
Các tổ chức thường rơi vào một trong bốn giai đoạn trưởng thành dựa trên đánh giá này. Nếu không có khả năng hiểu ngữ nghĩa này, các hệ thống AI không thể suy luận hiệu quả qua các silo tổ chức hoặc cung cấp các phản hồi phù hợp theo ngữ cảnh cho các truy vấn phức tạp.
Bản Thể Học và Mô Hình Hóa Tri Thức (Ontologies and Knowledge Modeling)
Các bản thể học cung cấp khung chính thức cho hiểu biết ngữ nghĩa, định nghĩa các khái niệm, danh mục và mối quan hệ tồn tại trong một lĩnh vực. Chúng phục vụ như xương sống ngữ nghĩa cho các hệ thống GenAI, cho phép diễn giải nhất quán thông tin từ các nguồn và ngữ cảnh đa dạng.
Phát triển bản thể học hiệu quả đòi hỏi sự hợp tác giữa các chuyên gia lĩnh vực hiểu biết các khái niệm kinh doanh và các nhóm kỹ thuật triển khai các mô hình ngữ nghĩa. Các tổ chức nên bắt đầu với các bản thể học lĩnh vực tập trung giải quyết các khu vực kinh doanh cụ thể trước khi mở rộng sang các mô hình ngữ nghĩa toàn doanh nghiệp. Cách tiếp cận tăng dần này mang lại giá trị ngay lập tức trong khi xây dựng hướng đến hiểu biết ngữ nghĩa toàn diện.
Các phương pháp hiện đại tận dụng AI tạo sinh để đẩy nhanh phát triển bản thể học, tự động trích xuất các khái niệm và mối quan hệ từ tài liệu kỹ thuật và tài liệu kinh doanh. Các phương pháp được hỗ trợ bởi AI này có thể giảm thời gian phát triển bản thể học 60-70% so với các phương pháp thủ công, cho phép các tổ chức nhanh chóng thiết lập các nền tảng ngữ nghĩa mà không cần chuyên môn chuyên biệt rộng.
Nhúng Vector và Tìm Kiếm Tương Đồng (Vector Embeddings and Similarity Search)
Các nhúng vector biến đổi hiểu biết ngữ nghĩa thành định dạng tính toán mà các hệ thống AI có thể xử lý và suy luận hiệu quả. Các biểu diễn số đa chiều cao này nắm bắt ý nghĩa của văn bản, hình ảnh, âm thanh và các loại nội dung khác theo những cách cho phép truy xuất dựa trên sự tương đồng và suy luận ngữ nghĩa.
Tạo và quản lý nhúng (Embedding generation and management)
Các mô hình nhúng biến đổi nội dung thành biểu diễn vector bằng cách phân tích các mẫu ngữ cảnh và mối quan hệ ngữ nghĩa. Những mô hình này đã phát triển nhanh chóng, với các phương pháp hiện đại cung cấp các biểu diễn ngữ nghĩa ngày càng chính xác trên nhiều ngôn ngữ và loại nội dung.
Các tổ chức phải thiết lập các đường ống nhúng có khả năng: - Chọn các mô hình nhúng phù hợp cho các loại nội dung và trường hợp sử dụng khác nhau - Tạo ra các nhúng nhất quán trên các môi trường xử lý phân tán - Cập nhật nhúng khi nội dung nguồn hoặc mô hình nhúng thay đổi - Tối ưu hóa số chiều và lưu trữ cho hiệu suất và hiệu quả chi phí
Quá trình tạo nhúng phải cân bằng độ chính xác ngữ nghĩa với hiệu quả tính toán, đặc biệt đối với các triển khai quy mô lớn có thể xử lý hàng triệu hoặc hàng tỷ tài liệu. Các tổ chức nên triển khai các chiến lược nhúng tăng dần làm mới có chọn lọc các vector bị ảnh hưởng khi nội dung cơ bản thay đổi thay vì tái tạo tất cả nhúng định kỳ.
Tìm kiếm và truy xuất vector (Vector search and retrieval)
Tìm kiếm vector cho phép các hệ thống AI tìm thấy thông tin dựa trên sự tương đồng ngữ nghĩa hơn là khớp từ khóa chính xác. Khả năng này tạo thành nền tảng của các hệ thống RAG kết hợp khả năng suy luận của các mô hình ngôn ngữ lớn với độ chính xác thực tế của các cơ sở tri thức doanh nghiệp.
Triển khai tìm kiếm vector hiệu quả đòi hỏi: - Các chiến lược lập chỉ mục cân bằng hiệu suất truy vấn với hiệu quả lưu trữ - Các độ đo tương đồng phù hợp cho các loại nội dung và trường hợp sử dụng khác nhau - Các phương pháp kết hợp kết hợp tìm kiếm vector với khớp từ khóa truyền thống - Các khả năng lọc kết hợp các quy tắc kinh doanh và kiểm soát truy cập
Các tổ chức nên triển khai các khả năng tìm kiếm vector cung cấp hiệu suất truy vấn dưới giây trong khi hỗ trợ hàng tỷ vector, cung cấp năng lượng cho các ứng dụng AI thời gian thực đòi hỏi truy cập ngay lập tức vào thông tin liên quan.
Đồ Thị Tri Thức và Mô Hình Hóa Quan Hệ (Knowledge Graphs and Relationship Modeling)
Đồ thị tri thức mở rộng hiểu biết ngữ nghĩa bằng cách mô hình hóa rõ ràng các mối quan hệ giữa các thực thể, cho phép suy luận tinh vi trên các cảnh quan thông tin phức tạp. Không giống như cơ sở dữ liệu quan hệ truyền thống tập trung vào các bản ghi có cấu trúc, đồ thị tri thức nhấn mạnh các kết nối và ngữ cảnh hỗ trợ suy luận và khám phá.
Nguyên tắc cơ bản của đồ thị tri thức (Knowledge graph fundamentals)
Đồ thị tri thức biểu diễn thông tin như một mạng lưới các thực thể được kết nối bởi các mối quan hệ có kiểu, tạo ra một mô hình linh hoạt và biểu đạt có thể nắm bắt các ngữ nghĩa thực tế phức tạp. Cách tiếp cận này cho phép các hệ thống AI: - Điều hướng các đường quan hệ để khám phá các kết nối không rõ ràng - Hiểu các mối quan hệ phân cấp và liên kết giữa các khái niệm - Suy ra các mối quan hệ mới dựa trên các mẫu tri thức hiện có - Duy trì ngữ cảnh trên nhiều lĩnh vực thông tin
Các tổ chức nên triển khai các khả năng đồ thị tri thức bổ sung cho các nhúng vector, kết hợp điểm mạnh của cả hai cách tiếp cận để cho phép hiểu biết ngữ nghĩa và suy luận toàn diện.
Các phương pháp triển khai (Implementation approaches)
Triển khai đồ thị tri thức có thể theo nhiều mẫu, tùy thuộc vào nhu cầu tổ chức và hạ tầng hiện có: - Cơ sở dữ liệu đồ thị gốc (Native graph databases) như Amazon Neptune cung cấp lưu trữ có mục đích chuyên biệt và khả năng truy vấn được tối ưu hóa cho dữ liệu trung tâm mối quan hệ. - Bộ lưu trữ ba bộ RDF (RDF triplestores) cung cấp mô hình ngữ nghĩa dựa trên tiêu chuẩn phù hợp với các khuyến nghị W3C. - Lớp đồ thị (Graph layers) xây dựng trên các cơ sở dữ liệu hiện có cung cấp mô hình hóa mối quan hệ mà không cần di chuyển dữ liệu. - Đồ thị tri thức ảo (Virtual knowledge graphs) liên kết thông tin trên nhiều hệ thống thông qua ánh xạ ngữ nghĩa.
Hầu hết các tổ chức được hưởng lợi từ các phương pháp kết hợp kết hợp các mẫu này dựa trên các trường hợp sử dụng cụ thể và đầu tư hiện có. Việc triển khai nên ưu tiên tính nhất quán ngữ nghĩa, khả năng biểu đạt mối quan hệ và hiệu suất truy vấn trong khi duy trì tích hợp với hạ tầng dữ liệu hiện có.
Yêu Cầu Xử Lý Dữ Liệu Thời Gian Thực (Real-Time Data Processing Requirements)
Các ứng dụng GenAI yêu cầu thông tin hiện tại để cung cấp các phản hồi chính xác và phù hợp. Không giống như các mô hình ML truyền thống hoạt động trên các tập dữ liệu tĩnh với các bản cập nhật định kỳ, các hệ thống GenAI phải liên tục kết hợp thông tin mới trong khi duy trì tính nhất quán ngữ nghĩa và tiêu chuẩn chất lượng.
Xử lý ngữ nghĩa streaming (Streaming semantic processing)
Xử lý ngữ nghĩa thời gian thực cho phép các tổ chức kết hợp thông tin mới khi nó xuất hiện, đảm bảo rằng các hệ thống AI có quyền truy cập vào kiến thức hiện tại cho các nhiệm vụ suy luận và tạo sinh. Khả năng này trở nên đặc biệt quan trọng đối với các ứng dụng trong các lĩnh vực động bao gồm dịch vụ tài chính, chăm sóc sức khỏe và truyền thông, nơi thông tin hiện tại trực tiếp ảnh hưởng đến chất lượng quyết định.
Triển khai hiệu quả đòi hỏi: - Kiến trúc hướng sự kiện (Event-driven architectures) xử lý thông tin khi nó thay đổi - Làm giàu ngữ nghĩa streaming (Streaming semantic enrichment) duy trì tính nhất quán với xử lý hàng loạt - Cập nhật tri thức tăng dần (Incremental knowledge updates) bảo toàn các mối quan hệ ngữ nghĩa - Phương pháp luận thu thập dữ liệu thay đổi (Change data capture methodologies) xác định và xử lý các sửa đổi
Các tổ chức nên triển khai các kiến trúc hỗ trợ cả xử lý ngữ nghĩa theo lô và streaming, cho phép các phương pháp linh hoạt dựa trên đặc điểm dữ liệu và yêu cầu ứng dụng.
Quản lý tính nhất quán và hiện tại (Consistency and currency management)
Duy trì tính nhất quán ngữ nghĩa trong khi kết hợp thông tin mới tạo ra những thách thức đáng kể, đặc biệt trong các môi trường phân tán nơi các bản cập nhật có thể xảy ra trên nhiều hệ thống và lĩnh vực tri thức. Các tổ chức phải triển khai: - Chiến lược phiên bản (Versioning strategies) theo dõi trạng thái tri thức theo thời gian - Đảm bảo nhất quán (Consistency guarantees) đảm bảo suy luận mạch lạc qua các bản cập nhật - Siêu dữ liệu hiện tại (Currency metadata) cho phép truy cập thông tin nhận thức thời gian - Cơ chế giải quyết xung đột (Conflict resolution mechanisms) xử lý thông tin mâu thuẫn
Những khả năng này đảm bảo rằng các hệ thống AI suy luận trên các trạng thái tri thức nhất quán trong khi kết hợp thông tin mới khi nó có sẵn.
Mô Hình Trưởng Thành Chuẩn Bị Dữ Liệu GenAI (GenAI Data Preparation Maturity Model)
Mô hình trưởng thành chuẩn bị dữ liệu GenAI được minh họa trong Hình 3-3 cung cấp một khung để hiểu sự phát triển khả năng qua năm giai đoạn.
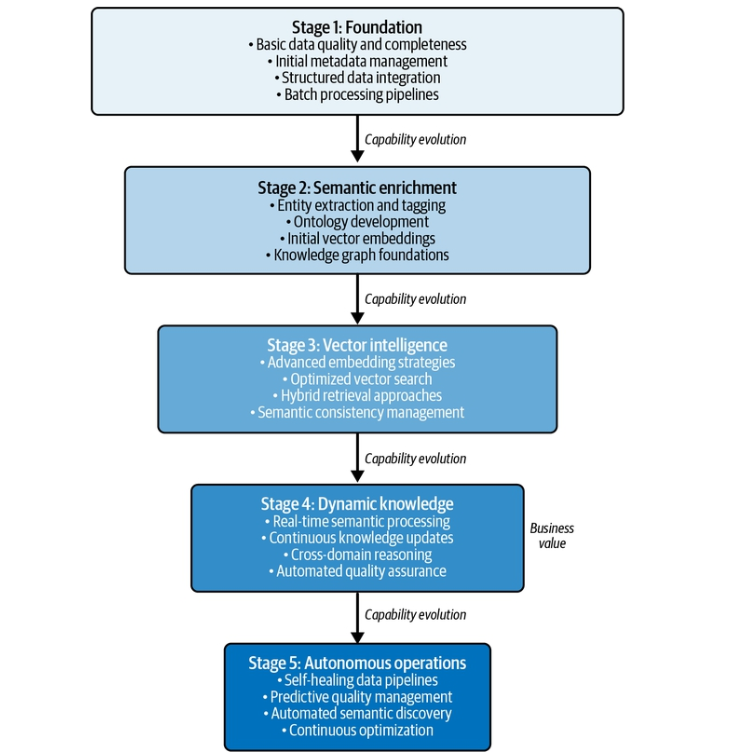
Các tổ chức thường tiến qua các giai đoạn này theo trình tự, mặc dù họ có thể phát triển với tốc độ khác nhau trên các lĩnh vực kinh doanh hoặc lĩnh vực dữ liệu khác nhau. Mô hình cung cấp lộ trình phát triển khả năng trong khi giúp các tổ chức đánh giá tiến độ của họ so với các tiêu chuẩn ngành.
Nghiên Cứu Điển Hình: Chuyển Đổi Tổ Chức Bán Lẻ
Một tổ chức bán lẻ lớn đã triển khai tầng ngữ nghĩa kết nối 13 hệ thống khách hàng, 4,3 triệu giao dịch trong Redshift và các ứng dụng phần mềm như một dịch vụ (SaaS). Hành trình chuyển đổi chi tiết phương pháp phát triển lũy tiến của GenAI.
Trạng thái ban đầu: Tổ chức quản lý dữ liệu bị phân mảnh trên hàng chục hệ thống, thiếu hiểu biết nhất quán về khách hàng và hạn chế hiệu quả AI. Thông tin sản phẩm tồn tại trong nhiều định dạng với các thuộc tính không đồng nhất, trong khi dữ liệu khách hàng vẫn bị cô lập trong các hệ thống tại chỗ và trực tuyến.
Phương pháp chuyển đổi: Tổ chức đã áp dụng chiến lược triển khai theo giai đoạn:
Nền tảng (tháng 1-3): Thiết lập kiến trúc lakehouse với 35 tích hợp Redshift, phát triển các khung quản lý siêu dữ liệu ban đầu.
Làm giàu ngữ nghĩa (tháng 4-6): Phát triển bản thể học lĩnh vực bán lẻ, triển khai trích xuất thực thể cho mô tả sản phẩm và phản hồi khách hàng, thiết lập đồ thị tri thức ban đầu kết nối sản phẩm, khách hàng và giao dịch.
Trí tuệ vector (tháng 7-9): Triển khai tạo nhúng cho mô tả sản phẩm, đánh giá khách hàng và tương tác hỗ trợ; triển khai khả năng tìm kiếm vector trong OpenSearch; phát triển truy xuất kết hợp kết hợp tìm kiếm vector và từ khóa.
Tích hợp và tối ưu hóa (tháng 10-12): Kết nối các ứng dụng GenAI với tầng ngữ nghĩa qua API, triển khai giám sát và đảm bảo chất lượng, tối ưu hóa hiệu suất cho quy mô sản xuất.
Kết quả và bài học: Việc triển khai đòi hỏi sáu tháng phát triển bản thể học và ánh xạ dữ liệu nhưng mang lại kết quả kinh doanh chuyển đổi:
- Các trợ lý GenAI có thể trả lời các câu hỏi phức tạp như "Sản phẩm nào đang có xu hướng trong số người mua lần đầu tháng này?" bằng cách tự động xác định các mối quan hệ giữa phân khúc khách hàng, danh mục sản phẩm và các mẫu thời gian.
- Thời gian giải quyết dịch vụ khách hàng giảm 35% thông qua truy cập thông tin phù hợp theo ngữ cảnh.
- Hiệu quả chiến dịch marketing được cải thiện 28% thông qua phân khúc khách hàng và đề xuất sản phẩm chính xác hơn.
- Chu kỳ phát triển sản phẩm mới được rút ngắn 40% thông qua phân tích phản hồi khách hàng tích hợp.
Các yếu tố thành công quan trọng bao gồm thiết lập các quy trình quản trị rõ ràng cho xác thực mối quan hệ ngữ nghĩa và duy trì các tiêu chuẩn chất lượng dữ liệu trên toàn đường ống xử lý ngữ nghĩa.
Kiến Trúc Tầng Ngữ Nghĩa (The Semantic Layer Architecture)
Tầng ngữ nghĩa đại diện cho đổi mới kiến trúc quan trọng nhất trong sự phát triển từ quản lý dữ liệu truyền thống sang các hệ thống tri thức AI-ready. Tầng này biến đổi dữ liệu doanh nghiệp thô thành thông tin phong phú về ngữ cảnh, có ý nghĩa ngữ nghĩa cho phép các hệ thống AI hiểu các mối quan hệ, suy ra các kết nối và tạo ra các thông tin chi tiết vượt xa việc truy xuất dữ liệu đơn giản.
Tổng Quan Kiến Trúc và Nguyên Tắc Cốt Lõi (Architectural Overview and Core Principles)
Tầng ngữ nghĩa phục vụ như một khung kết nối tận dụng ngôn ngữ chung để thống nhất thông tin trên các hệ thống, công cụ và lĩnh vực doanh nghiệp. Khung này cho phép cả con người và máy móc diễn giải dữ liệu trong ngữ cảnh và đặt nền tảng cho các khả năng AI toàn doanh nghiệp. Không giống như các lớp trừu tượng dữ liệu truyền thống tập trung vào tối ưu hóa truy vấn và hiệu suất, các tầng ngữ nghĩa ưu tiên ý nghĩa, mối quan hệ và hiểu biết ngữ cảnh.
Kiến trúc tầng ngữ nghĩa trong Hình 3-4 theo cách tiếp cận phân lớp biến đổi dữ liệu doanh nghiệp thô qua các giai đoạn làm giàu lũy tiến, kết thúc bằng tri thức AI-ready có thể hỗ trợ các nhiệm vụ suy luận và tạo sinh tinh vi. Mỗi lớp xây dựng trên lớp trước trong khi duy trì sự phân tách rõ ràng, cho phép các tổ chức triển khai các thành phần tăng dần trong khi đảm bảo khả năng mở rộng và bảo trì ở quy mô doanh nghiệp.
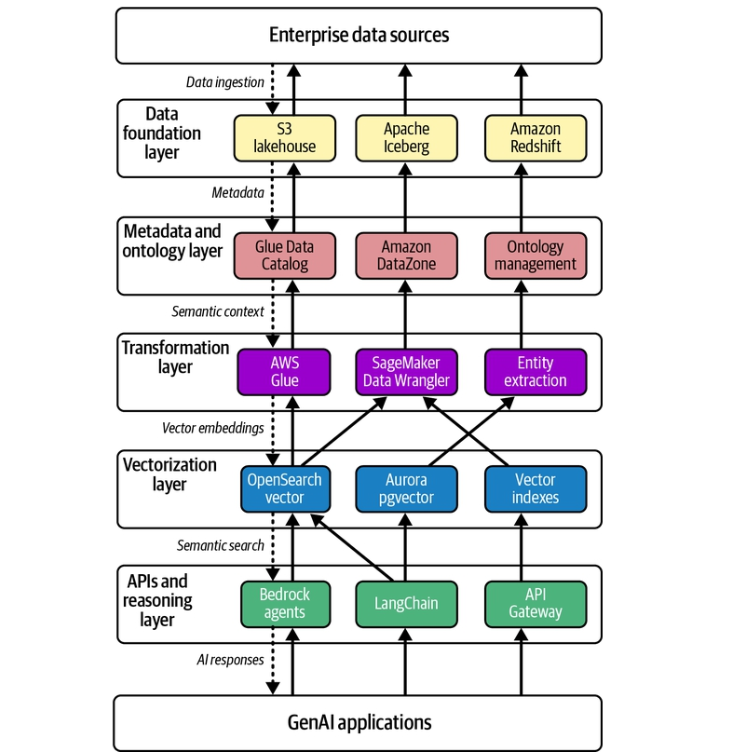
Chúng tôi khuyến nghị tuân theo các nguyên tắc cốt lõi sau:
- Bảo toàn ngữ nghĩa (Semantic preservation): Duy trì ý nghĩa và ngữ cảnh xuyên suốt đường ống xử lý
- Trung tâm mối quan hệ (Relationship centricity): Nhấn mạnh các kết nối giữa các yếu tố thông tin
- Tích hợp đa phương thức (Multimodal integration): Hỗ trợ các loại dữ liệu đa dạng trong một khung ngữ nghĩa thống nhất
- Phát triển động (Dynamic evolution): Tích hợp các bản cập nhật tri thức liên tục và tinh chỉnh mô hình
- Xử lý có thể mở rộng (Scalable processing): Hỗ trợ khối lượng thông tin và tải truy vấn ở quy mô doanh nghiệp
- Tích hợp quản trị (Governance integration): Nhúng bảo mật, tuân thủ và giám sát xuyên suốt kiến trúc
Những nguyên tắc này hướng dẫn các quyết định triển khai trên tất cả các lớp kiến trúc, đảm bảo rằng hệ thống kết quả hỗ trợ cả yêu cầu hiện tại và tương lai trong khi duy trì các yêu cầu doanh nghiệp về độ tin cậy, bảo mật và quản trị.
Lớp Nền Tảng Dữ Liệu: Xây Dựng Trên Kiến Trúc Lakehouse (Data Foundation Layer)
Lớp nền tảng thiết lập hạ tầng dữ liệu cơ bản hỗ trợ xử lý ngữ nghĩa ở quy mô doanh nghiệp. Các triển khai hiện đại tận dụng các kiến trúc lakehouse kết hợp khả năng mở rộng của data lake với khả năng hiệu suất và quản trị của kho dữ liệu (data warehouse).
Các thành phần chính (Key components): - Lưu trữ đối tượng (Object storage): Cung cấp lưu trữ có thể mở rộng và tiết kiệm chi phí cho các loại dữ liệu đa dạng bao gồm cơ sở dữ liệu có cấu trúc, tài liệu phi cấu trúc, hình ảnh, âm thanh và nội dung video. - Định dạng bảng (Table formats) như Apache Iceberg: Cho phép các giao dịch ACID, phát triển schema và khả năng du hành thời gian cho dữ liệu có cấu trúc. - Cơ sở dữ liệu phân tích (Analytical databases): Cung cấp khả năng truy vấn hiệu suất cao cho các khối lượng công việc phân tích phức tạp. - Hạ tầng streaming (Streaming infrastructure): Hỗ trợ nhập và xử lý dữ liệu thời gian thực.
Cách tiếp cận lakehouse cung cấp một số lợi thế cho xử lý ngữ nghĩa: lưu trữ thống nhất cho tất cả các loại dữ liệu, khả năng phát triển schema phù hợp với các cấu trúc dữ liệu thay đổi, và hỗ trợ giao dịch ACID đảm bảo tính nhất quán dữ liệu trên các quy trình làm việc xử lý ngữ nghĩa phức tạp.
Các lưu ý triển khai (Implementation considerations): Các tổ chức nên triển khai lớp nền tảng dữ liệu hỗ trợ cả nguồn dữ liệu có cấu trúc và phi cấu trúc; phù hợp với streaming thời gian thực cùng với xử lý theo lô; cung cấp các mẫu truy cập linh hoạt cho nhu cầu xử lý đa dạng; triển khai bảo mật và kiểm soát truy cập toàn diện; và tối ưu hóa chi phí lưu trữ thông qua phân cấp thông minh và các chính sách vòng đời.
Quản Lý Siêu Dữ Liệu và Bản Thể Học: Tạo Hiểu Biết Ngữ Nghĩa (Metadata and Ontology Management)
Lớp siêu dữ liệu và bản thể học biến đổi các mô tả dữ liệu kỹ thuật thành các định nghĩa ngữ nghĩa có ý nghĩa kinh doanh mà các hệ thống AI có thể hiểu và suy luận. Lớp này thiết lập từ vựng và các mối quan hệ cho phép các hệ thống AI hiểu ngữ cảnh và ý nghĩa dữ liệu trên các lĩnh vực tổ chức đa dạng.
Các thành phần chính: - Danh mục siêu dữ liệu (Metadata catalogs): Cung cấp khám phá và hiểu biết tập trung về tài sản dữ liệu. - Từ điển kinh doanh (Business glossaries): Thiết lập thuật ngữ và định nghĩa nhất quán. - Hệ thống quản lý bản thể học (Ontology management systems): Duy trì các mô hình ngữ nghĩa chính thức và các mối quan hệ. - Công cụ ánh xạ ngữ nghĩa (Semantic mapping tools): Kết nối các cấu trúc kỹ thuật với các khái niệm kinh doanh.
Quản lý bản thể học trở nên quan trọng cho việc thiết lập các mối quan hệ ngữ nghĩa nhất quán trên các nguồn dữ liệu đa dạng. Các tổ chức phải phát triển các bản thể học dành riêng cho lĩnh vực nắm bắt các khái niệm kinh doanh, mối quan hệ và quy tắc trong khi duy trì sự căn chỉnh với các tiêu chuẩn ngành và yêu cầu quy định.
Các lưu ý triển khai: Cân bằng sự nghiêm ngặt ngữ nghĩa chính thức với khả năng sử dụng kinh doanh thực tế; hỗ trợ phát triển hợp tác giữa các nhóm kỹ thuật và kinh doanh; cho phép phát triển tăng dần khi hiểu biết kinh doanh phát triển; duy trì kiểm soát phiên bản và quản lý thay đổi cho các mô hình ngữ nghĩa; và tích hợp với các hệ thống siêu dữ liệu và khung quản trị hiện có.
Đường Ống Biến Đổi và Làm Giàu: Thêm Trí Tuệ Vào Dữ Liệu (Transformation and Enrichment Pipeline)
Lớp biến đổi xử lý việc chuyển đổi phức tạp cần thiết để chuyển đổi dữ liệu thô thành các định dạng phong phú ngữ nghĩa mà các hệ thống AI có thể tiêu thụ hiệu quả. Lớp này phải xử lý các định dạng dữ liệu đa dạng trong khi bảo toàn ý nghĩa ngữ nghĩa và các mối quan hệ ngữ cảnh cho phép suy luận tinh vi.
Các thành phần chính: - Xử lý tài liệu (Document processing): Trích xuất cấu trúc và ý nghĩa từ nội dung phi cấu trúc. - Nhận dạng thực thể (Entity recognition): Xác định và phân loại các yếu tố ngữ nghĩa. - Trích xuất mối quan hệ (Relationship extraction): Khám phá các kết nối giữa các thực thể. - Làm giàu ngữ nghĩa (Semantic enrichment): Thêm ngữ cảnh và ý nghĩa vào thông tin thô.
Các khả năng xử lý ngôn ngữ tự nhiên trích xuất thực thể, tình cảm và chủ đề từ văn bản phi cấu trúc, trong khi các dịch vụ thị giác máy tính phân tích hình ảnh và video để trích xuất thông tin ngữ nghĩa. Đường ống biến đổi phải đảm bảo rằng các quy trình làm giàu tăng cường chứ không làm suy giảm chất lượng của các mối quan hệ ngữ nghĩa.
Các lưu ý triển khai: Cân bằng tốc độ xử lý với độ chính xác ngữ nghĩa; hỗ trợ cả mẫu xử lý theo lô và thời gian thực; triển khai xác thực chất lượng ở mỗi giai đoạn xử lý; duy trì thông tin nguồn gốc (provenance) cho các thông tin được dẫn xuất; và mở rộng để xử lý khối lượng doanh nghiệp trong khi kiểm soát chi phí.
Hạ Tầng Vector Hóa và Lập Chỉ Mục: Kích Hoạt Tìm Kiếm Ngữ Nghĩa (Vectorization and Indexing Infrastructure)
Lớp vector hóa biến đổi dữ liệu đã được làm giàu ngữ nghĩa thành các nhúng vector cho phép các khả năng tìm kiếm và truy xuất dựa trên sự tương đồng thiết yếu cho các ứng dụng GenAI. Lớp này tạo ra các biểu diễn tính toán cho phép các hệ thống AI tìm thấy thông tin liên quan dựa trên ý nghĩa hơn là các khớp chính xác.
Các thành phần chính: - Mô hình nhúng (Embedding models): Biến đổi nội dung thành biểu diễn vector. - Cơ sở dữ liệu vector (Vector databases): Lưu trữ và lập chỉ mục nhúng cho truy xuất hiệu quả. - Khả năng tìm kiếm tương đồng (Similarity search): Tìm nội dung liên quan dựa trên sự gần gũi ngữ nghĩa. - Truy xuất kết hợp (Hybrid retrieval): Kết hợp tìm kiếm vector với các phương pháp truyền thống.
Các chiến lược lập chỉ mục vector phải cân bằng hiệu suất truy vấn với hiệu quả lưu trữ trong khi hỗ trợ các yêu cầu quy mô của các ứng dụng AI doanh nghiệp. Cấu hình lập chỉ mục phù hợp có thể cung cấp hiệu suất truy vấn dưới giây trong khi hỗ trợ hàng tỷ nhúng vector.
Các lưu ý triển khai: Chọn các mô hình nhúng phù hợp cho các loại nội dung khác nhau; tối ưu hóa cấu trúc chỉ mục cho hiệu suất truy vấn và hiệu quả lưu trữ; triển khai các chiến lược phiên bản và cập nhật cho nhúng; cân bằng độ chính xác và thu hồi (precision and recall) dựa trên yêu cầu ứng dụng; và hỗ trợ các khả năng lọc và tìm kiếm kết hợp.
Lớp API và Suy Luận: Kích Hoạt Tiêu Thụ AI (APIs and Reasoning Layer)
Lớp cuối cùng cung cấp các giao diện và khả năng suy luận mà các ứng dụng AI tiêu thụ để truy cập tri thức ngữ nghĩa. Lớp này trừu tượng hóa sự phức tạp của truy cập dữ liệu ngữ nghĩa trong khi cung cấp thông tin ngữ cảnh phong phú mà các hệ thống AI yêu cầu cho suy luận và tạo sinh tinh vi.
Các thành phần chính: - API tri thức (Knowledge APIs): Cung cấp truy cập lập trình vào thông tin ngữ nghĩa. - Quản lý ngữ cảnh (Context management): Duy trì trạng thái và sự liên quan qua các tương tác. - Khung suy luận (Reasoning frameworks): Hỗ trợ suy luận và duyệt quan hệ. - Khả năng điều phối (Orchestration capabilities): Điều phối các mẫu truy cập thông tin phức tạp.
Thiết kế API nên ưu tiên các khả năng truy vấn ngữ nghĩa cho phép các hệ thống AI yêu cầu thông tin dựa trên các mối quan hệ khái niệm hơn là các vị trí dữ liệu cụ thể. Lớp suy luận phải cung cấp quản lý ngữ cảnh toàn diện duy trì trạng thái hội thoại, sở thích người dùng và ngữ cảnh cụ thể cho nhiệm vụ trong khi truy cập tri thức doanh nghiệp.
Các lưu ý triển khai: Cung cấp các mẫu truy cập nhất quán qua các nguồn tri thức đa dạng; hỗ trợ truy xuất thông tin nhận thức ngữ cảnh; triển khai các chiến lược bộ nhớ đệm phù hợp cho hiệu suất; duy trì bảo mật và kiểm soát truy cập toàn diện; và cho phép giám sát và quan sát cho quản lý vận hành.
Tương Tác Thành Phần và Luồng Dữ Liệu (Component Interactions and Data Flows)
Kiến trúc tầng ngữ nghĩa hoạt động thông qua các tương tác phối hợp giữa các thành phần, với dữ liệu chảy qua các giai đoạn làm giàu lũy tiến biến đổi thông tin thô thành tri thức AI-ready.
Luồng nhập và làm giàu (Ingestion and enrichment flow): Luồng nhập và làm giàu điều chỉnh cách dữ liệu thô được tích hợp và làm giàu lũy tiến thành tri thức có cấu trúc, được chú thích ngữ nghĩa mà các dịch vụ AI hạ nguồn có thể tiêu thụ hiệu quả: 1. Dữ liệu thô đi vào qua lớp nền tảng từ các nguồn đa dạng. 2. Các dịch vụ siêu dữ liệu lập danh mục và phân loại thông tin đến. 3. Các đường ống biến đổi trích xuất thực thể và mối quan hệ. 4. Làm giàu ngữ nghĩa thêm các chú thích ngữ cảnh. 5. Nhúng vector được tạo cho nội dung đã xử lý. 6. Đồ thị tri thức được cập nhật với các thực thể và mối quan hệ mới.
Luồng này hoạt động ở cả chế độ theo lô và thời gian thực.
Luồng truy vấn và truy xuất (Query and retrieval flow): Luồng truy vấn và truy xuất điều phối cách các ứng dụng AI đặt câu hỏi với tầng ngữ nghĩa và nhận các phản hồi chất lượng cao, liên quan về mặt ngữ cảnh trong gần thời gian thực: 1. Các ứng dụng AI gửi truy vấn qua API tri thức. 2. Các dịch vụ quản lý ngữ cảnh làm giàu truy vấn với ngữ cảnh liên quan. 3. Lập kế hoạch truy vấn tối ưu hóa chiến lược truy xuất dựa trên đặc điểm truy vấn. 4. Tìm kiếm vector xác định nội dung liên quan về mặt ngữ nghĩa. 5. Duyệt đồ thị tri thức khám phá thông tin liên quan. 6. Kết quả được tập hợp, lọc và trả về cho ứng dụng yêu cầu.
Luồng phát triển tri thức (Knowledge evolution flow): Luồng phát triển tri thức quản lý các bản cập nhật liên tục vào cơ sở tri thức sao cho thông tin mới được tích hợp an toàn trong khi bảo toàn tính nhất quán, quản trị và khả năng truy vết: 1. Thông tin mới được phát hiện qua thu thập dữ liệu thay đổi hoặc cập nhật rõ ràng. 2. Các thành phần tri thức bị ảnh hưởng được xác định qua phân tích phụ thuộc. 3. Xử lý tăng dần chỉ cập nhật các yếu tố cần thiết. 4. Xác thực tính nhất quán đảm bảo sự mạch lạc ngữ nghĩa. 5. Quản lý phiên bản duy trì trạng thái cho kiểm toán và khôi phục. 6. Các dịch vụ thông báo cảnh báo các hệ thống phụ thuộc về các thay đổi liên quan.
Luồng này duy trì tính hiện tại của tri thức trong khi bảo toàn tính nhất quán ngữ nghĩa và cho phép khả năng truy vết cho các yêu cầu quản trị và tuân thủ.
Các Cân Nhắc Triển Khai và Mẫu Phổ Biến (Implementation Considerations and Common Patterns)
Các tổ chức triển khai kiến trúc tầng ngữ nghĩa qua các mẫu khác nhau dựa trên hạ tầng hiện có, khả năng kỹ thuật và ưu tiên chiến lược.
Triển khai cloud native: Các triển khai cloud native tận dụng các dịch vụ được quản lý cho mỗi thành phần kiến trúc, giảm thiểu chi phí vận hành trong khi tối đa hóa khả năng mở rộng và độ tin cậy. Mẫu này lý tưởng cho các tổ chức có hạ tầng hiện có hạn chế hoặc những tổ chức ưu tiên triển khai nhanh chóng và hiệu quả vận hành.
Các dịch vụ AWS chính trong các triển khai cloud native bao gồm: Amazon S3 và Lake Formation cho lớp nền tảng; AWS Glue Data Catalog và Amazon DataZone cho quản lý siêu dữ liệu; Amazon Comprehend và SageMaker cho biến đổi và làm giàu; Amazon OpenSearch và Aurora với pgvector cho vector hóa; và Amazon Bedrock và API Gateway cho tiêu thụ AI.
Mẫu tích hợp kết hợp (Hybrid integration pattern): Các triển khai kết hợp tích hợp các dịch vụ cloud với hạ tầng tại chỗ hiện có, cân bằng đổi mới với tính liên tục. Mẫu này phù hợp cho các tổ chức có đầu tư hiện có đáng kể hoặc các yêu cầu cụ thể đòi hỏi duy trì một số thành phần tại chỗ. Mẫu này bảo toàn các đầu tư hiện có trong khi cho phép áp dụng tăng dần khả năng cloud nhưng tạo ra sự phức tạp thêm trong tích hợp, bảo mật và vận hành.
Mẫu lĩnh vực chuyên biệt (Specialized domain pattern): Các triển khai theo lĩnh vực tập trung vào các khu vực kinh doanh cụ thể với các yêu cầu ngữ nghĩa được xác định rõ ràng, cho phép cung cấp giá trị nhanh chóng trong khi xây dựng hướng đến các khả năng quy mô doanh nghiệp. Các triển khai lĩnh vực điển hình bao gồm: lĩnh vực trí tuệ khách hàng tích hợp CRM, hỗ trợ và dữ liệu tương tác; lĩnh vực thông tin sản phẩm thống nhất thông số kỹ thuật, tài liệu và phản hồi; lĩnh vực vận hành kết nối thông tin quy trình, thiết bị và bảo trì; và lĩnh vực quy định tích hợp chính sách, yêu cầu và bằng chứng tuân thủ.
Triển khai tiến hóa (Evolutionary implementation): Hầu hết các tổ chức được hưởng lợi từ các phương pháp triển khai tiến hóa: (1) Bắt đầu với các trường hợp sử dụng tập trung thể hiện giá trị rõ ràng; (2) Triển khai các thành phần kiến trúc tăng dần; (3) Mở rộng phạm vi ngữ nghĩa qua các lĩnh vực dần dần; (4) Nâng cao khả năng dựa trên kinh nghiệm vận hành; (5) Mở rộng hạ tầng khi áp dụng tăng lên.
Cách tiếp cận này cân bằng cung cấp giá trị ngay lập tức với tính toàn vẹn kiến trúc dài hạn, cho phép các tổ chức học hỏi và thích nghi trong khi xây dựng hướng đến các khả năng ngữ nghĩa toàn diện.
Kiến Trúc Tham Chiếu AWS và Triển Khai (AWS Reference Architecture and Implementation)
Hệ sinh thái AWS cung cấp một nền tảng toàn diện để biến đổi dữ liệu doanh nghiệp thành tri thức AI-ready thông qua một bộ dịch vụ tích hợp trải dài toàn bộ đường ống từ dữ liệu đến AI. Phần này khám phá cách các tổ chức có thể tận dụng các khả năng của AWS để xây dựng các ứng dụng GenAI quy mô sản xuất trong khi duy trì các yêu cầu bảo mật, quản trị và hiệu suất cấp doanh nghiệp.
Tổng Quan Hệ Sinh Thái AWS cho Chuẩn Bị Dữ Liệu GenAI (AWS Ecosystem Overview)
AWS cung cấp các dịch vụ giải quyết từng lớp của kiến trúc ngữ nghĩa, từ quản lý dữ liệu nền tảng đến các khả năng AI tiên tiến. Kiến trúc tham chiếu trong Hình 3-5 minh họa cách các dịch vụ AWS tích hợp để tạo ra một nền tảng toàn diện cho chuẩn bị dữ liệu GenAI.
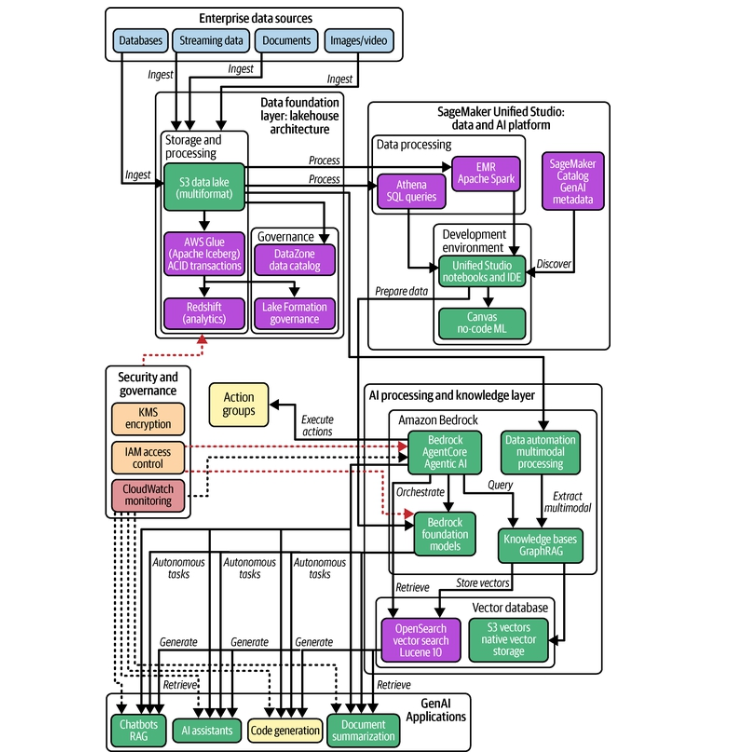
Kiến trúc này tuân theo cách tiếp cận phân lớp được mô tả trong "Kiến Trúc Tầng Ngữ Nghĩa", với các dịch vụ AWS cụ thể triển khai từng thành phần kiến trúc. Các nguyên tắc kiến trúc quan trọng bao gồm:
- Tích hợp dịch vụ (Service integration): Các kết nối liền mạch giữa các dịch vụ AWS giảm thiểu sự phức tạp tích hợp.
- Dịch vụ được quản lý (Managed services): Các tùy chọn được quản lý hoàn toàn giảm chi phí vận hành.
- Khả năng mở rộng (Scalability): Tự động co giãn phù hợp với khối lượng dữ liệu ngày càng tăng và tải trọng người dùng.
- Bảo mật (Security): Các kiểm soát bảo mật toàn diện bảo vệ thông tin nhạy cảm.
- Quan sát (Observability): Giám sát tích hợp cung cấp khả năng hiển thị vận hành.
- Tối ưu chi phí (Cost optimization): Sử dụng tài nguyên hiệu quả giảm thiểu chi phí.
Các Dịch Vụ AWS Chính và Khả Năng (Key AWS Services and Capabilities)
Các dịch vụ AWS chính cho từng lớp kiến trúc ngữ nghĩa:
Nền tảng dữ liệu (Data foundation): - Amazon S3: Lưu trữ đối tượng bền vững, tiết kiệm chi phí cho dữ liệu có cấu trúc và phi cấu trúc, với nhiều lớp lưu trữ cho tối ưu chi phí. - Tích hợp Apache Iceberg (qua AWS Glue và S3 tables): Giao dịch ACID, phát triển schema và du hành thời gian cho các bảng kiểu lakehouse trên S3. - Amazon Redshift: Phân tích hiệu suất cao trên tập dữ liệu lớn với tích hợp S3 chặt chẽ qua Redshift Spectrum. - Amazon S3 Vectors: Lưu trữ và tìm kiếm vector gốc trực tiếp trong S3 cho nhiều trường hợp RAG và tương đồng.
Siêu dữ liệu và xử lý ngữ nghĩa (Metadata and semantic processing): - AWS Glue Data Catalog: Danh mục siêu dữ liệu kỹ thuật trung tâm cho schemas, bảng và công việc. - Amazon DataZone: Danh mục hướng kinh doanh, khám phá và quản trị với làm giàu siêu dữ liệu được hỗ trợ bởi GenAI. - Amazon Comprehend: NLP cho thực thể, tình cảm và chủ đề, bao gồm nhận dạng thực thể tùy chỉnh cho từ vựng theo lĩnh vực. - Amazon Textract: Trích xuất văn bản, biểu mẫu và bảng từ PDF và hình ảnh trong khi bảo toàn cấu trúc tài liệu.
Biến đổi và làm giàu (Transformation and enrichment): - AWS Glue: ETL/ELT serverless cho xử lý theo lô và streaming, bao gồm soạn thảo đường ống ngôn ngữ tự nhiên được hỗ trợ bởi Amazon Q. - Amazon SageMaker Data Wrangler: Môi trường trực quan cho khám phá, biến đổi và kiểm tra chất lượng dữ liệu cho khối lượng công việc ML/AI. - Amazon Bedrock Data Automation: API thống nhất để xử lý nội dung đa phương thức phi cấu trúc (tài liệu, hình ảnh, âm thanh, video) và điều phối các lệnh gọi mô hình.
Vector hóa và tìm kiếm (Vectorization and search): - Amazon OpenSearch Service: Tìm kiếm từ vựng và vector kết hợp, phù hợp cho tìm kiếm ứng dụng và truy xuất GenAI. - Amazon Aurora PostgreSQL với pgvector: Tìm kiếm vector được tích hợp vào các khối lượng công việc quan hệ. - Amazon Bedrock Knowledge Bases: Truy xuất được quản lý (RAG/GraphRAG) với hỗ trợ đa phương thức cho nội dung văn bản và hình ảnh.
Lớp API GenAI và điều phối agentic (GenAI API and agentic orchestration): - Amazon Bedrock: API thống nhất cho các mô hình nền tảng và khả năng AI tạo sinh. - Amazon Bedrock AgentCore: Điều phối agentic trên các công cụ và nguồn dữ liệu với khả năng quan sát tích hợp. - Amazon SageMaker: Môi trường thống nhất cho phát triển, huấn luyện và triển khai mô hình tùy chỉnh cùng với thực nghiệm GenAI.
Mẫu Tích Hợp và Lựa Chọn Dịch Vụ (Integration Patterns and Service Selection)
Các tổ chức triển khai chuẩn bị dữ liệu GenAI trên AWS nên xem xét một số mẫu tích hợp dựa trên các yêu cầu cụ thể và đầu tư hiện có.
Mẫu triển khai RAG (RAG implementation pattern): Tạo sinh được tăng cường truy xuất kết hợp suy luận LLM với các cơ sở tri thức doanh nghiệp sử dụng các dịch vụ AWS. Một triển khai RAG điển hình bao gồm: xử lý tài liệu (Amazon Textract và Comprehend); tạo nhúng vector (Amazon Bedrock hoặc SageMaker); lưu trữ và lập chỉ mục vector (OpenSearch Service); xử lý và truy xuất truy vấn (Bedrock Knowledge Bases); tạo phản hồi (các mô hình nền tảng Bedrock).
Mẫu dữ liệu và AI thống nhất (Unified data and AI pattern): Mẫu này cung cấp một môi trường duy nhất cho dữ liệu, phân tích và AI sử dụng Amazon SageMaker, bao gồm: khám phá và chuẩn bị dữ liệu (SageMaker Unified Studio); làm giàu ngữ nghĩa (các dịch vụ AI tích hợp như Comprehend, Bedrock); phát triển và huấn luyện mô hình (đào tạo và notebook SageMaker); triển khai và giám sát (đường ống và endpoint SageMaker); quản trị và hợp tác (kiểm soát tập trung trong SageMaker và danh mục dữ liệu tích hợp).
Mẫu xử lý nội dung đa phương thức (Multimodal content processing pattern): Đây là mẫu cho các tổ chức có khối lượng lớn tài liệu, hình ảnh, âm thanh và video: nhập nội dung (Amazon S3); xử lý đa phương thức tự động (Amazon Bedrock Data Automation); làm giàu ngữ nghĩa và trích xuất thực thể (Amazon Comprehend và các dịch vụ liên quan); nhúng vector cho tất cả các phương thức (Bedrock hoặc SageMaker); biểu diễn tri thức thống nhất (được lưu trữ qua S3, OpenSearch và/hoặc S3 Vectors, và hiển thị qua Knowledge Bases).
Bằng cách tận dụng hệ sinh thái toàn diện của AWS và tuân theo các mẫu triển khai này, các tổ chức có thể xây dựng các khả năng chuẩn bị dữ liệu GenAI mạnh mẽ cung cấp hiệu suất, khả năng mở rộng và bảo mật cần thiết cho các ứng dụng doanh nghiệp trong khi tối ưu hóa hiệu quả vận hành và hiệu quả chi phí.
Quản Trị, Chất Lượng và Quan Sát (Governance, Quality, and Observability)
Bản chất động của các hệ thống GenAI đưa ra những thách thức chưa từng có cho quản trị dữ liệu, đảm bảo chất lượng và quan sát. Không giống như các đường ống dữ liệu truyền thống hoạt động trên các tập dữ liệu tương đối tĩnh với các mẫu biến đổi có thể dự đoán, các ứng dụng GenAI liên tục phát triển các cơ sở tri thức thông qua các bản cập nhật thời gian thực, làm mới nhúng và các thay đổi mối quan hệ ngữ nghĩa có thể ảnh hưởng đến hành vi hệ thống theo những cách tinh tế nhưng đáng kể.
Sự phát triển này đòi hỏi các cách tiếp cận mới để theo dõi dòng dữ liệu, đảm bảo tính nhất quán chất lượng và duy trì khả năng hiển thị vận hành trên các hệ thống AI phức tạp, phân tán phải cân bằng tính tự trị với trách nhiệm giải trình.
Các Chiều Chất Lượng Mở Rộng cho Dữ Liệu GenAI (Expanded Quality Dimensions)
Đánh giá chất lượng dữ liệu cho các ứng dụng GenAI phải phát triển vượt ra ngoài các thước đo thống kê truyền thống để bao gồm đánh giá tính mạch lạc ngữ nghĩa và sự phù hợp ngữ cảnh. Mặc dù các chiều truyền thống vẫn quan trọng, chúng phải được bổ sung bằng các thước đo chất lượng mới trực tiếp ảnh hưởng đến khả năng suy luận AI, như được minh họa trong Hình 3-6.
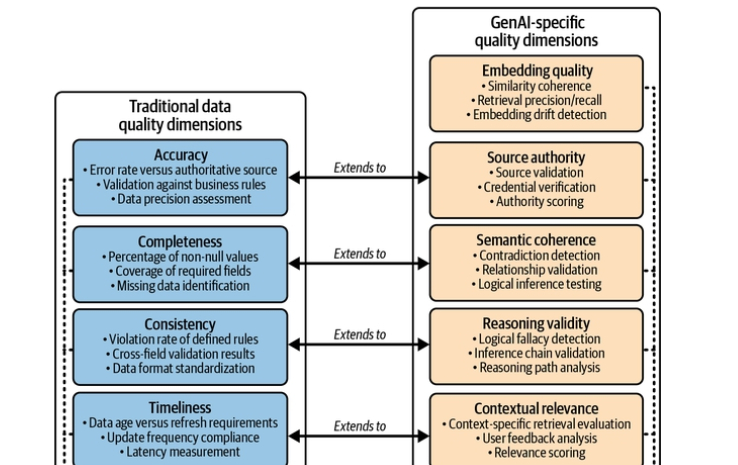
Các chiều chất lượng truyền thống bao gồm khi đánh giá độ tin cậy và tính phù hợp của thông tin: Tính đầy đủ (Completeness): Có đủ tất cả các trường bắt buộc không? Độ chính xác (Accuracy): Dữ liệu có phản ánh thực tế không? Tính nhất quán (Consistency): Dữ liệu có đồng nhất theo thời gian không? Tính kịp thời (Timeliness): Thông tin có đủ hiện tại cho mục đích sử dụng không? Tính duy nhất (Uniqueness): Các bản ghi trùng lặp có được quản lý đúng không?
Các chiều chất lượng dành riêng cho GenAI bổ sung bao gồm: Tính mạch lạc ngữ nghĩa (Semantic coherence): Các mối quan hệ ngữ nghĩa có duy trì tính nhất quán logic không? Sự liên quan ngữ cảnh (Contextual relevance): Thông tin có phù hợp cho các ngữ cảnh cụ thể không? Độ chính xác thực tế (Factual accuracy): Các sự kiện và khẳng định có khách quan đúng không? Tính nhất quán đồ thị tri thức (Knowledge graph consistency): Các mối quan hệ thực thể có logic hợp lệ không? Chất lượng nhúng (Embedding quality): Các nhúng vector có biểu diễn chính xác ý nghĩa không? Tính nhất quán thời gian (Temporal consistency): Thông tin nhạy cảm thời gian có được quản lý đúng không? Căn chỉnh liên lĩnh vực (Cross-domain alignment): Các khái niệm có nhất quán qua các lĩnh vực không?
Các phương pháp đánh giá chất lượng (Quality assessment approaches): Đánh giá chất lượng hiệu quả cho dữ liệu GenAI đòi hỏi nhiều phương pháp bổ sung: Xác thực tự động (Automated validation) sử dụng các quy tắc và phân tích thống kê; Xác thực ngữ nghĩa (Semantic validation) qua kiểm tra tính nhất quán logic; Xác minh thực tế (Factual verification) so với các nguồn có thẩm quyền; Phản hồi người dùng (User feedback) về sự liên quan và tính hữu ích; và Giám sát hiệu suất AI (AI performance monitoring) để xác định các vấn đề liên quan đến chất lượng.
Các Yếu Tố Thiết Yếu của Khung Quản Trị (Governance Framework Essentials)
Quản trị hiệu quả cho chuẩn bị dữ liệu GenAI đòi hỏi các khung có thể phù hợp với sự phát triển tri thức động trong khi duy trì các kiểm soát và trách nhiệm giải trình phù hợp. Khung quản trị nên giải quyết năm lĩnh vực chính:
Quyền sở hữu dữ liệu và tri thức (Data and knowledge ownership): Thiết lập quyền sở hữu và quản lý rõ ràng cho tài sản dữ liệu và tri thức được dẫn xuất, bao gồm: ai sở hữu và kiểm soát các nguồn dữ liệu gốc; ai sở hữu các mô hình ngữ nghĩa và làm giàu; ai kiểm soát việc tạo nhúng vector; ai có thể sửa đổi các biểu diễn tri thức; và ai có thể truy cập và sử dụng tài sản tri thức.
Quản lý chính sách (Policy management): Phát triển và duy trì các chính sách hướng dẫn chuẩn bị dữ liệu GenAI, bao gồm: Chính sách chất lượng (Quality policies) định nghĩa tiêu chuẩn; Chính sách bảo mật (Security policies) thiết lập các kiểm soát bảo vệ dữ liệu; Chính sách quyền riêng tư (Privacy policies) định nghĩa yêu cầu cho thông tin cá nhân; Chính sách tuân thủ (Compliance policies) giải quyết các yêu cầu quy định và pháp lý; và Chính sách vận hành (Operational policies) hướng dẫn quản lý hàng ngày.
Quản trị quy trình (Process governance): Triển khai các quy trình được quản lý cho các hoạt động chính, bao gồm: kiểm soát nhập dữ liệu; quy trình mô hình hóa ngữ nghĩa; thủ tục cập nhật tri thức; quy trình quản lý chất lượng; và thủ tục giải quyết vấn đề.
Quản trị công nghệ (Technology governance): Thiết lập quản trị cho các thành phần công nghệ, bao gồm: tiêu chuẩn kiến trúc; quản lý cấu hình; quản lý thay đổi; kiểm soát phiên bản cho các mô hình ngữ nghĩa và nhúng; và đánh giá công nghệ cho các khả năng và phương pháp mới.
Đo lường và báo cáo (Measurement and reporting): Triển khai đo lường và báo cáo toàn diện, bao gồm: Chỉ số chất lượng (Quality metrics) để quan sát hiệu suất; Chỉ số vận hành (Operational metrics) cho hiệu suất và độ tin cậy hệ thống; Chỉ số tuân thủ (Compliance metrics) để đánh giá việc tuân thủ các chính sách và yêu cầu; Chỉ số giá trị (Value metrics) cho kết quả và lợi ích kinh doanh; và Chỉ số cải tiến (Improvement metrics) để theo dõi tiến độ.
Khung Giám Sát Quản Trị và Chất Lượng (A Governance and Quality Monitoring Framework)
Khung giám sát quản trị và chất lượng trong Hình 3-7 tích hợp chính sách, quy trình và công nghệ để cung cấp giám sát toàn diện về chuẩn bị dữ liệu GenAI.
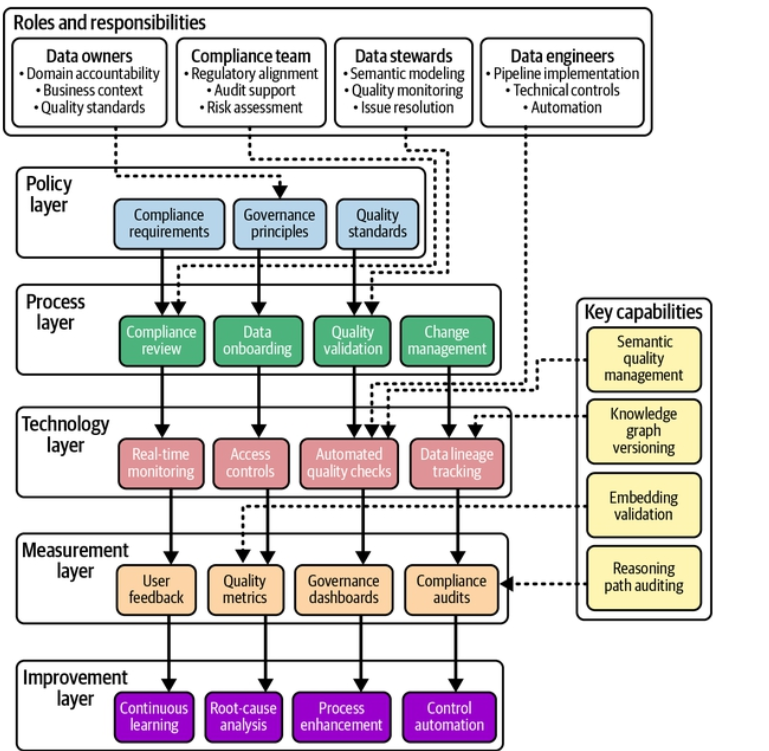
Khung hoạt động qua bốn lớp: Lớp chính sách (Policy layer) thiết lập các tiêu chuẩn về quyền sở hữu, quản trị và chất lượng. Lớp quy trình (Process layer) vận hành hóa quản trị thông qua các quy trình được kiểm soát và theo dõi. Lớp công nghệ (Technology layer) kích hoạt tự động hóa và quy mô bằng cách nhúng quản trị vào môi trường — các công cụ giám sát chất lượng theo dõi các chỉ số, các hệ thống cảnh báo xác định các vấn đề, và bảng điều khiển cung cấp khả năng hiển thị cho các bên liên quan. Lớp đo lường (Measurement layer) định nghĩa cách hiệu quả quản trị được định lượng qua phản hồi người dùng, chỉ số chất lượng, bảng điều khiển quản trị và kiểm toán tuân thủ.
Các Phương Pháp Giám Sát và Quan Sát (Monitoring and Observability Approaches)
Giám sát và quan sát được thống nhất trong khung này để đảm bảo cái nhìn toàn diện về hiệu suất, độ tin cậy và hành vi đạo đức của các hệ thống GenAI.
Một phương pháp quan sát toàn diện nắm bắt các tín hiệu thời gian thực từ hạ tầng, đường ống dữ liệu, các lớp suy luận AI và tương tác người dùng, cho phép quản trị chủ động và đảm bảo liên tục. Các khả năng giám sát và quan sát chính bao gồm: - Theo dõi độ trễ và hiệu suất qua các giai đoạn dữ liệu và suy luận - Phát hiện trôi mô hình và trôi dữ liệu để duy trì độ chính xác theo thời gian - Giám sát tốc độ ảo giác (hallucination rate) cho chất lượng đầu ra tạo sinh - Giám sát chi phí và tối ưu hóa để kiểm soát hiệu quả tài nguyên - Giám sát vi phạm truy cập và sử dụng dữ liệu để thực thi bảo mật - Kiểm tra thiên vị, công bằng và đạo đức để đảm bảo kết quả đáng tin cậy - Giám sát trải nghiệm người dùng để hiểu hiệu suất đầu cuối
Tuân Thủ Quy Định và Đảm Bảo (Regulatory Compliance and Assurance)
Tuân thủ quy định trong môi trường GenAI đòi hỏi bằng chứng sẵn sàng kiểm toán phản ánh cả các quy trình suy luận xác định và xác suất. Các khung quản trị phải nắm bắt dòng, ngữ cảnh và khả năng truy vết cho tất cả các mối quan hệ dữ liệu-mô hình-đầu ra để thỏa mãn các quy định AI toàn cầu đang nổi lên.
Các chiến lược tuân thủ và đảm bảo chính bao gồm: Theo dõi dòng đầy đủ (Full lineage tracking) về sự phát triển dữ liệu, tri thức và mô hình ngữ nghĩa; Tài liệu hóa khả năng giải thích (Explainability documentation) cho các chuỗi suy luận và quyết định; Đánh giá thiên vị và công bằng (Bias and fairness assessments) được tích hợp vào các đường ống giám sát; Kiểm soát bảo toàn quyền riêng tư (Privacy-preserving controls) cho xử lý dữ liệu nhạy cảm; và Giám sát con người trong vòng lặp (Human-in-the-loop oversight) được nhúng trong các đường dẫn quyết định quan trọng.
Bằng cách tích hợp quan sát, tuân thủ và cải tiến liên tục, các tổ chức thiết lập một kiến trúc quản trị bền vững — một kiến trúc cân bằng tốc độ đổi mới với tính toàn vẹn vận hành và sự đáng tin cậy.
Nghiên Cứu Điển Hình: Triển Khai Quản Trị Dịch Vụ Tài Chính
Một công ty dịch vụ tài chính toàn cầu đã tận dụng kiến trúc tầng ngữ nghĩa để tạo ra một lớp chỉ số thống nhất trên toàn cảnh dữ liệu doanh nghiệp. Việc triển khai tích hợp các khả năng AutoML vào quy trình làm việc cho các nhà phân tích Excel và Power BI trong khi di chuyển hạ tầng phân tích sang Snowflake và Amazon SageMaker trên AWS. Tầng ngữ nghĩa cho phép các định nghĩa chỉ số nhất quán qua các phòng ban trong khi hỗ trợ phân tích nâng cao và thông tin chi tiết do AI điều khiển.
Thách thức quản trị ban đầu: Tổ chức đối mặt với các thách thức quản trị đáng kể bao gồm: các yêu cầu quy định về khả năng giải thích và dấu vết kiểm toán; định nghĩa chỉ số không nhất quán qua các đơn vị kinh doanh; các vấn đề chất lượng dữ liệu ảnh hưởng đến độ tin cậy hệ thống AI; khả năng hiển thị hạn chế vào xử lý ngữ nghĩa và suy luận; và các yêu cầu tuân thủ phức tạp cho báo cáo tài chính.
Giải pháp quản trị: Tổ chức đã triển khai một khung quản trị đa lớp, bao gồm: - Hội đồng quản trị ngữ nghĩa: Một nhóm liên chức năng có thẩm quyền đối với các mô hình ngữ nghĩa. - Khung chất lượng: Các tiêu chuẩn toàn diện qua các chiều truyền thống và GenAI. - Theo dõi dòng: Khả năng hiển thị đầu cuối từ dữ liệu nguồn đến đầu ra AI. - Giám sát tự động: Xác minh chất lượng và tuân thủ thời gian thực. - Khả năng kiểm toán: Bảo toàn bằng chứng toàn diện và báo cáo.
Kết quả và bài học: Việc triển khai quản trị mang lại những lợi ích đáng kể: - Giảm 40% thời gian báo cáo tuân thủ. - Cải thiện độ chính xác và tính nhất quán của các nộp quy định. - Tăng cường sự tin tưởng vào các thông tin chi tiết do AI tạo ra. - Phê duyệt nhanh hơn cho các trường hợp sử dụng AI mới. - Giảm nguy cơ phạt quy định.
Các bài học quan trọng bao gồm tầm quan trọng của tích hợp quản trị sớm, hợp tác liên chức năng và các cơ chế tuân thủ tự động giảm thiểu chi phí quản lý thủ công trong khi duy trì các kiểm soát toàn diện.
Bằng cách triển khai các khung quản trị, chất lượng và quan sát toàn diện, các tổ chức có thể triển khai các ứng dụng GenAI với sự tin tưởng ở quy mô doanh nghiệp trong khi duy trì sự tin cậy và trách nhiệm mà các bên liên quan yêu cầu. Những khả năng này không chỉ là chi phí tuân thủ mà là các yếu tố cho phép thiết yếu cho việc áp dụng AI bền vững và hiện thực hóa giá trị.
Các Chủ Đề Nâng Cao: Yêu Cầu Dữ Liệu AI Agentic (Advanced Topics: Agentic AI Data Requirements)
Các hệ thống AI agentic đặt áp lực liên tục lên hạ tầng dữ liệu vì chúng không chỉ tiêu thụ một kho tĩnh — chúng quan sát, hành động và học hỏi theo thời gian thực. Phần này tập trung vào ba yêu cầu nâng cao: kiến trúc học liên tục, truy xuất và quản lý ngữ cảnh dành riêng cho agent, và các mẫu doanh nghiệp nơi những khả năng này mang lại giá trị có ý nghĩa.
Cơ Bản AI Agentic và Tác Động Đến Dữ Liệu (Agentic AI Fundamentals and Data Implications)
Sự xuất hiện của AI agentic đại diện cho bước tiến hóa tiếp theo vượt ra ngoài AI tạo sinh, nơi các hệ thống AI không chỉ tạo ra phản hồi mà còn chủ động theo đuổi các mục tiêu, đưa ra quyết định và thực hiện hành động trong các môi trường động. Những hệ thống này hoạt động như các agent tự trị có thể suy luận về các tình huống phức tạp, thích nghi với các điều kiện thay đổi và học hỏi từ các tương tác trong khi duy trì tính nhất quán với các mục tiêu và ràng buộc của tổ chức.
Học liên tục, nhập thời gian thực và độ tươi nhúng (Continuous learning, real-time ingestion, and embedding freshness): AI agentic đòi hỏi tri thức phát triển với tốc độ gần tương đương với môi trường nó đang suy luận. Điều này có nghĩa là: - Nhập thời gian thực và thu thập thay đổi (Real-time ingestion and change capture): Các sự kiện, tài liệu và giao dịch mới chảy vào tầng ngữ nghĩa liên tục thay vì theo các đợt lớn, không thường xuyên. - Cập nhật tăng dần (Incremental updates): Các nhúng, chỉ mục và đồ thị tri thức được cập nhật để chỉ nội dung bị ảnh hưởng được làm mới khi có điều gì đó thay đổi. - Làm giàu hướng sự kiện (Event-driven enrichment): Các quy trình hạ nguồn (phân đoạn, trích xuất thực thể, tạo nhúng, cập nhật đồ thị) được kích hoạt bởi các thay đổi dữ liệu hơn là các lịch cố định. - Vô hiệu hóa và xây dựng lại có chọn lọc (Selective invalidation and rebuild): Kết quả được lưu trong bộ nhớ đệm và các chế độ xem phi chuẩn hóa được cập nhật có chọn lọc khi dữ liệu nguồn hoặc schema thay đổi.
Từ góc độ kiến trúc, điều này hướng các tổ chức đến các mẫu streaming và micro-batch cung cấp cho các đường ống nhúng, bộ cập nhật đồ thị và chỉ mục tìm kiếm, với giám sát theo dõi cả độ tươi (dữ liệu đằng sau một câu trả lời cũ bao lâu) và phạm vi bao phủ (các lĩnh vực hoặc nguồn nào được đưa vào tầng ngữ nghĩa "trực tiếp").
Truy xuất và quản lý ngữ cảnh dành riêng cho agent (Agent-specific retrieval and context management): Không giống như các hệ thống RAG đơn giản, các kiến trúc agentic thường liên quan đến nhiều agent cộng tác theo thời gian, mỗi agent có vai trò, bộ nhớ và trách nhiệm riêng. Điều đó thúc đẩy các yêu cầu dữ liệu và ngữ cảnh tinh vi hơn:
- Ngữ cảnh phiên (Session context): Lớp truy xuất phải có khả năng kết hợp lịch sử hội thoại đang diễn ra, các kế hoạch trung gian và các lệnh gọi công cụ trước đó.
- Bộ nhớ ngắn hạn (Short-term memory): Các agent cần truy cập nhanh vào các tạo phẩm được tạo trong nhiệm vụ hiện tại (ghi chú tạm thời, kết quả một phần, tóm tắt trung gian).
- Cá nhân hóa dài hạn (Long-term personalization): Truy xuất nên kết hợp sở thích người dùng, tương tác lịch sử và ngữ cảnh vai trò/quyền.
- Nhận thức nhiệm vụ và vai trò (Task and role awareness): Các agent khác nhau (planner, researcher, executor, reviewer) có thể yêu cầu các hồ sơ truy xuất khác nhau.
- Ngữ cảnh thời gian (Temporal context): Hệ thống phải hiểu "hiện tại", "gần đây" và "lịch sử" theo thuật ngữ kinh doanh.
Trong thực tế, điều này có nghĩa là lớp truy xuất không còn là một endpoint RAG chung duy nhất. Thay vào đó, bạn thiết kế các chính sách truy xuất chuyên biệt cho agent (họ có thể thấy gì, họ nhìn lại bao xa, nguồn nào họ tin tưởng) và ghép chúng với các trình quản lý ngữ cảnh quyết định những gì cần giữ lại, tóm tắt hoặc quên từ mỗi tương tác.
Ví Dụ Triển Khai Doanh Nghiệp (Enterprise Implementation Examples)
Các tổ chức qua các ngành đang triển khai các hệ thống AI agentic với các khả năng chuẩn bị dữ liệu tinh vi cho phép học liên tục và thích nghi:
- Trong cài đặt dịch vụ khách hàng, các hệ thống AI agentic kết hợp dữ liệu tương tác trực tiếp (phiên hiện tại), lịch sử khách hàng (mua hàng, phiếu, sở thích) và tri thức thay đổi nhanh chóng (chính sách, tài liệu sản phẩm, các vấn đề đã biết). Các đường ống dữ liệu phải nhập phiếu và tương tác mới liên tục, cập nhật tăng dần các nhúng cho các bài viết hoặc macro đã sửa đổi và duy trì các kho ngữ cảnh theo từng khách hàng mà các agent có thể đọc và ghi trong quá trình hội thoại.
- Trong sản xuất, các hệ thống agentic giám sát dữ liệu cảm biến, nhật ký bảo trì, cập nhật nhà cung cấp và lịch trình sản xuất để đề xuất các hành động như lên lịch lại công việc hoặc bảo trì phòng ngừa. Tại đây, nhập thời gian thực từ các hệ thống công nghệ vận hành/IoT cung cấp cho làm giàu streaming và cập nhật tăng dần cho các kho đặc trưng, cấu trúc đồ thị (phân cấp tài sản, phụ thuộc dây chuyền) và chỉ mục vector được sử dụng để truy xuất tương đồng dựa trên các sự cố trong quá khứ.
Những ví dụ này làm nổi bật yêu cầu dữ liệu cốt lõi cho AI agentic: không chỉ là tri thức tĩnh phong phú mà là các tầng ngữ nghĩa được cập nhật liên tục, nhận thức vai trò và nhạy cảm ngữ cảnh mà các agent có thể tin cậy và thích nghi khi họ học hỏi và hành động theo thời gian.
Tương Lai: Xử Lý Dữ Liệu Tự Trị và Được Hỗ Trợ bởi AI (The Future: Autonomous and AI-Assisted Data Wrangling)
Sự phát triển của xử lý dữ liệu cho các ứng dụng GenAI đang tiến nhanh về phía các hệ thống tự trị có thể khám phá, phân loại và chuẩn bị dữ liệu với sự can thiệp của con người tối thiểu. Sự biến đổi này đại diện cho một sự dịch chuyển cơ bản từ chuẩn bị dữ liệu thủ công, dựa trên quy tắc sang các hệ thống thông minh, thích nghi tận dụng AI để hiểu ngữ nghĩa dữ liệu, xác định các vấn đề chất lượng và tối ưu hóa các quy trình làm việc xử lý tự động.
Khám Phá và Phân Loại Dữ Liệu Thông Minh được Hỗ Trợ bởi AI (AI-Powered Data Discovery and Intelligent Classification)
Việc tích hợp AI vào các quy trình làm việc kỹ thuật dữ liệu đã biến đổi việc tạo và bảo trì đường ống, với các hệ thống hiện đại xử lý các quy trình ETL phức tạp trong khi giảm đáng kể sự can thiệp thủ công. Học máy hiện tự động hóa bảo trì tầng ngữ nghĩa bằng cách phát hiện các mối quan hệ đồng nghĩa qua các nguồn và tạo ra các mô hình ngữ nghĩa nháp từ tài liệu kỹ thuật, đẩy nhanh phát triển bản thể học và giảm sự phụ thuộc vào các chuyên gia khan hiếm.
Giao Diện Chuẩn Bị Dữ Liệu Hội Thoại và Ngôn Ngữ Tự Nhiên (Conversational Data Preparation and Natural Language Interfaces)
Các giao diện hội thoại đang dân chủ hóa xử lý dữ liệu bằng cách cho phép người dùng kinh doanh chỉ định các yêu cầu dữ liệu bằng ngôn ngữ tự nhiên thay vì SQL, Python hoặc các công cụ ETL phức tạp. Các giao diện ngôn ngữ tự nhiên và đa phương thức (giọng nói cộng với văn bản) để người dùng lặp đi lặp lại tinh chỉnh các đường ống qua hội thoại, giảm thời gian phân tích và sự phụ thuộc vào các chuyên gia dữ liệu trong khi giữ quyền kiểm soát trong tay các chuyên gia lĩnh vực.
Đảm Bảo Chất Lượng Tự Trị và Hệ Thống Tự Chữa Lành (Autonomous Quality Assurance and Self-Healing Systems)
Các đường ống thế hệ tiếp theo sẽ sử dụng phản hồi vòng kín giữa hiệu suất AI và chất lượng dữ liệu ngược dòng, tự động điều chỉnh logic chuẩn bị khi phát hiện suy giảm hoặc tăng nguy cơ ảo giác. Giám sát chất lượng tự trị sẽ theo dõi tính mạch lạc ngữ nghĩa, độ chính xác thực tế và sự phù hợp ngữ cảnh, và các cơ chế tự chữa lành sẽ cách ly các nguồn xấu, hoàn nguyên các cập nhật nhúng có hại và kích hoạt xử lý lại khi ngưỡng bị vi phạm.
Hướng Tương Lai và Biên Giới Nghiên Cứu (Future Directions and Research Frontiers)
Tương lai của xử lý dữ liệu tự trị nằm ở các lĩnh vực nghiên cứu mới nổi sẽ tiếp tục biến đổi cách các tổ chức chuẩn bị và quản lý dữ liệu cho các ứng dụng AI: - Hiểu biết đa phương thức (Multimodal understanding): Thống nhất văn bản, hình ảnh, âm thanh, video và dữ liệu có cấu trúc vào một biểu diễn ngữ nghĩa duy nhất. - Hệ thống AI cộng tác (Collaborative AI systems): Hành động như các đối tác chuyên gia, học hỏi liên tục từ các tương tác của con người và ngữ cảnh tổ chức. - Tự động hóa có thể giải thích (Explainable automation): Giải thích rõ ràng các quyết định và khuyến nghị chuẩn bị dữ liệu bằng ngôn ngữ thân thiện với kinh doanh. - Hệ thống tri thức tự phát triển (Self-evolving knowledge systems): Phát hiện các khoảng trống và sự không nhất quán, suy luận trên tri thức hiện có và chủ động nâng cao các cơ sở tri thức doanh nghiệp.
Kế Hoạch Hành Động (Action Plan)
Hành trình từ xử lý dữ liệu truyền thống sang chuẩn bị dữ liệu sẵn sàng cho GenAI đại diện cho nhiều hơn một sự phát triển công nghệ — nó cấu thành một sự tái tưởng tượng cơ bản về cách các tổ chức cấu trúc, quản trị và tạo ra giá trị từ tài sản dữ liệu của họ. Các tổ chức điều hướng thành công sự biến đổi này sẽ thiết lập lợi thế cạnh tranh bền vững thông qua các hệ thống AI có khả năng suy luận, học hỏi và thích nghi theo những cách trước đây là không thể.
Các Nguyên Tắc Chính (Key Principles)
Trong suốt chương này, chúng ta đã khám phá một số nguyên tắc cơ bản nên hướng dẫn hành trình chuyển đổi của bạn:
- Bảo toàn ngữ nghĩa hơn trích xuất đặc trưng (Semantic preservation over feature extraction): Duy trì ý nghĩa và ngữ cảnh trong suốt đường ống chuẩn bị dữ liệu thay vì rút gọn thông tin thành các đặc trưng thống kê.
- Mô hình hóa dữ liệu trung tâm mối quan hệ (Relationship-centric data modeling): Nhấn mạnh các kết nối giữa các yếu tố thông tin để kích hoạt suy luận tinh vi trên tri thức tổ chức.
- Tích hợp đa phương thức (Multimodal integration): Thống nhất các loại dữ liệu đa dạng trong các khung ngữ nghĩa mạch lạc hỗ trợ hiểu biết toàn diện.
- Phát triển tri thức động (Dynamic knowledge evolution): Xây dựng các hệ thống liên tục kết hợp thông tin mới trong khi duy trì tính nhất quán và chất lượng ngữ nghĩa.
- Quản trị theo thiết kế (Governance by design): Nhúng chất lượng, bảo mật và tuân thủ vào toàn bộ kiến trúc hơn là thêm chúng như là suy nghĩ sau.
- Hợp tác giữa người và AI (Human-AI collaboration): Thiết kế các hệ thống tăng cường khả năng của con người hơn là thay thế chúng, kết hợp điểm mạnh của cả hai.
- Biến đổi tăng dần (Incremental transformation): Xây dựng các khả năng dần dần qua các trường hợp sử dụng tập trung thể hiện giá trị trong khi quản lý sự phức tạp.
Các Bước Tiếp Theo Ngay Lập Tức theo Mức Độ Trưởng Thành (Immediate Next Steps by Maturity Level)
Đánh giá tự thân được trình bày trước đó trong chương có thể giúp bạn xác định mức độ trưởng thành hiện tại của tổ chức. Các tổ chức ở các mức độ trưởng thành khác nhau nên tập trung vào các hành động ngay lập tức khác nhau:
Giai đoạn xây dựng nền tảng (0-25% trưởng thành): - Tiến hành đánh giá sẵn sàng toàn diện để xác định các khoảng cách và cơ hội chính. - Thiết lập nền tảng dữ liệu hỗ trợ cả nội dung có cấu trúc và phi cấu trúc. - Triển khai quản lý siêu dữ liệu cơ bản để cải thiện khám phá và hiểu biết dữ liệu. - Phát triển các khung quản trị ban đầu có thể phát triển cùng với khả năng của bạn. - Chọn một trường hợp sử dụng thí điểm tập trung thể hiện giá trị rõ ràng với sự phức tạp có thể quản lý.
Giai đoạn phát triển khả năng (26-50% trưởng thành): - Triển khai làm giàu ngữ nghĩa cho các lĩnh vực nội dung ưu tiên. - Phát triển các khả năng nhúng vector cho các nguồn thông tin chính. - Thiết lập các nền tảng đồ thị tri thức cho các lĩnh vực kinh doanh quan trọng. - Triển khai các khả năng tìm kiếm vector ban đầu để kích hoạt truy xuất dựa trên tương đồng. - Mở rộng các khung quản trị để giải quyết chất lượng và mối quan hệ ngữ nghĩa.
Giai đoạn tối ưu hóa (51-75% trưởng thành): - Nâng cao các khả năng xử lý thời gian thực cho các bản cập nhật tri thức động. - Triển khai quan sát toàn diện trên tất cả các lớp kiến trúc. - Tối ưu hóa hiệu suất tìm kiếm vector cho các ứng dụng AI tương tác. - Mở rộng phạm vi ngữ nghĩa qua các lĩnh vực kinh doanh bổ sung. - Triển khai giám sát chất lượng nâng cao với xác thực tự động.
Giai đoạn đổi mới (76-100% trưởng thành): - Triển khai xử lý dữ liệu tự trị cho các lĩnh vực phù hợp. - Phát triển các khả năng tối ưu hóa dự đoán dự đoán trước các nhu cầu. - Triển khai các đường ống dữ liệu tự chữa lành với khắc phục tự động. - Khám phá các công nghệ mới nổi để tạo ra sự khác biệt cạnh tranh. - Chia sẻ chuyên môn và thông tin chi tiết với cộng đồng rộng lớn hơn.
Các Cân Nhắc Chiến Lược Dài Hạn (Long-Term Strategic Considerations)
Khi bạn phát triển chiến lược dài hạn của mình cho chuẩn bị dữ liệu GenAI, hãy xem xét các yếu tố chiến lược này sẽ ảnh hưởng đến thành công của bạn:
- Khả năng tổ chức và hệ sinh thái (Organizational capabilities and ecosystem): Xây dựng các kỹ năng nội bộ sâu sắc, các con đường học tập chính thức và các trung tâm xuất sắc trong khi tham gia với các đối tác, cộng đồng và nhà cung cấp đẩy nhanh lộ trình của bạn.
- AI có trách nhiệm và tuân thủ (Responsible AI and compliance): Xác định các nguyên tắc đạo đức rõ ràng, điều chỉnh quản trị và giám sát theo các quy định đang nổi lên, và đảm bảo khả năng giải thích, khả năng truy vết và giám sát của con người được thiết kế vào.
- Khác biệt cạnh tranh và phát triển công nghệ (Competitive differentiation and technology evolution): Sử dụng dữ liệu độc đáo và chuyên môn lĩnh vực của bạn để tạo ra các khả năng có thể bảo vệ, trong khi duy trì một radar công nghệ và kiến trúc linh hoạt có thể hấp thụ các dịch vụ và kỹ thuật mới mà không cần làm lại liên tục.
Tóm Tắt Chương 3
Sự dịch chuyển từ các đường ống dữ liệu truyền thống sang các hệ thống tri thức sẵn sàng cho GenAI không còn là tùy chọn — đây là nền tảng cho cách các doanh nghiệp sẽ cạnh tranh, tạo sự khác biệt và hoạt động trong một nền kinh tế AI-first. Các tổ chức hành động sớm trong việc xây dựng nền tảng ngữ nghĩa, quản trị theo thiết kế và tri thức thời gian thực sẽ thiết lập một tốc độ mà những người đến sau khó có thể theo kịp.
Thành công trong lĩnh vực này phụ thuộc ít hơn vào bất kỳ công cụ đơn lẻ nào và nhiều hơn vào tầm nhìn kiến trúc nhất quán, thực thi có kỷ luật và sẵn sàng để con người và AI chuyên biệt hóa trong những gì mỗi bên làm tốt nhất. Nếu bạn coi chương này như một sổ tay hướng dẫn — bắt đầu với một hoặc hai trường hợp sử dụng có tác động cao và mở rộng ra ngoài — bạn có thể biến chuẩn bị dữ liệu GenAI từ một dự án thực nghiệm thành một khả năng chiến lược bền vững.
Chương 4. Quản Trị Dữ Liệu, Bảo Mật, Tuân Thủ và Điều Phối cho GenAI
Khi các tổ chức nhanh chóng áp dụng các ứng dụng AI tạo sinh để chuyển đổi hoạt động của họ, một thách thức quan trọng nổi lên: Làm thế nào để đảm bảo các hệ thống mạnh mẽ này vận hành an toàn, bảo mật và có trách nhiệm trong khi vẫn duy trì tính toàn vẹn dữ liệu là nền tảng cho hiệu quả của chúng? Sự phổ biến của các hệ thống AI xử lý lượng lớn dữ liệu có cấu trúc và phi cấu trúc đã nâng quản trị dữ liệu từ một mối quan tâm IT truyền thống lên thành một khả năng thiết yếu có thể quyết định thành công hay thất bại của các sáng kiến AI. Không giống như các phương pháp quản lý dữ liệu thông thường được thiết kế cho các cơ sở dữ liệu có cấu trúc, các ứng dụng AI đòi hỏi một khung quản trị hoàn toàn khác — một khung có thể xử lý sự phức tạp của dữ liệu phi cấu trúc, quản lý các rủi ro độc đáo do các mô hình ngôn ngữ lớn đặt ra và đảm bảo tuân thủ các yêu cầu quy định đang phát triển.
Chương này cung cấp một lộ trình toàn diện để triển khai các khung quản trị dữ liệu, bảo mật và điều phối mạnh mẽ được thiết kế đặc biệt cho các ứng dụng AI tạo sinh. Bạn sẽ khám phá cách quản trị dữ liệu AI khác với các phương pháp truyền thống và khám phá chín thành phần cơ bản hình thành một mô hình vận hành quản trị AI hiệu quả, từ quản lý dữ liệu và quản lý siêu dữ liệu đến đảm bảo chất lượng dữ liệu và các giao thức bảo mật. Chương đi sâu vào các nguyên tắc AI có trách nhiệm, cung cấp hướng dẫn thực tế về triển khai sự công bằng, minh bạch, trách nhiệm giải trình, bảo vệ quyền riêng tư, độ tin cậy và giám sát của con người trong các hệ thống AI. Bạn sẽ học các kỹ thuật thực hành để bảo vệ thông tin nhạy cảm, triển khai lọc nội dung và hạn chế chủ đề, và đảm bảo bảo vệ dữ liệu đầu cuối trong suốt đường ống AI.
Ngoài quản trị và bảo mật, chương này trang bị cho bạn kiến thức để điều phối các quy trình làm việc AI phức tạp một cách hiệu quả thông qua các thực hành vận hành để quản lý các mô hình ngôn ngữ lớn (LLMOps — LLM Operations). Chúng ta sẽ khám phá các mẫu điều phối khác nhau cho các hệ thống truy xuất tăng cường (RAG) và các khung AI agentic, cùng với các ví dụ code thực tế và chiến lược triển khai sử dụng các công cụ điều phối hiện đại như Strands Agents. Dù bạn đang xây dựng các ứng dụng RAG tuyến tính đơn giản hay các hệ thống đa agent tinh vi, chương này cung cấp nền tảng kỹ thuật và các thực hành tốt nhất cần thiết để triển khai các ứng dụng AI không chỉ mạnh mẽ và hiệu quả mà còn an toàn, tuân thủ và đáng tin cậy.
Quản Trị Dữ Liệu và Bảo Mật Dữ Liệu cho Ứng Dụng AI (Data Governance and Data Security for AI Applications)
Quản trị dữ liệu và bảo mật đã trở thành các trụ cột quan trọng đối với các tổ chức triển khai hệ thống AI. Trong phần này, chúng ta sẽ xem xét chúng bao gồm những gì.
Quản trị dữ liệu (data governance) là một cách tiếp cận có cấu trúc để các tổ chức quản lý và bảo vệ dữ liệu của họ. Bảo mật dữ liệu bao gồm các chiến lược và triển khai các kiểm soát xác định dữ liệu nào có thể được xem, bởi ai và trong điều kiện nào. Sự tích hợp hữu cơ này thể hiện sự dịch chuyển quan điểm từ quản trị dữ liệu như một quá trình thủ công, tập trung vào tuân thủ sang một thực thể thích nghi, tích hợp các thực hành quản lý dữ liệu như một phần không thể thiếu của vòng đời quản lý mô hình AI. Khi xu hướng này tiếp tục, quản trị sẽ trở nên ngày càng hiệu quả, hợp lý và thân thiện với người dùng trong khi vẫn duy trì tính toàn vẹn của nó.
Chủ quyền dữ liệu (data sovereignty) là một cân nhắc quan trọng khác. Các tổ chức đa quốc gia phải đảm bảo tuân thủ các yêu cầu về nơi lưu trữ dữ liệu và chủ quyền dữ liệu của địa phương. Các khung bảo vệ dữ liệu khác nhau, chẳng hạn như GDPR (Quy định Bảo vệ Dữ liệu Chung của EU) và HIPAA (Đạo luật Về Trách nhiệm Giải trình và Di động Bảo hiểm Y tế của Mỹ), áp đặt các quy tắc cụ thể về cách dữ liệu có thể được lưu trữ, xử lý và truyền qua biên giới. Ở giai đoạn này, các tổ chức phải đối mặt với các rủi ro tuân thủ và vi phạm đáng kể.
Sự nhấn mạnh này phản ánh bối cảnh đang phát triển, nơi các tổ chức phải điều hướng các thách thức bảo mật phức tạp do các loại dữ liệu, định dạng và nguồn đa dạng cung cấp năng lượng cho các hệ thống AI. Bảo mật dữ liệu đã phát triển vượt xa một mục kiểm tra tuân thủ — trong một thế giới do AI dẫn dắt, hiểu và triển khai các biện pháp bảo mật mạnh mẽ là điều cần thiết để duy trì lợi thế cạnh tranh, bảo vệ tài sản trí tuệ và xây dựng sự tin cậy duy trì việc áp dụng AI lâu dài.
Hãy bắt đầu bằng cách xem xét quản trị dữ liệu AI khác với quản trị dữ liệu truyền thống như thế nào.
Mô Hình Vận Hành Quản Trị Dữ Liệu AI (The AI Data Governance Operating Model)
Quản trị dữ liệu truyền thống trước đây tập trung vào dữ liệu có cấu trúc trong các hệ thống phân tích trực tuyến quan hệ (OLAP — online analytical processing), chẳng hạn như data lake và kho dữ liệu. Cách tiếp cận này dựa trên một mô hình vận hành được xây dựng xung quanh ba yếu tố chính: con người, quy trình và công nghệ.
Mặc dù quản trị dữ liệu AI đòi hỏi một cách tiếp cận toàn diện hơn bao gồm cả dữ liệu có cấu trúc và phi cấu trúc, nhưng các khối xây dựng cốt lõi — các thành phần cơ bản của quản trị dữ liệu truyền thống được nêu trong Hình 4-1 — vẫn áp dụng.
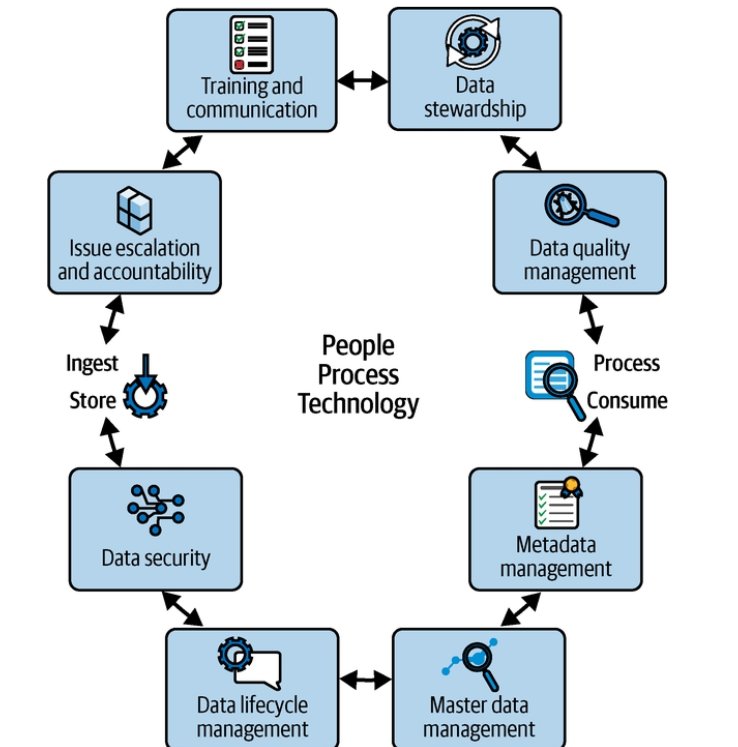
Các thành phần chính của khung toàn diện này là:
Quản lý dữ liệu (Data stewardship): Việc phân công trách nhiệm cho các cá nhân (người quản lý dữ liệu) để giám sát cả dữ liệu có cấu trúc và phi cấu trúc trong suốt vòng đời quản lý dữ liệu, đảm bảo dữ liệu có thể được sử dụng đúng cách trên toàn tổ chức trong khi duy trì tuân thủ với các chính sách tổ chức và quy định.
Trong thực tế, quản lý dữ liệu là một chức năng động. Người quản lý dữ liệu đứng gần nhất với ngữ cảnh kinh doanh của dữ liệu trong mỗi miền sản xuất dữ liệu. Điều quan trọng là xác định thành phần nào và loại dữ liệu nào nên có thể truy cập được với vai trò và điều kiện nào và làm việc với các nhóm kỹ thuật dữ liệu để chuẩn bị dữ liệu theo đó và điều phối quy trình phê duyệt dữ liệu thay mặt cho doanh nghiệp.
Quản lý chất lượng dữ liệu (Data quality management): Các quy trình và kiểm soát đảm bảo dữ liệu chính xác, đầy đủ, nhất quán và kịp thời, bao gồm xác thực, làm sạch và chuẩn hóa, để đảm bảo các hệ thống AI được đào tạo và vận hành trên dữ liệu đáng tin cậy.
Quản lý siêu dữ liệu (Metadata management): Thực hành nắm bắt, tổ chức và duy trì thông tin về dữ liệu (siêu dữ liệu) — chẳng hạn như nguồn gốc, cấu trúc, dòng dữ liệu và cách sử dụng — để kích hoạt tính minh bạch, khả năng truy xuất và quản trị hiệu quả trên tất cả các loại dữ liệu.
Quản lý dữ liệu chủ (Master data management — MDM): Một tập hợp các quy trình và công cụ để tạo và duy trì một chế độ xem duy nhất, nhất quán và chính xác về các thực thể dữ liệu kinh doanh quan trọng (chẳng hạn như khách hàng hoặc sản phẩm) trên toàn tổ chức, đảm bảo chất lượng, khả năng truy cập và bảo mật của cả dữ liệu có cấu trúc và phi cấu trúc.
Quản lý vòng đời dữ liệu (Data lifecycle management): Quản lý đầu cuối dữ liệu từ khi tạo và thu thập ban đầu qua lưu trữ, sử dụng và lưu trữ đến khi xóa cuối cùng, đảm bảo dữ liệu vẫn chất lượng cao, an toàn và tuân thủ với các quy định quyền riêng tư như GDPR và CCPA.
Bảo mật dữ liệu (Data security): Việc triển khai các chính sách, công nghệ và kiểm soát để bảo vệ dữ liệu khỏi truy cập trái phép, vi phạm và lạm dụng, bao gồm mã hóa, kiểm soát truy cập và giám sát, với sự chú ý đặc biệt đến các rủi ro độc đáo do các hệ thống AI đặt ra. Bao gồm kiểm tra thường xuyên và có hệ thống về các thực hành quản lý dữ liệu, sử dụng dữ liệu và tuân thủ các chính sách quản trị, bao gồm việc tạo các dấu vết kiểm toán để theo dõi truy cập dữ liệu, thay đổi và dòng dữ liệu cho cả dữ liệu có cấu trúc và phi cấu trúc.
Leo thang vấn đề và trách nhiệm giải trình (Issue escalation and accountability): Các quy trình chính thức để xác định, báo cáo và giải quyết các vấn đề liên quan đến dữ liệu, với các vai trò và trách nhiệm được xác định rõ ràng để đảm bảo giải quyết kịp thời và trách nhiệm giải trình cho các lỗi quản trị dữ liệu hoặc vi phạm.
Đào tạo và truyền thông (Training and communication): Các chương trình giáo dục và nâng cao nhận thức liên tục để đảm bảo tất cả các bên liên quan hiểu các chính sách quản trị dữ liệu và các thực hành tốt nhất, các rủi ro và yêu cầu mới do AI tạo ra, và vai trò của họ trong việc duy trì chất lượng dữ liệu, bảo mật và tuân thủ.
Những thành phần này cùng nhau tạo thành nền tảng của một khung quản trị dữ liệu AI mạnh mẽ, đảm bảo rằng cả dữ liệu có cấu trúc và phi cấu trúc đều được quản lý một cách có trách nhiệm, an toàn và phù hợp với các tiêu chuẩn tổ chức và quy định.
Sự Khác Biệt trong Quản Trị Dữ Liệu Có Cấu Trúc và Phi Cấu Trúc (Differences in Governance of Structured and Unstructured Data)
Mặc dù các thành phần cơ bản của quản trị dữ liệu vẫn giống nhau cho cả dữ liệu có cấu trúc và phi cấu trúc, nhưng đáng chú ý là các phương pháp và kỹ thuật được sử dụng để triển khai chúng có thể khác nhau đáng kể. Các lĩnh vực mà quản trị AI có xu hướng phân kỳ nhiều nhất so với quản trị dữ liệu truyền thống là quản lý dữ liệu, quản lý siêu dữ liệu, chất lượng dữ liệu và bảo mật dữ liệu. Những yếu tố này cùng nhau tạo thành nền tảng chiến lược cho quản trị hiệu quả: quản lý dữ liệu và quản lý siêu dữ liệu kích hoạt các hệ thống AI để diễn giải và sử dụng dữ liệu đúng cách, chất lượng dữ liệu đảm bảo dữ liệu cung cấp cho các hệ thống AI là đáng tin cậy, và bảo mật dữ liệu bảo vệ toàn bộ đường ống từ nhập đến suy luận. Trong các phần tiếp theo, chúng ta sẽ khám phá từng lĩnh vực này lần lượt.
Quản Lý Dữ Liệu và Quản Lý Siêu Dữ Liệu (Data Stewardship and Metadata Management)
Quản lý dữ liệu và quản lý siêu dữ liệu gắn chặt với nhau. Như đã đề cập trước đó, quản lý dữ liệu thường là vai trò của một người quản lý dữ liệu có hiểu biết vững chắc về việc sử dụng kinh doanh của dữ liệu. Họ ngồi ở giao điểm của bảo mật dữ liệu và quản lý siêu dữ liệu — trách nhiệm của họ là đảm bảo rằng siêu dữ liệu kỹ thuật được dịch sang thuật ngữ kinh doanh. Điều này thường liên quan đến việc xây dựng một từ điển kinh doanh có thể được sử dụng rộng rãi trên toàn tổ chức. Trước đây, điều này thường được thực hiện bằng cách chỉ thêm các mô tả ngắn, với giả định rằng một con người sẽ xem xét các mô tả đó và có thể hiểu chúng. Tuy nhiên, để các agent AI sử dụng hiệu quả từ điển kinh doanh, các mô tả phải vừa chi tiết vừa súc tích, được xây dựng cẩn thận để đảm bảo không có định nghĩa chồng chéo và các agent có thể xác định chính xác khi nào nên sử dụng từng đối tượng dữ liệu.
Làm Cho Dữ Liệu Có Thể Truy Cập Cho Cả Con Người và AI Agentic (Making Data Accessible for Humans and Agentic AI)
Hãy xem xét Bảng 4-1, minh họa phiên bản đơn giản hóa của tập dữ liệu gen người được tổ chức theo định dạng có cấu trúc. Hãy tưởng tượng đây là một phần của data lake của bạn. Giả sử bạn muốn kích hoạt một ứng dụng AI để phân tích bảng này và trả lời các câu hỏi liên quan đến khám phá thuốc. Tuy nhiên, một số tên cột — siêu dữ liệu kỹ thuật được cung cấp trong bảng này — có thể khó cho cả người dùng và ứng dụng để diễn giải.
Bảng 4-1. Danh mục gen người (Human gene catalog)
| geneid | genename | chr | strand | start | end | genesum | entrezid | genesyn | uniprot_accs |
|---|---|---|---|---|---|---|---|---|---|
| ENSG00000139618 | BRCA2 | 13 | + | 32315474 | 32400266 | Breast cancer type 2 susceptibility protein | 675 | ['FAD1','FANCD1'] | ['P51587'] |
| ENSG00000141510 | TP53 | 17 | – | 7668402 | 7687550 | Tumor protein p53 | 7157 | ['P53','BCC7'] | ['P04637'] |
| ENSG00000157764 | BRAF | 7 | + | 140719327 | 140924929 | B-Raf proto-oncogene | 673 | ['RAFB1'] | ['P15056'] |
| ENSG00000198786 | CFTR | 7 | – | 117120016 | 117308718 | Cystic fibrosis transmembrane conductance regulator | 1080 | ['ABCC7'] | ['P13569'] |
| ENSG00000121879 | EGFR | 7 | + | 55086714 | 55279321 | Epidermal growth factor receptor | 1956 | ['ERBB','ERBB1'] | ['P00533'] |
Để làm cho dữ liệu có cấu trúc của bạn dễ tiếp cận và hữu ích hơn cho cả người dùng và ứng dụng AI, điều cần thiết là phải có một từ điển kinh doanh được phát triển bởi người quản lý dữ liệu. Từ điển này nên sử dụng các thuật ngữ rõ ràng, mô tả dễ hiểu từ góc độ kinh doanh và phác thảo khi nào và ở đâu mỗi yếu tố dữ liệu có thể được sử dụng. Các hệ thống AI hiện đại phụ thuộc vào các từ điển như vậy để diễn giải và làm việc hiệu quả với dữ liệu của bạn.
Một từ điển cho ví dụ bảng trên có thể bao gồm:
Mô tả bảng (Table description): Bảng này cung cấp một danh mục toàn diện về các gen mã hóa protein của người, tích hợp các định danh tiêu chuẩn hóa và các thuộc tính sinh học chính từ các cơ sở dữ liệu bộ gen lớn. Mỗi hàng đại diện cho một gen duy nhất và bao gồm tọa độ bộ gen, danh pháp chính thức, tóm tắt chức năng, tài liệu tham khảo chéo với các nguồn bên ngoài (như Ensembl, NCBI, OMIM, HGNC và UniProt), cũng như các từ đồng nghĩa đã biết và thông tin phiên mã chuẩn. Cấu trúc này hỗ trợ chú thích gen mạnh mẽ, nghiên cứu liên kết bệnh tật và tích hợp đa cơ sở dữ liệu cho nghiên cứu và lâm sàng bộ gen.
Định nghĩa cột (Column definitions):
- geneid — Định dạng: Chuỗi (ví dụ: ENSG00000139618). Mô tả: Định danh gen duy nhất từ cơ sở dữ liệu Ensembl. Được sử dụng phổ quát để tham chiếu gen trên các cơ sở dữ liệu bộ gen. Cột này có thể được dùng để kết nối với các bảng dữ liệu dung sai missense, Shet và phiên mã.
- genename — Định dạng: Chuỗi (ví dụ: BRCA2, TP53). Mô tả: Ký hiệu gen chính thức được phê duyệt bởi Ủy ban Danh pháp Gen HUGO (HGNC). Chuẩn hóa tên gen để nhất quán trong các bối cảnh nghiên cứu và lâm sàng.
- chr — Định dạng: Số nguyên (ví dụ: 7, 17). Mô tả: Số nhiễm sắc thể nơi gen nằm. Con người có 22 nhiễm sắc thể thường (1–22) và 2 nhiễm sắc thể giới tính (X/Y).
- strand — Định dạng: Chuỗi (+ hoặc –). Mô tả: Cho biết chuỗi DNA nào mã hóa gen: + = chuỗi tiến/dương (5' → 3'); – = chuỗi ngược/âm (chuỗi bổ sung).
- start, end — Định dạng: Số nguyên. Mô tả: Tọa độ bộ gen đánh dấu vị trí bắt đầu và kết thúc của gen trên nhiễm sắc thể, dựa trên một bộ gen tham chiếu (ví dụ: GRCh38).
- genesum — Định dạng: Chuỗi (ví dụ: "Breast cancer type 2 susceptibility protein"). Mô tả: Tóm tắt chức năng súc tích của gen, thường lấy từ cơ sở dữ liệu Gen của NCBI hoặc cơ sở dữ liệu UniProt. Sử dụng cột này để hiểu tình trạng bệnh nhằm lọc đúng gen quan tâm.
- entrezid — Định dạng: Số nguyên (ví dụ: 675 cho BRCA2). Mô tả: Định danh duy nhất từ cơ sở dữ liệu Gen của NCBI. Quan trọng để tham chiếu chéo dữ liệu gen trong nghiên cứu y sinh.
- genesyn — Định dạng: Mảng chuỗi (ví dụ: ['FAD1', 'FANCD1'] cho BRCA2). Mô tả: Tên thay thế hoặc ký hiệu lịch sử cho gen (ví dụ: ký hiệu lỗi thời hoặc bí danh).
- uniprot_accs — Định dạng: Mảng chuỗi (ví dụ: ['P51587'] cho BRCA2). Mô tả: Số truy cập protein chính từ cơ sở dữ liệu UniProt, tham chiếu sản phẩm protein chuẩn của gen.
Khi thiết lập các định nghĩa từ điển cho tổ chức của bạn, bạn có thể linh hoạt sử dụng bất kỳ công cụ nào phù hợp nhất với nhu cầu. Một số tổ chức chọn phát triển các giải pháp nội bộ tùy chỉnh, trong khi những tổ chức khác tận dụng các nền tảng thương mại như Collibra, Amazon SageMaker Catalog hoặc Informatica Business Catalog. Kinh nghiệm trên các tổ chức có quy mô khác nhau nhất quán cho thấy không có công cụ đơn lẻ nào cung cấp giải pháp hoàn chỉnh — mỗi công cụ đều có điểm mạnh và hạn chế riêng. Hiệu quả thực sự đến từ sự kết hợp giữa các công cụ phù hợp với con người lành nghề và các quy trình được xác định rõ ràng; công nghệ đơn thuần không đảm bảo thành công trong quản trị AI.
Kiểm Thử Các Công Cụ (Testing Our Tools)
Như đã đề cập trước đó, các hệ thống AI yêu cầu các hướng dẫn rõ ràng về cách sử dụng dữ liệu có sẵn. Các hướng dẫn này thường được gửi như một phần của prompt — được gọi là ngữ cảnh (context) — cho phép các mô hình ngôn ngữ lớn thực hiện các tác vụ mong muốn. Các LLM hiện đại như Claude của Anthropic, ChatGPT của OpenAI, Llama của Meta và các mô hình Nova của Amazon hỗ trợ độ dài ngữ cảnh từ khoảng 128k đến 1M token, vì vậy các prompt này có thể rất lớn. Về phối cảnh, giới hạn 200k token có thể chứa khoảng 500 trang văn bản, đủ cho hầu hết các trường hợp sử dụng doanh nghiệp.
Xem xét ví dụ trước của chúng ta về việc kích hoạt các ứng dụng AI tận dụng bảng danh mục gen để trả lời các câu hỏi liên quan đến khám phá thuốc. Câu hỏi chúng ta muốn trả lời là: Có bao nhiêu gen mã hóa protein trên mỗi nhiễm sắc thể?
Giả sử chúng ta đã tạo từ điển kinh doanh trong Amazon SageMaker Catalog. Đoạn code sau lấy các định nghĩa bảng cần thiết để trả lời câu hỏi này:
# Khởi tạo Unified Studio Catalog
client = UnifiedStudioClient()
# Gọi API danh mục kinh doanh trung tâm, SageMaker Catalog
response = client.get_table(
GetTableRequestTypeDef(
ProjectIdentifier=project_id,
TableName=gene
)
)
# Định nghĩa template đầu ra theo định dạng JSON với các trường quan tâm
# từ danh mục kinh doanh
return tdefinition
{
"TableName": response["TableName"],
"Description": response.get("Description", "No description available"),
"Columns": [
{
"Name": col["Name"],
"DataType": col["DataType"],
"BusinessDescription": col.get("BusinessGlossaryTerm", "")
}
]
}
Bây giờ, xây dựng template prompt của bạn sử dụng các định nghĩa bảng:
# Template prompt để truyền schema bảng gen và các mô tả
# giúp mô hình trả lời các câu hỏi liên quan đến dữ liệu danh mục gen.
prompt_template = (
"""
You are a friendly bot, an expert in the field of genomics.
## Task
Generate an ANSI SQL query related to drug discovery using the context
provided to you.
## Context
The context provided to you contains the schema of a table from a database
with detailed descriptions about the table and its columns, when to use
each column, and for what purpose.
"TABLE-DEFINITION: {tdefinition}\n\n"
"EXAMPLES: {examples}\n\n"
## Model Instructions
- You MUST think before generating the SQL
- SQL MUST be syntactically correct and in ANSI format
## Response Style and Output Format Requirements
- You MUST respond with a SQL query
- You MUST generate the SQL response using the CONTEXT provided to you
## Success Criteria
- Generate syntactically correct ANSI SQL
"""
)
Câu trả lời của mô hình:
SELECT chromosome, COUNT(*) AS gene_count
FROM human_gene_catalog
WHERE array_length(uniprotprimaryaccessions) > 0
GROUP BY chromosome
ORDER BY gene_count DESC;
Ứng dụng AI giả thuyết của chúng ta sẽ có thể trả lời câu hỏi một cách chính xác nhờ các định nghĩa trong từ điển kinh doanh, được truyền dưới dạng đối tượng JSON, mà không cần một nhà phát triển ứng dụng hoặc kỹ sư prompt nào phải thêm rõ ràng từng định nghĩa vào prompt. Miễn là bạn có các định nghĩa từ điển kinh doanh rõ ràng và toàn diện, bạn có thể tạo các prompt theo định dạng này có thể được tái sử dụng với hầu hết mọi bảng trong tổ chức, trên nhiều ứng dụng AI khác nhau. Cách tiếp cận này loại bỏ nhu cầu người quản lý dữ liệu phải chỉ định dữ liệu nào cần thiết để trả lời câu hỏi cho một ứng dụng AI nhất định và cho phép khả năng mở rộng liền mạch.
Tiếp theo, chúng ta sẽ tập trung vào hai yếu tố chính khác trong mô hình vận hành quản trị dữ liệu AI: chất lượng dữ liệu và bảo mật dữ liệu.
Chất Lượng Dữ Liệu (Data Quality)
Chất lượng thông tin chi tiết của bạn phụ thuộc trực tiếp vào chất lượng dữ liệu bạn sử dụng. Các tổ chức thường quen thuộc với các kiểm tra chất lượng dữ liệu tiêu chuẩn cho dữ liệu có cấu trúc, chẳng hạn như xác định các giá trị null trong các cột và xác thực các kiểu dữ liệu. Theo thời gian, nhiều tổ chức cũng đã phát triển các khung toàn diện cho các xác thực dành riêng cho trường hợp sử dụng, bao gồm kiểm tra chuyển đổi dấu thời gian sang thời gian epoch, xác thực phạm vi, v.v. Ngày nay, đây là yêu cầu cơ bản trong các đường ống chuyển đổi dữ liệu cho dữ liệu có cấu trúc.
Tuy nhiên, các trường hợp sử dụng AI hiện đại có xu hướng tận dụng nhiều dữ liệu phi cấu trúc hơn, vốn có trong hầu hết các tổ chức ở số lượng lớn hơn. Vì vậy, trong phần còn lại của chương này, chúng ta sẽ tập trung vào quản trị dữ liệu qua lăng kính của AI sử dụng dữ liệu phi cấu trúc.
Mặc dù có những tiến bộ trong chất lượng dữ liệu có cấu trúc, nhiều tổ chức vẫn phải đối mặt với những thách thức trong việc thậm chí xác định chất lượng dữ liệu nghĩa là gì đối với dữ liệu phi cấu trúc, cũng như trong việc phát triển các quy tắc xác thực dữ liệu và chiến lược hiệu quả để giải quyết những thách thức này cho các sáng kiến AI thành công.
Có nhiều quy tắc xác thực dữ liệu khác nhau có thể được áp dụng cho dữ liệu phi cấu trúc, đặc biệt là văn bản. Các ví dụ phổ biến bao gồm:
- Xác thực định dạng file (File format validation): Đảm bảo các file ở các định dạng được chấp nhận như HTML, PDF, TXT, DOC hoặc PPT.
- Xác thực định dạng siêu dữ liệu (Metadata format validation): Kiểm tra xem các file siêu dữ liệu có ở các định dạng như JSON hay không.
- Kiểm tra trường siêu dữ liệu (Metadata field checks): Xác minh sự hiện diện và tính chính xác của các trường như tiêu đề, mô tả và danh mục cho một tài liệu nhất định.
- Trích xuất bảng (Table extraction): Trích xuất bảng từ các file PDF, DOC hoặc hình ảnh, cùng với tiêu đề liên quan.
- Trích xuất hình ảnh (Image extraction): Xác định và trích xuất các điểm quan tâm cụ thể từ hình ảnh, chẳng hạn như phát hiện đỉnh cao nhất trong một biểu đồ. Hình ảnh có thể là một phần của các file hình ảnh như PNG hoặc các loại tài liệu khác như PDF.
- Chuẩn hóa đầu trang, chân trang và văn bản (Header, footer, and text normalization): Xóa đầu trang và chân trang hoặc chuẩn hóa văn bản trong email và tài liệu HTML.
- Xác thực phạm vi (Range validation): Đảm bảo các giá trị văn bản được trích xuất nằm trong phạm vi chấp nhận được (ví dụ: xác minh rằng đánh giá là giá trị số từ 1 đến 5).
Danh sách này không đầy đủ. Các quy tắc xác thực dữ liệu cụ thể cần thiết sẽ phụ thuộc vào trường hợp sử dụng cụ thể. Ví dụ, khi xử lý email dịch vụ khách hàng, điều quan trọng là phải loại bỏ văn bản không liên quan — chẳng hạn như đầu trang, chân trang và chữ ký (được tô đậm trong Ví dụ 4-1) — để cung cấp cho mô hình ngôn ngữ đầu vào sạch hơn. Điều này không chỉ cải thiện chất lượng dữ liệu cho mô hình mà còn giảm tổng số token đầu vào, ảnh hưởng trực tiếp đến chi phí suy luận.
Ví dụ 4-1. Email dịch vụ khách hàng mẫu
Từ: *** <***> Gửi: Thứ Hai, ngày 6 tháng 4 năm 2026 8:00 PM Đến: *** <***> Chủ đề: Re: Hỗ trợ & Dịch vụ: Yêu cầu Báo giá Kính gửi Khách hàng, Chào buổi chiều. Cảm ơn bạn đã chọn XYZ LLC! Tôi rất vui được cung cấp báo giá cho mặt hàng đã đề cập. Nếu bạn có tài khoản với chúng tôi, vui lòng cung cấp số tài khoản và tôi sẽ cung cấp giá cho tài khoản của bạn. Nếu bạn chưa có tài khoản doanh nghiệp với chúng tôi và muốn thiết lập, vui lòng truy cập trang web của chúng tôi tại www.xyz.com và nhấp vào 'Tài khoản của tôi' ở góc trên bên phải. (Phần đầu trang/chân trang/chữ ký cần loại bỏ bằng regex)
Bạn thường sẽ sử dụng biểu thức chính quy (regex) trong ngôn ngữ lập trình ưa thích để loại bỏ các phần được tô đậm trong các email như thế này, vì những phần này không cần thiết cho các ứng dụng AI và có thể tạo ra nhiễu không mong muốn.
Bằng cách thiết lập các thực hành xác thực và chất lượng dữ liệu mạnh mẽ cho cả dữ liệu có cấu trúc và phi cấu trúc, các tổ chức tạo ra một nền tảng đáng tin cậy trên đó các mối quan tâm quản trị rộng hơn như bảo mật, quyền riêng tư và AI có trách nhiệm có thể được giải quyết hiệu quả. Bảo mật dữ liệu có mức độ ưu tiên cao nhất, đến mức hai phần tiếp theo về AI có trách nhiệm và quyền riêng tư và bảo mật dữ liệu cho AI tạo sinh được dành riêng cho chủ đề này.
AI Có Trách Nhiệm (Responsible AI)
Không có một định nghĩa đơn nhất, được chấp nhận phổ biến cho AI có trách nhiệm. Tuy nhiên, theo các tổ chức nổi bật như Viện Kỹ thuật Điện và Điện tử (IEEE), Tổ chức Hợp tác Kinh tế và Phát triển (OECD), Trung tâm Internet & Xã hội Berkman Klein của Đại học Harvard, cũng như Hướng dẫn Đạo đức cho AI Đáng tin cậy của EU và Khuyến nghị về Đạo đức AI của UNESCO, chúng ta sẽ định nghĩa như sau: thực hành thiết kế, phát triển, triển khai và sử dụng các hệ thống AI theo những cách đạo đức, minh bạch, công bằng và có trách nhiệm giải trình, đảm bảo sự phù hợp với các giá trị của con người và phúc lợi xã hội.
Bảng 4-2 phác thảo các nguyên tắc cốt lõi của AI có trách nhiệm.
Bảng 4-2. Các nguyên tắc AI có trách nhiệm
| Nguyên tắc | Mô tả (AI...) |
|---|---|
| Công bằng (Fairness) | Tránh thiên kiến và phân biệt đối xử |
| Minh bạch (Transparency) | Đưa ra quyết định có thể giải thích và hiểu được |
| Trách nhiệm giải trình (Accountability) | Đảm bảo trách nhiệm về các quyết định là rõ ràng và có các cơ chế khắc phục |
| Quyền riêng tư và bảo mật (Privacy and security) | Bảo vệ dữ liệu cá nhân và đảm bảo bảo mật |
| Độ tin cậy (Reliability) | Hoạt động an toàn và như dự kiến |
| Giám sát của con người (Human oversight) | Duy trì sự kiểm soát và phán đoán của con người |
Hãy xem xét kỹ hơn từng nguyên tắc này và xem cách bạn có thể thực thi chúng trong các ứng dụng AI.
Công Bằng (Fairness)
Nguyên tắc công bằng, nói một cách đơn giản, quy định rằng ứng dụng AI không được thể hiện bất kỳ thiên kiến nào hoặc phân biệt đối xử trong các phản hồi của nó. Để minh họa, giả sử một công ty sử dụng công cụ tuyển dụng dựa trên AI để sàng lọc hồ sơ xin việc. Mục tiêu là nhanh chóng xác định các ứng viên hứa hẹn nhất dựa trên trình độ và lịch sử công việc của họ. Đây là ví dụ về cách thiên kiến vô ý có thể nảy sinh:
- Mô hình AI được đào tạo trên dữ liệu tuyển dụng trong quá khứ của công ty, qua nhiều năm đã ưu tiên ứng viên từ một số trường đại học nhất định và vô tình bỏ qua ứng viên từ các trường khác, bao gồm các cơ sở phục vụ cộng đồng thiểu số.
- Không có đánh giá về sự công bằng, mô hình AI học các sở thích lịch sử này và gán thứ hạng cao hơn cho ứng viên từ các trường được ưu tiên — ngay cả khi họ có trình độ tương tự hoặc yếu hơn so với người khác.
- Kết quả là, ứng viên có trình độ từ nền tảng ít được đại diện hơn có cơ hội thấp hơn để được chọn phỏng vấn, củng cố sự bất bình đẳng hiện có.
Công cụ phát hiện thiên kiến (Tools to detect bias): Để giảm thiểu thiên kiến, cần có cách phát hiện nó trước. Bảng 4-3 liệt kê một số tùy chọn nguồn mở phổ biến, cùng với các công cụ từ các nhà cung cấp đám mây lớn.
Bảng 4-3. Công cụ đánh giá sự công bằng (Fairness evaluation tools)
| Nhà cung cấp | Công cụ | Tính năng nổi bật |
|---|---|---|
| AWS | SageMaker Clarify, Bedrock với LLM làm giám khảo | Phân tích thiên kiến tập dữ liệu/mô hình, chỉ số pháp lý, bảng điều khiển khả năng giải thích |
| Azure | Fairlearn (tích hợp), Responsible AI Dashboard | Bảng điều khiển tương tác, thuật toán giảm thiểu, tích hợp quy trình làm việc đầy đủ |
| Google Cloud | Vertex AI Fairness Evaluation, What-If Tool | Chỉ số công bằng tích hợp, phân tích tương tác, chẩn đoán nhóm con |
| Nguồn mở | IBM AIF360, Fairlearn, Aequitas | Chỉ số công bằng phong phú, bảng điều khiển, thuật toán giảm thiểu thiên kiến |
Cách xử lý thiên kiến (How to handle bias): Hai cách tiếp cận phổ biến, đặc biệt khi sử dụng mẫu RAG, là kỹ thuật prompt và triển khai guardrail.
Kỹ thuật prompt bao gồm việc thiết kế cẩn thận các prompt để hướng LLM về phía các phản hồi trung lập, toàn diện và phù hợp ngữ cảnh. Nếu quan sát thấy đầu ra có thiên kiến, prompt có thể được diễn đạt lại để bao gồm các chỉ thị rõ ràng về tính trung lập hoặc để loại trừ rõ ràng các thuộc tính nhạy cảm.
Kỹ thuật phổ biến khác là sử dụng các guardrail bảo mật để xác định các chủ đề bị từ chối, cấu hình bộ lọc nội dung và thiết lập ngưỡng lọc nội dung có hại hoặc có thiên kiến. Các công cụ như Amazon CloudWatch có thể được sử dụng để giám sát và phân tích khi nào và cách thức các can thiệp thiên kiến được kích hoạt. Guardrail cũng có thể được sử dụng để tự động xóa hoặc biên tập PII, giúp ngăn chặn các đầu ra không công bằng hoặc mang tính phân biệt đối xử liên quan đến dữ liệu nhạy cảm.
Minh Bạch (Transparency)
Nguyên tắc minh bạch quy định rằng các quy trình và quyết định được đưa ra bởi các hệ thống AI phải có thể giải thích và hiểu được đối với con người. Khả năng giải thích và giám sát là hai trọng tâm để đạt được mức độ minh bạch phù hợp.
Amazon Bedrock cung cấp các tính năng minh bạch mô hình tích hợp: - Theo dõi nguồn gốc phản hồi (Response provenance tracking): Hiển thị dữ liệu nào từ ngữ cảnh đã ảnh hưởng đến đầu ra qua trích dẫn trong Bedrock Converse API. - Cơ chế tính điểm độ tin cậy (Confidence scoring mechanisms): Chỉ ra mức độ chắc chắn của mô hình. - Số lượng token đầu vào và đầu ra (Input and output token counts): Cung cấp khả năng hiển thị về kích thước của prompt và phản hồi được tạo ra. - Các bước suy luận trong đầu ra (Reasoning steps in the output): Khi sử dụng mô hình suy luận để suy luận. - Đóng dấu nước cho nội dung được tạo ra (Watermarking for generated content): Các mô hình Titan của Bedrock bao gồm đóng dấu nước vô hình cho hình ảnh được tạo ra.
Amazon SageMaker cung cấp thêm các công cụ giải thích: SageMaker Clarify cho phân tích tầm quan trọng tính năng và phát hiện thiên kiến; SageMaker Model Monitor để theo dõi liên tục hành vi và độ trôi dạt hiệu suất; SageMaker Experiments để so sánh có hệ thống các biến thể mô hình.
Nền tảng thứ hai của minh bạch là giám sát. Nhật ký kiểm toán và giám sát cho phép theo dõi việc sử dụng mô hình và các hành động hệ thống. Trên AWS: CloudTrail và CloudWatch logs; trên Azure: Azure Log Analytics, diagnostic logging và Azure Monitor logs; trên GCP: Cloud Logging và Cloud Audit Logs. Các công cụ quan sát bổ sung như Langfuse, MLFlow Tracing, Datadog LLM Observability và Helicone hỗ trợ theo dõi chi phí, độ trễ và dấu vết phản hồi.
Tracing với LLM (Tracing with LLMs): Một kỹ thuật giám sát mạnh mẽ cho hệ thống GenAI là tracing, nắm bắt toàn bộ vòng đời của prompt, tương tác mô hình và phản hồi. Hình 4-2 minh họa một trace mẫu từ giao diện quan sát Langfuse cho yêu cầu được phục vụ bởi mô hình Amazon Nova trong Amazon Bedrock. Một trace trong Langfuse đại diện cho một yêu cầu hoặc hoạt động duy nhất, chứa đầu vào và đầu ra tổng thể cùng siêu dữ liệu về yêu cầu.
Các phần được đánh dấu trong trace này bao gồm: (1) cấu hình LLM và các chỉ số đầu ra (độ trễ, chi phí, số token tối đa); (2) ngữ cảnh tăng cường được gửi đến LLM; (3) câu hỏi của người dùng; (4) đầu ra của mô hình; (5) siêu dữ liệu bổ sung. Những yếu tố này cho bạn thông tin đầu cuối về cách đường ống RAG xử lý một yêu cầu duy nhất, giúp gỡ lỗi vấn đề và tối ưu hóa hiệu suất.
Thu thập và xuất telemetry (Capturing and exporting telemetry): OpenTelemetry (OTel) cung cấp khung linh hoạt và được áp dụng rộng rãi để thu thập dữ liệu telemetry cho cả hệ thống agent đơn và đa agent. Các mẫu thu thập phổ biến gồm: instrumentation agent gốc (ghi trực tiếp vào file nhật ký hoặc stdout theo JSON/CSV); xuất sang hệ thống giám sát chuyên dụng (Prometheus exposition qua HTTP endpoint); và xuất trực tiếp sang backend (Elasticsearch, Logstash, hoặc các dịch vụ cloud như AWS CloudWatch, Azure Monitor, Google Cloud Operations).
Trách Nhiệm Giải Trình (Accountability)
Các yêu cầu trách nhiệm giải trình chính gồm: - Chuỗi trách nhiệm rõ ràng cho các kết quả, theo dõi ai chịu trách nhiệm về các giai đoạn và thành phần khác nhau. - Các cơ chế hiệu quả để khắc phục và sửa chữa khi có sự cố.
Trách nhiệm (Responsibility): - Sử dụng dấu vết kiểm toán đám mây và phiên bản hóa qua các đường ống GenAIOps để quy kết hành động và thay đổi cho người dùng cụ thể. - Duy trì tài liệu về dòng dõi mô hình, triển khai và sử dụng dữ liệu bằng các công cụ tích hợp và ghi nhật ký trên các nhà cung cấp. - Tham khảo Cloud Security Alliance's AI Controls Matrix để ánh xạ và ghi lại trách nhiệm giữa các nhóm.
Sửa chữa (Correction): - Sử dụng kiểm tra cơ sở ngữ cảnh để phát hiện ảo giác và lọc phản hồi, xác minh rằng đầu ra mô hình là chính xác và có căn cứ trong tài liệu nguồn. - Cho phép giám sát HITL và kháng nghị, cho phép người đánh giá ghi đè, xử lý lại hoặc hoàn nguyên các quyết định AI khi được gắn cờ.
Quyền Riêng Tư và Bảo Mật (Privacy and Security)
Quyền riêng tư và bảo mật dữ liệu bao gồm các biện pháp như mã hóa, kiểm soát truy cập, che giấu dữ liệu và giám sát thường xuyên. Các chiến lược được khuyến nghị:
Mã hóa khi lưu trữ và trong quá trình truyền (Encryption at rest and in transit): Tất cả file dữ liệu phải được mã hóa cả khi lưu trữ ("at rest") và khi truyền ("in transit"). Các nhà cung cấp đám mây lớn cung cấp khả năng mã hóa tích hợp cho dịch vụ lưu trữ (Amazon S3, Azure Blob Storage, v.v.) để tự động hóa khía cạnh này.
Xác định và biên tập dữ liệu nhạy cảm (Sensitive data identification and redaction): Cần xác định và xử lý thích hợp thông tin nhạy cảm trong dữ liệu phi cấu trúc. Đối với bảo vệ PII mạnh mẽ, tổ chức nên sử dụng các công cụ chuyên dụng như Amazon Bedrock Guardrails (phát hiện và biên tập PII tại thời điểm chạy), Amazon Comprehend, Amazon Macie, Azure AI Language PII Detection hoặc Google Cloud DLP API.
Kiểm soát truy cập trong kho vector (Access control in vector stores): Khi lưu trữ dữ liệu phi cấu trúc trong cơ sở dữ liệu vector, cần triển khai kiểm soát truy cập phản ánh bảo mật cấp hàng (RLS). Điều này đạt được bằng cách thiết kế schema kho vector để bao gồm các trường siêu dữ liệu liên quan (ví dụ: gắn thẻ mỗi đoạn vector với tên người dùng tương ứng để lọc kết quả tìm kiếm theo người dùng).
Bằng cách áp dụng các biện pháp này, các tổ chức có thể giảm đáng kể nguy cơ vi phạm dữ liệu và duy trì tính bảo mật và toàn vẹn của tài sản dữ liệu phi cấu trúc.
Độ Tin Cậy (Reliability)
Độ tin cậy trong AI có trách nhiệm có nghĩa là đảm bảo các hệ thống mạnh mẽ, nhất quán trong hiệu suất và an toàn. Kiểm tra kỹ lưỡng trước khi triển khai là bắt buộc. Các công cụ từ nhà cung cấp đám mây lớn: - AWS: SageMaker Clarify (phát hiện thiên kiến trước triển khai), SageMaker Model Monitor (theo dõi hiệu suất và phát hiện độ trôi dạt), Amazon Bedrock Guardrails (lọc nội dung có hại và ảo giác). - Azure: Responsible AI Dashboard (phân tích lỗi, hiểu phân phối lỗi), Azure Monitor (giám sát liên tục sức khỏe mô hình và cơ sở hạ tầng). - GCP: Vertex AI Model Evaluation (xác thực trước triển khai), Vertex AI Model Monitoring (phát hiện độ trôi dạt và hành vi bất ngờ), Audit Manager với Recommended AI Controls Framework.
Giám Sát Của Con Người (Human Oversight)
Giám sát của con người trong AI đảm bảo sự kiểm soát có ý nghĩa của con người đối với các hệ thống AI và sự tham gia của con người trong vòng lặp (HITL), đặc biệt cho các quyết định quan trọng. Cách tiếp cận này được yêu cầu bởi các quy định như EU AI Act. Bảng 4-4 liệt kê các giai đoạn trong vòng đời ứng dụng GenAI nơi sự tham gia HITL phải được xem xét.
Bảng 4-4. Khuyến nghị về sự tham gia HITL trên các giai đoạn vòng đời ứng dụng agentic và RAG
| Giai đoạn vòng đời | HITL bắt buộc? | Ví dụ nhiệm vụ HITL |
|---|---|---|
| Thu thập và chuẩn bị dữ liệu | Đôi khi | Kiểm tra điểm ngẫu nhiên chất lượng dữ liệu, xác thực các lựa chọn loại trừ/bao gồm |
| Gán nhãn và chú thích dữ liệu | Luôn luôn | Đảm bảo nhãn chính xác, giải quyết mơ hồ, sửa lỗi |
| Đào tạo và tinh chỉnh mô hình | Đôi khi | Thiết kế prompt, xem xét dữ liệu tinh chỉnh, đặt ngưỡng |
| Đánh giá và xác thực | Luôn luôn | Đánh giá thủ công về tính thực tế, an toàn, thiên kiến và vấn đề đạo đức |
| Triển khai/tích hợp | Đôi khi | Phê duyệt quyết định ra mắt, đặc biệt khi rủi ro cao |
| Suy luận/phục vụ | Cho nhiệm vụ quan trọng | Can thiệp thời gian thực trong các quyết định quan trọng, có tác động cao hoặc nhạy cảm về an toàn |
| Giám sát và phản hồi | Thường xuyên | Xem xét đầu ra được gắn cờ, điều tra các trường hợp ngoại lệ hoặc leo thang |
| Đào tạo lại và cải thiện | Đôi khi | Ưu tiên các lĩnh vực đào tạo lại dựa trên thất bại được con người xác minh |
Sự tham gia HITL là bắt buộc đối với các giai đoạn quan trọng ảnh hưởng đến an toàn, tuân thủ hoặc các cân nhắc đạo đức và được khuyến nghị cho giám sát liên tục ở những nơi khác để duy trì hoạt động AI có trách nhiệm.
Quyền Riêng Tư Dữ Liệu và Bảo Mật cho Ứng Dụng GenAI (Data Privacy and Security for GenAI Applications)
Có một sự dịch chuyển mô hình trong xử lý quyền riêng tư và bảo mật dữ liệu cho dữ liệu phi cấu trúc, được thúc đẩy bởi việc áp dụng nhanh chóng các ứng dụng AI xử lý, tạo ra và suy luận trên khối lượng lớn văn bản, hình ảnh và các định dạng phi cấu trúc khác — các loại dữ liệu mà các khung bảo mật truyền thống không bao giờ được thiết kế để quản lý.
Bảng 4-5 minh họa các khả năng quyền riêng tư và bảo mật dữ liệu chính mà ứng dụng AI của bạn cần xem xét.
Bảng 4-5. Ma trận khả năng quyền riêng tư và bảo mật dữ liệu
| Khả năng | Quyền riêng tư dữ liệu | Bảo mật |
|---|---|---|
| Lọc nội dung và an toàn | ✓ | |
| Bảo vệ thông tin nhạy cảm (PII) | ✓ | |
| Hạn chế chủ đề và lọc từ | ✓ | ✓ |
| Ngăn ngừa ảo giác (tính thực tế) | ✓ | |
| Mã hóa dữ liệu (at rest/in transit) | ✓ (cấp nền tảng) | |
| Kiểm soát truy cập và xác thực (IAM) | ✓ (cấp nền tảng) | |
| Bảo mật mạng (VPC, PrivateLink) | ✓ (cấp nền tảng) | |
| Ghi nhật ký kiểm toán và giám sát | ✓ (cấp nền tảng) | |
| Bảo vệ dữ liệu đầu cuối | ✓ | ✓ |
Phần này tập trung vào các khả năng quyền riêng tư dữ liệu, vì đây thường là lĩnh vực doanh nghiệp phải đối mặt với những thách thức quan trọng nhất. Quyền riêng tư dữ liệu (data privacy) đề cập đến thực hành bảo vệ thông tin cá nhân hoặc nhạy cảm khỏi truy cập, sử dụng, tiết lộ hoặc hủy trái phép. Nó bao gồm các chính sách, quy trình và công nghệ được thiết kế để đảm bảo rằng dữ liệu cá nhân được thu thập, xử lý, lưu trữ và chia sẻ theo những cách tôn trọng quyền của họ và tuân thủ các yêu cầu pháp lý và quy định.
Bảo Vệ Thông Tin Nhạy Cảm (Sensitive Information Protection)
Có một số kỹ thuật để xử lý dữ liệu nhạy cảm: - Kỹ thuật prompt với LLM. - Các công cụ bên ngoài như Amazon Bedrock Guardrails, Amazon Comprehend, Amazon Macie, Azure AI Language PII Detection và Google Cloud Data Loss Prevention (DLP) API.
Trong phần này, chúng ta sẽ minh họa cách sử dụng kỹ thuật đầu tiên để xử lý thông tin nhạy cảm trong dữ liệu văn bản, sử dụng email dịch vụ khách hàng mẫu làm ví dụ. Đoạn code sau đây hiển thị template prompt để xác định và biên tập các yếu tố PII:
# Template cho thông điệp người dùng với các placeholder
prompt_template = (
"""
## Task
You MUST identify SENSITIVE data elements from the E-MAIL provided to you.
## Context
The email consists of interactions from external customers with customer
service representatives of XYZ, a medical device manufacturer and seller.
"EXAMPLES: {email_examples} \n\n"
"ENTITIES: {entities} \n\n"
"E-MAIL: {email} \n\n\n"
## Model Instructions
-You MUST use the EXAMPLES provided to arrive at the right intent for a
given email.
-You MUST use the ENTITIES to find all the sensitive elements of interest
in the email.
-COUNT the number of exchanges between XYZ customer reps and external
customers in the E-MAIL thread.
-Replace ALL the sensitive entities from the E-MAIL using *****.
## Response Style and Output Format Requirement
-You MUST respond in text format.
-In your response, DO NOT start with "Let me analyze the email and determine
the intent".
-You MUST generate the response with a confidence score (0-100%) based on
the CONTEXT and EXAMPLES provided to you.
"""
)
Ví dụ 4-3 cho thấy đầu ra mô hình tạo ra, với các thực thể nhạy cảm trong email được che giấu:
Ví dụ 4-3. Phản hồi của mô hình với PII đã được xác định và biên tập
Từ: ***** Gửi: Thứ Hai, ngày 6 tháng 4 năm 2026 8:00 PM Đến: ***** ... Kính gửi *****, ... Trân trọng, *****
Các thực thể nhạy cảm được phát hiện: 1. Họ và tên đầy đủ: Mark Lamberg (được thay thế bằng *****) 2. Địa chỉ email: markl@xyz.com (thay bằng *****), dbarns@mycompany.com (thay bằng *****)
Số lượng trao đổi: 1 (phản hồi dịch vụ khách hàng ban đầu)
Điểm tin cậy: 95% (dựa trên nhận dạng rõ ràng các thực thể nhạy cảm và theo ví dụ được cung cấp)
CẢNH BÁO: Lưu ý rằng trong khi cách tiếp cận dựa trên prompt được minh họa ở đây hoạt động với các yếu tố PII phổ biến như tên và địa chỉ email, nó không nên được dựa vào như cơ chế phát hiện PII duy nhất. Để bảo vệ toàn diện, bạn cần sử dụng các công cụ tinh vi hơn như Amazon Bedrock Guardrails, có thể phát hiện và biên tập PII trong cả đầu vào của người dùng và đầu ra của mô hình tại thời điểm chạy.
Hạn Chế Chủ Đề và Lọc Từ (Topic Restriction and Word Filtering)
Hiểu tính nhạy cảm với dữ liệu là điều cốt lõi để bảo vệ thông tin bảo mật và đảm bảo tuân thủ các quy định quản lý. Khi triển khai các mô hình nền tảng, các tổ chức có thể tận dụng các công cụ lọc nguyên sinh của nhà cung cấp. Một số nhà cung cấp, chẳng hạn như AWS, cung cấp khả năng lọc chủ đề và từ tích hợp với bất kỳ mô hình nào, cho phép áp dụng các bộ lọc này ngay cả khi sử dụng các mô hình tùy chỉnh.
Hình 4-3 cho thấy cách tích hợp hạn chế chủ đề và lọc từ vào thiết kế ứng dụng — guardrail được áp dụng ở cả đầu vào (prompt) và đầu ra (response).
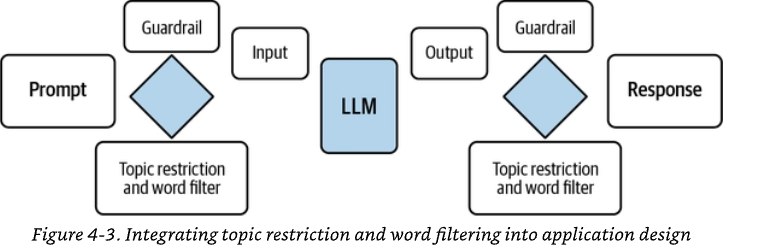
Có một số cách để triển khai các bộ lọc này. Khi vận hành trong môi trường đám mây công cộng, các tổ chức có thể tận dụng các công cụ gốc của nhà cung cấp. Các công cụ lọc nội dung phổ biến bao gồm: Azure AI Content Safety; Google Vertex AI Safety Filters; Amazon Bedrock Guardrails; Llama Guard (nguồn mở); NVIDIA NeMo Guardrails (nguồn mở).
Để minh họa cách bạn có thể tận dụng các công cụ này trong ứng dụng AI, hãy xem xét ví dụ xây dựng chatbot AI cho công ty fintech ABC Inc. Các mô hình frontier như Claude và ChatGPT được xây dựng để tuân theo các hướng dẫn prompt một cách đáng tin cậy. Bạn có thể sử dụng một prompt đơn giản để thiết lập một lớp bảo vệ ban đầu bằng cách hướng dẫn mô hình chỉ trả lời các câu hỏi liên quan đến các chủ đề phù hợp với ứng dụng:
system_prompt = f"""You are a virtual customer service agent for ABC Inc., a
fintech company in the USA.
<rules>
- Only respond to questions related to ABC Inc.'s {products} and {services}.
- If asked about anything else, politely inform the user that you can only
assist with ABC Inc.-related inquiries.
- Do not discuss any sensitive financial information or provide financial
advice.
- Keep responses concise and professional.
- The company phone number is +100022200
- The company email is abc@example.com
</rules>
"""
Khi sử dụng prompt này, chatbot trả lời đúng câu hỏi về sản phẩm của công ty trong khi từ chối trả lời câu hỏi về chủ đề không liên quan. Mặc dù cách tiếp cận này hoạt động tốt với một tập nhỏ hạn chế, các prompt nhanh chóng trở nên phức tạp và khó quản lý khi các kiểm soát quyền riêng tư và bảo mật cấp doanh nghiệp yêu cầu các quy tắc mở rộng hơn cho mô hình tuân theo. Trong các trường hợp này, việc sử dụng các công cụ lọc nội dung như Amazon Bedrock Guardrails trở nên cần thiết.
Công Cụ Lọc (Filtering Tools)
Guardrail rất cần thiết để ràng buộc hành vi mô hình và thực thi các chính sách an toàn. Trong Amazon Bedrock, bạn xác định một guardrail thông qua AWS Management Console hoặc theo chương trình qua API. Hình 4-4 và 4-5 mô tả cấu hình guardrail trong console cho lọc chủ đề và lọc từ tương ứng.
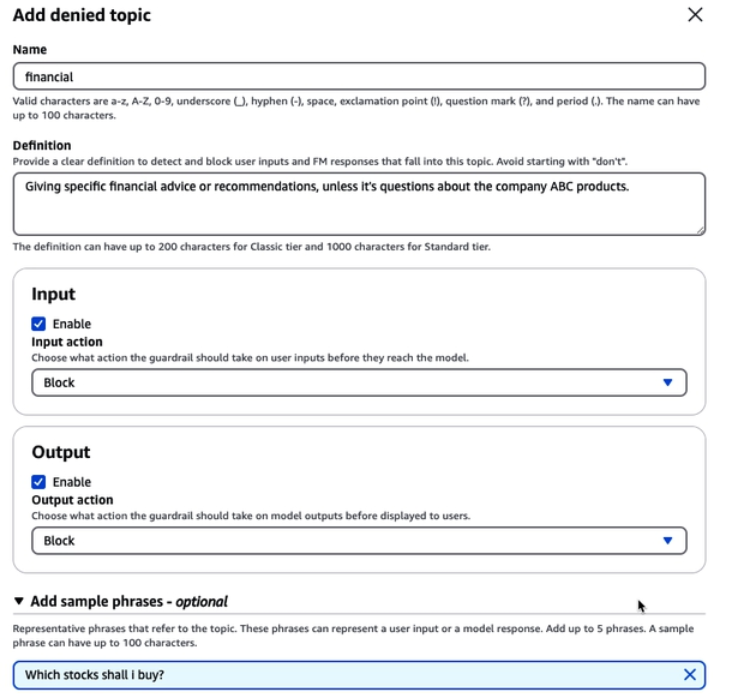
Hộp kiểm "Filter profanity" đơn giản hóa việc tự động phát hiện và chặn các đầu vào và phản hồi của người dùng liên quan đến chủ đề này, mà không cần liệt kê rõ ràng từng từ hoặc cụm từ cần loại bỏ. Bạn cũng có thể chọn thêm tối đa 10 từ hoặc cụm từ để lọc. Cách tiếp cận này có tính mô-đun và dễ quản lý hơn so với cách tiếp cận được minh họa trong mục "Hạn chế Chủ đề và Lọc Từ", nơi tất cả các quy tắc được đặt rõ ràng vào một prompt duy nhất.

Bạn có thể cấu hình tối đa 30 chủ đề cho mỗi guardrail, cho phép LLM tập trung chính xác hơn vào các yêu cầu cụ thể của ứng dụng AI. Đoạn code sau đây cho thấy cách sử dụng Amazon Bedrock Guardrails theo chương trình:
response = bedrock.converse(
modelId="anthropic.claude-haiku-4-5-20251001-v1",
### You can replace the model with any other preferred option
system=[
{
"text": system_prompt
}
],
messages=[
{
"role": "user",
"content": [
{
"guardContent": {
"text": {
"text": user_input
}
}
}
]
}
],
guardrailConfig={
"guardrailIdentifier": "ABCDEFG", ### Replace with your guardrail ID
"guardrailVersion": "DRAFT", ### Replace with version number if published
"trace": "enabled"
}
)
Chúng ta sử dụng template Bedrock Converse API tiêu chuẩn và bao gồm trường guardrailConfig để áp dụng guardrail cho yêu cầu. Guardrail identifier và version có thể được lấy từ AWS Management Console trong phần Amazon Bedrock Guardrails hoặc theo chương trình sử dụng Bedrock API.
Bảo Vệ Dữ Liệu Đầu Cuối (End-to-End Data Protection)
Bất kể bạn lưu trữ ứng dụng AI ở đâu, nó có thể trực tiếp hoặc gián tiếp chạm đến một số thành phần mà bạn nên xem xét bảo vệ. Ví dụ, các cuộc gọi API của ứng dụng đến mô hình nền tảng và dữ liệu đầu vào/đầu ra được trao đổi trong các cuộc gọi đó phải được mã hóa.
Bảo vệ dữ liệu trong bối cảnh AI tạo sinh có thể đạt được bằng cách kết hợp mã hóa khi lưu trữ và trong quá trình truyền. Bảng 4-6 minh họa các thành phần khác nhau mà ứng dụng của bạn có thể gặp phải và chỉ ra loại mã hóa nào bạn phải xem xét cho từng thành phần.
Bảng 4-6. Ma trận mã hóa đầu cuối cho ứng dụng AI
| Thành phần | Mã hóa at rest | Mã hóa in transit | Mô tả |
|---|---|---|---|
| Lưu trữ dữ liệu | Có | Có | Cơ sở dữ liệu, data lake và hệ thống tệp chứa dữ liệu đào tạo, prompt và đầu ra |
| Artifacts mô hình | Có | Có | Mô hình đã đào tạo, checkpoint và trọng số được lưu trữ để triển khai hoặc tái sử dụng |
| Đường ống dữ liệu đầu vào | Có | Có | Đường ống nhập và tiền xử lý dữ liệu di chuyển dữ liệu từ nguồn thô đến lưu trữ hoặc mô hình |
| Suy luận và API endpoints | N/A | Có | Các kênh giao tiếp cho yêu cầu người dùng và phản hồi AI |
| Giao tiếp dịch vụ nội bộ | N/A | Có | Dữ liệu được trao đổi giữa các microservice, compute nodes hoặc container trong ứng dụng |
| Lưu trữ dữ liệu đầu ra | Có | Có | Nội dung được tạo ra, nhật ký và siêu dữ liệu được lưu trữ sau suy luận hoặc tạo |
| Hệ thống sao lưu và lưu trữ | Có | N/A | Sao lưu dữ liệu và mô hình |
| Cấu hình và bí mật | Có | Có | API key, thông tin xác thực và các file cấu hình được sử dụng bởi ứng dụng |
Khi hoạt động trong môi trường đám mây công cộng, quản lý mã hóa được đơn giản hóa một phần bởi mô hình trách nhiệm chung của nhà cung cấp, đảm bảo một số thành phần thay mặt bạn. Tuy nhiên, điều quan trọng là phải hiểu cách trách nhiệm này được phân chia và đảm bảo rằng việc triển khai của họ đáp ứng các tiêu chuẩn bảo mật của tổ chức.
LLMOps: Điều Phối Quy Trình Làm Việc AI (LLMOps: AI Workflow Orchestration)
LLMOps đề cập đến tập hợp các thực hành, công cụ và phương pháp luận để quản lý vòng đời đầy đủ của các ứng dụng mô hình ngôn ngữ lớn, bao gồm phát triển, triển khai và các hoạt động liên tục. Điều phối trong bối cảnh này bao gồm việc điều phối một chuỗi các nhiệm vụ (chẳng hạn như tuyển dụng dữ liệu, đào tạo mô hình, truy xuất, đánh giá và giám sát) để đảm bảo khả năng mở rộng, khả năng tái tạo và khả năng sử dụng tài nguyên. Khi các hệ thống dựa trên LLM trở nên phức tạp hơn, đặc biệt là những hệ thống tận dụng RAG hoặc AI agentic, điều phối mạnh mẽ là điều quan trọng cho độ tin cậy và hiệu suất của ứng dụng.
Điều phối quy trình làm việc AI tạo thành xương sống của LLMOps hiện đại, kết nối nhập dữ liệu, truy xuất, kỹ thuật prompt, thực thi mô hình, tổng hợp kết quả, xác thực và các vòng phản hồi. Trong các hệ thống RAG, nó kiểm soát luồng dữ liệu giữa các thành phần tìm kiếm và tạo; trong các hệ thống AI agentic, nó điều phối nhiều agent chuyên biệt để giải quyết các nhiệm vụ phức tạp một cách cộng tác. Điều phối hiệu quả không chỉ hợp lý hóa các hoạt động mà còn cho phép mở rộng, lặp lại nhanh và tuân thủ các yêu cầu quản trị và giám sát của doanh nghiệp.
Các Mẫu Điều Phối cho Ứng Dụng AI (Orchestration Patterns for AI Applications)
Khi các hệ thống AI phát triển từ các tương tác yêu cầu/phản hồi đơn giản sang các hành vi tự trị, hướng mục tiêu, một số mẫu điều phối riêng biệt đã xuất hiện. Mỗi mẫu cung cấp các sự đánh đổi khác nhau giữa sự phức tạp, tính linh hoạt và kiểm soát. Hiểu chúng giúp bạn chọn kiến trúc phù hợp cho trường hợp sử dụng cụ thể của bạn.
Điều phối tuyến tính (chained) (Linear chained orchestration): Với điều phối tuyến tính, được minh họa trong Hình 4-6 cho một ví dụ bán lẻ, việc truy xuất dữ liệu và các bước tạo được thực hiện theo một trình tự nghiêm ngặt — ví dụ: truy xuất các đoạn văn bản liên quan → chuyển đến LLM để tổng hợp. Mẫu này đơn giản hóa việc gỡ lỗi và cho phép giám sát dễ dàng.
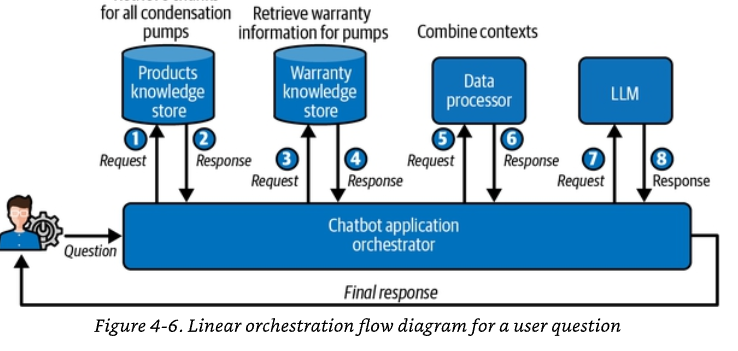
Điều phối này có thể là một ứng dụng Python đơn giản chạy một dịch vụ trong đám mây công cộng (chẳng hạn như AWS Lambda trên AWS hoặc Azure Functions trên Microsoft Azure). Sơ đồ minh họa cách người dùng tương tác, chẳng hạn như khách hàng muốn biết thông tin về máy bơm làm đặc, thông qua ứng dụng chatbot. Các bước sau đây mô tả cách ứng dụng đơn lẻ trả lời câu hỏi của người dùng này:
- Bộ điều phối gửi yêu cầu đến dịch vụ xử lý dữ liệu ứng dụng để kết hợp ngữ cảnh.
- Dịch vụ xử lý dữ liệu tìm kiếm tất cả các đoạn trong cơ sở kiến thức sản phẩm liên quan đến máy bơm làm đặc, xếp hạng và gửi kết quả trở lại.
- Dịch vụ xử lý dữ liệu gửi yêu cầu bổ sung tới cơ sở kiến thức bảo hành cho máy bơm.
- Cơ sở kiến thức bảo hành phản hồi với thông tin bảo hành cho máy bơm.
- Dịch vụ xử lý dữ liệu gửi yêu cầu tới LLM để kết hợp ngữ cảnh.
- LLM phản hồi với ngữ cảnh được tổng hợp từ cả hai cơ sở kiến thức.
- Dịch vụ xử lý dữ liệu tăng cường prompt với ngữ cảnh kết hợp và gửi đến LLM.
- LLM tạo ra phản hồi cuối cùng và gửi lại cho bộ điều phối.
Mẫu này dễ thiết lập và là lựa chọn tốt cho các triển khai cơ sở và trình diễn đơn giản. Các bước có thể bị bỏ qua. Nó cũng là một lựa chọn tốt cho các trường hợp sử dụng cơ sở và là bước đệm tốt cho các kịch bản phức tạp hơn, và là lựa chọn tốt cho các triển khai cấp độ nhập môn. Tuy nhiên, nó có thể phá vỡ các chức năng hiện có khi thêm chức năng mới và tạo ra các prompt đơn điệu nơi tất cả các quy tắc được đặt rõ ràng vào một prompt duy nhất.
Điều phối mô-đun và đồng thời (Modular and concurrent orchestration): Việc giải cấu trúc truy xuất, tạo và các đường ống khác tạo điều kiện cho khả năng mở rộng. Nó cũng cho phép một số bước chạy đồng thời và thích ứng với việc thêm các thành phần mới mà không ảnh hưởng đến từng thành phần. Hình 4-7 minh họa mẫu mô-đun và đồng thời cho cùng một trường hợp sử dụng được mô tả trong phần trước.
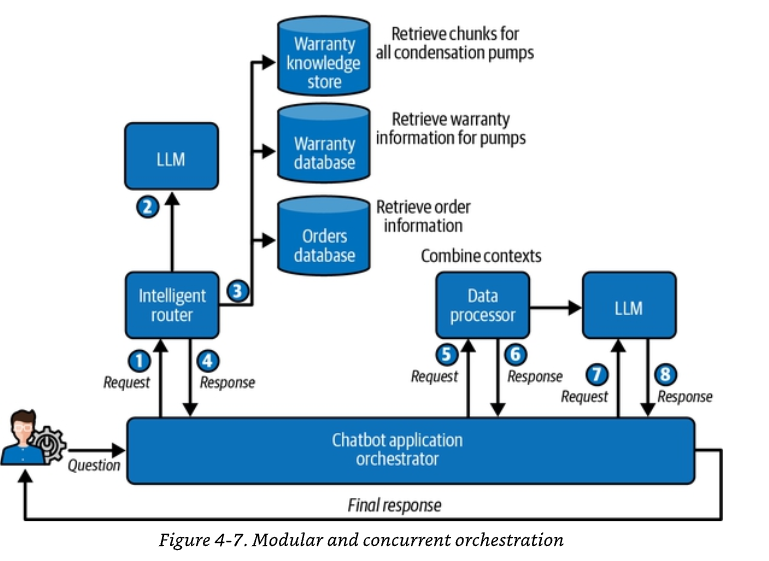
Mục tiêu chính là tách biệt điều phối hoàn toàn khỏi từng thành phần xử lý riêng lẻ thông qua một bộ điều phối chuyên dụng. Cách tiếp cận này không chỉ thúc đẩy sự tách biệt rõ ràng các mối quan tâm mà còn cho phép mô-đun hóa và tính linh hoạt lớn hơn trong hệ thống. Phân chia quá trình xử lý thành các thành phần rời rạc, dễ quản lý cho phép mỗi chức năng tập trung vào nhiệm vụ cụ thể của nó, trong khi bộ điều phối quản lý trình tự, điều phối và xử lý lỗi trên các thành phần này.
Yêu cầu trước tiên được gửi đến bộ điều phối chuyên dụng như AWS Step Functions hoặc Azure Logic Apps, quản lý trình tự bước, luồng logic và trạng thái trong một thiết kế đồng bộ:
- Bộ điều phối khởi tạo dịch vụ định tuyến thông minh, thường được triển khai như một ứng dụng Python hoặc Java trên nền tảng serverless. Thành phần định tuyến này hoạt động như trung tâm quyết định của hệ thống, xác định đường xử lý phù hợp cho từng yêu cầu đến.
- Yêu cầu người dùng có thể chứa một hoặc nhiều ý định (intents), chẳng hạn như truy xuất trạng thái đơn hàng, sửa đổi số lượng đơn hàng hoặc yêu cầu thông số kỹ thuật sản phẩm và chi tiết bảo hành. Để đảm bảo các nguồn dữ liệu chính xác được truy vấn, bộ định tuyến gửi truy vấn của người dùng đến LLM để phát hiện ý định.
- Dựa trên ý định được phát hiện, công cụ quy tắc của bộ định tuyến xác định nguồn dữ liệu thích hợp để định tuyến yêu cầu đến. Bộ định tuyến sau đó xây dựng một truy vấn cơ sở dữ liệu với các bộ lọc xác định để đảm bảo chỉ dữ liệu liên quan được lấy.
- Bộ định tuyến gửi dữ liệu đã truy xuất đến bộ điều phối.
- Bộ điều phối gọi thành phần xử lý dữ liệu để tổng hợp ngữ cảnh đã truy xuất, tăng cường prompt và thực hiện xác thực guardrail AI có trách nhiệm.
- Sau khi xử lý hoàn tất, bộ xử lý dữ liệu trả về prompt phong phú cho bộ điều phối. Prompt cuối cùng này chứa không chỉ truy vấn ban đầu của người dùng mà còn cả thông tin ngữ cảnh, tri thức đã truy xuất và các cải tiến cấu trúc sẽ hướng dẫn mô hình ngôn ngữ tạo ra phản hồi chính xác và toàn diện hơn.
- Bộ điều phối gửi prompt tăng cường cho LLM để suy luận.
- Phản hồi được tạo ra sau đó được truyền trở lại bộ điều phối. Tại thời điểm này, một bước xác thực guardrail bổ sung có thể được triển khai trước khi phản hồi cuối cùng được giao cho người dùng.
Mẫu mô-đun này phù hợp tốt với các ứng dụng AI yêu cầu xử lý chuyên biệt với độ chính xác cao trên một tập hữu hạn các nhiệm vụ. Nó cung cấp tính linh hoạt đáng kể, cho phép các thành phần riêng lẻ được sửa đổi, cập nhật hoặc thay thế mà không làm gián đoạn hệ thống rộng hơn — một lợi thế quan trọng trong các môi trường AI phát triển nhanh. Tuy nhiên, sự phụ thuộc của mẫu vào một thành phần định tuyến thông minh tạo ra các lỗ hổng tiềm ẩn khi hệ thống mở rộng.
Các khung điều phối AI agentic giải quyết một số hạn chế này bằng cách cho phép các hệ thống điều phối nhiều agent chuyên biệt có thể thực hiện phạm vi nhiệm vụ rộng hơn một cách tự trị hơn. Phần tiếp theo giới thiệu một số mẫu agentic phổ biến và đi qua một ví dụ chi tiết về điều phối agentic.
Các Mẫu Agentic (Agentic Patterns)
Có một số mẫu điều phối phổ biến cho ứng dụng AI agentic. Chúng bao gồm:
Mẫu tuần tự (pipeline)
Các agent chuyên biệt được gọi theo thứ tự cố định, mỗi agent tinh chỉnh hoặc biến đổi dữ liệu trước khi chuyển sang agent tiếp theo. Phù hợp tốt với suy luận đa bước hoặc luồng chuyển đổi dữ liệu.
Mẫu đồng thời (fan-out/fan-in)
Nhiều agent làm việc độc lập và song song trên cùng một đầu vào hoặc vấn đề, và đầu ra của chúng được thu thập và đối chiếu. Thúc đẩy tốc độ và sự đa dạng trong giải quyết vấn đề.
Agent giám sát (supervisor) với các agent chuyên biệt
Một agent giám sát đóng vai trò bộ điều phối, động tổ chức phân công nhiệm vụ cho các agent có khả năng thực hiện chúng tốt nhất, cho phép chuyên môn hóa và khả năng thích ứng.
Mẫu lập kế hoạch/thích ứng (planning/adaptive)
Các agent sử dụng khả năng lập kế hoạch để chia nhỏ các nhiệm vụ phức tạp thành các nhiệm vụ con, được gửi đi để giải quyết song song hoặc tuần tự bởi hệ thống. Mẫu này là nền tảng trong thiết kế agentic và được minh họa bởi các framework như HuggingGPT và AutoGen.
Bầy agent (Swarm of agents)
Các agent phối hợp thông qua bàn giao rõ ràng hoặc các cuộc trò chuyện nhóm cộng tác để hoàn thành quy trình làm việc, đảm bảo ngữ cảnh được bảo tồn và kết quả được tổng hợp hiệu quả.
Với sự phát triển nhanh chóng của các hệ thống agentic, cảnh quan vẫn còn rất năng động, không có một cách tiếp cận nào nổi lên như giải pháp dứt khoát. Để cung cấp một minh họa cụ thể về điều phối trong AI agentic, chúng ta sẽ tập trung vào một mẫu đã đạt được vị trí đặc biệt nổi bật và xuất hiện với tần suất ngày càng tăng trong các triển khai khác nhau.
Agent giám sát với các agent chuyên biệt (Supervisor agent with specialized agents)
Đây là một mẫu điều phối tập trung, nơi một agent giám sát đóng vai trò bộ điều phối quản lý nhiều agent chuyên biệt, mỗi agent xử lý các lĩnh vực cụ thể (ví dụ: phân tích dữ liệu, tạo nội dung, gọi API). Agent giám sát phân chia các nhiệm vụ phức tạp thành các nhiệm vụ con và định tuyến chúng dựa trên khả năng của agent. Sau đó, nó tổng hợp các kết quả, kết hợp đầu ra từ nhiều agent khi cần thiết.
Hiện có rất nhiều framework điều phối, mỗi framework có điểm mạnh và đánh đổi riêng. Như với các mẫu điều phối, điều quan trọng cần lưu ý là không có framework nào vượt trội tuyệt đối; chọn giải pháp phù hợp phụ thuộc vào các yêu cầu và bối cảnh cụ thể của bạn. Tại thời điểm viết sách, các framework phổ biến bao gồm:
Strands Agents
Một framework điều phối mã nguồn mở theo hướng mô hình (model-driven) cho phép phát triển các hệ thống AI đơn và đa agent. Nó hỗ trợ các kiến trúc agent linh hoạt (từ phân cấp supervisor-specialist đến agent graph và "swarm" ngang hàng) và cung cấp tích hợp AWS mạnh mẽ cùng khả năng quan sát tích hợp. Được thiết kế để triển khai doanh nghiệp nhanh, Strands Agents đơn giản hóa việc kết hợp và điều phối các agent với code tối giản, trở thành lựa chọn hàng đầu cho các quy trình làm việc agent cấp sản xuất, có khả năng mở rộng cao.
LangGraph
Một framework dựa trên đồ thị (graph-based) để điều phối chi tiết nhiều agent, hỗ trợ các quy trình làm việc phức tạp với điều phối đa agent rõ ràng. LangGraph được thiết kế cho người dùng nâng cao; có đường cong học tập khá dốc nhưng cung cấp tính linh hoạt đáng kể để xây dựng các pipeline tùy chỉnh và quy trình làm việc RAG.
CrewAI
Cung cấp sự trừu tượng hóa cấp cao dựa trên vai trò, đơn giản hóa việc tổ chức các agent thành các nhóm cộng tác. Được thiết kế để tạo mẫu nhanh và hợp tác giữa người và AI cũng như đa agent, phù hợp tốt cho các dự án đa agent giai đoạn đầu.
OpenAI Swarm
Một framework thử nghiệm, nhẹ, tập trung vào điều phối agent dựa trên thói quen và bàn giao agent sang agent. Mặc dù chưa được dùng trong sản xuất, nhưng nó rất có thể tùy chỉnh và hữu ích cho thử nghiệm, học tập và phát triển giai đoạn đầu.
AutoGen
Một framework thích ứng, mã nguồn mở hỗ trợ cộng tác không đồng bộ giữa các agent giao tiếp qua truyền thông điệp. Phổ biến cho nghiên cứu và tạo mẫu, nơi hành vi của agent cần được tinh chỉnh lặp đi lặp lại.
Ví dụ trường hợp sử dụng và triển khai: hỗ trợ khách hàng thương mại điện tử
Ví dụ của chúng ta minh họa một hệ thống hỗ trợ khách hàng đa agent được xây dựng trên framework Strands Agents, thể hiện định tuyến yêu cầu thông minh thông qua kiến trúc hub-and-spoke (trung tâm-và-nhánh) đơn giản hóa.
Agent giám sát Strands đóng vai trò là bộ điều phối của hệ thống và định tuyến yêu cầu đến một trong bốn agent chuyên biệt:
- Một agent hỗ trợ kỹ thuật xử lý các vấn đề đăng nhập, đặt lại mật khẩu và khắc phục sự cố kỹ thuật
- Một agent thanh toán quản lý refund, tranh chấp hóa đơn và câu hỏi về hóa đơn
- Một agent thông tin sản phẩm cung cấp thông tin chi tiết và khuyến nghị sản phẩm
- Một agent trạng thái đơn hàng theo dõi lô hàng và thông tin giao hàng
Hình 4-8 minh họa kiến trúc này.
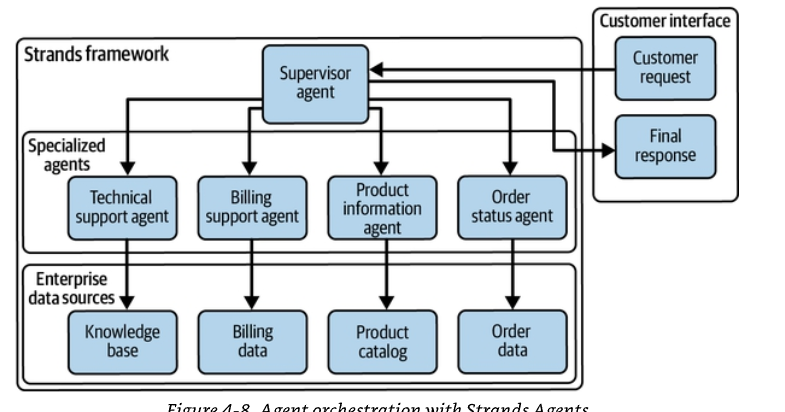
Tất cả yêu cầu của khách hàng đều chạy qua supervisor/orchestrator trung tâm, xác định agent chuyên biệt phù hợp để xử lý từng yêu cầu. Mỗi agent chuyên biệt được trang bị dữ liệu cụ thể về lĩnh vực của nó.
Logic định tuyến sử dụng LLM call để thực hiện phân loại yêu cầu ban đầu. Ví dụ: các yêu cầu có "login" hoặc "password" được định tuyến đến agent hỗ trợ kỹ thuật; các yêu cầu có "refund" hoặc "charge" được định tuyến đến agent thanh toán. Để rõ ràng hơn, các cách tiếp cận nâng cao có thể tận dụng hiểu ngôn ngữ tự nhiên và các mô hình có khả năng suy luận để xác định ý định và chọn công cụ phù hợp mà không cần so khớp từ khóa rõ ràng.
Tất cả các agent đều kế thừa từ lớp Strands Agent cơ sở, tận dụng các khả năng tích hợp của framework để quản lý công cụ và luồng thực thi. Các công cụ dữ liệu doanh nghiệp trả về các phản hồi được xác định trước dựa trên các loại yêu cầu được phát hiện, chẳng hạn như:
- Vấn đề kỹ thuật: "Hãy thử xóa bộ nhớ đệm và cookie trình duyệt của bạn."
- Truy vấn thanh toán: "Khoản hoàn tiền của bạn sẽ xuất hiện trong ba đến năm ngày làm việc."
- Thông tin sản phẩm: "Laptop cao cấp với Intel i7, 16GB RAM - $1,299."
Hệ thống cũng bao gồm xử lý lỗi cho các lỗi định tuyến, lỗi thực thi công cụ và đầu vào không hợp lệ, ghi lỗi và cho phép khôi phục một cách thuận tiện trong quá trình hoạt động.
Code triển khai đầy đủ và tài liệu bổ sung có sẵn trong kho GitHub đồng hành của sách. Code được cung cấp bao gồm các unit test toàn diện cho các phản hồi agent riêng lẻ và integration test xác thực luồng request-to-response hoàn chỉnh. Các kịch bản test bao phủ bốn danh mục hỗ trợ chính với xác thực hành vi và phản hồi mong đợi.
Thiết kế này thể hiện khái niệm cốt lõi của điều phối agent thông minh trong khi duy trì sự đơn giản để tạo mẫu và thử nghiệm nhanh. Framework Strands Agents cung cấp nền tảng vững chắc để mở rộng hệ thống hướng đến triển khai sẵn sàng sản xuất.
Tóm Tắt (Summary)
Chương này đã đề cập đến các trụ cột thiết yếu để triển khai các ứng dụng AI tạo sinh một cách có trách nhiệm và hiệu quả. Chúng ta đã khám phá cách quản trị dữ liệu AI mở rộng các khung truyền thống để bao gồm dữ liệu phi cấu trúc, xem xét vai trò quan trọng của quản lý dữ liệu (data stewardship) và quản lý siêu dữ liệu trong việc làm cho dữ liệu có thể truy cập được đối với cả con người lẫn các agent AI, và thiết lập các tiêu chuẩn chất lượng dữ liệu cho dữ liệu phi cấu trúc. Sau đó chúng ta đã xem xét các nguyên tắc AI có trách nhiệm — công bằng, minh bạch, trách nhiệm giải trình, quyền riêng tư, độ tin cậy và giám sát của con người — với hướng dẫn triển khai thực tế trên các nền tảng đám mây chính. Chương kết thúc bằng việc thảo luận về các mẫu điều phối LLMOps, tiến triển từ các pipeline RAG tuyến tính qua kiến trúc đồng thời mô-đun đến các hệ thống đa agent sử dụng các framework như Strands Agents. Cùng nhau, các thực hành này tạo thành nền tảng cho các hệ thống AI không chỉ mạnh mẽ mà còn an toàn, tuân thủ và đáng tin cậy.
Chương 5. Cơ Sở Tri Thức và Cơ Sở Dữ Liệu Vector (Knowledge Bases and Vector Databases)
Trong bối cảnh doanh nghiệp ngày nay được dẫn dắt bởi AI, khả năng neo đậu (ground) các ứng dụng AI tạo sinh vào kiến thức tổ chức chính xác, cập nhật đã trở thành lợi thế cạnh tranh không thể thiếu. Chương này khám phá các nền tảng chiến lược dữ liệu cho phép các tổ chức xây dựng các hệ thống GenAI và agentic AI sẵn sàng sản xuất thông qua ba trụ cột quan trọng: cơ sở tri thức (knowledge bases), tạo sinh tăng cường truy xuất (retrieval-augmented generation — RAG) và cơ sở dữ liệu vector (vector databases).
Thách Thức Dữ Liệu GenAI (The GenAI Data Challenge)
Các mô hình ngôn ngữ lớn truyền thống, dù mạnh mẽ, vẫn đối mặt với những giới hạn cơ bản khi được triển khai trong môi trường doanh nghiệp. Chúng hoạt động với dữ liệu huấn luyện tĩnh, thường đã lỗi thời nhiều tháng, và thiếu quyền truy cập vào kiến thức độc quyền của tổ chức. Điều này tạo ra khoảng cách nghiêm trọng giữa khả năng AI và nhu cầu kinh doanh — khoảng cách khiến các tổ chức tốn kém cả về độ chính xác lẫn lợi thế cạnh tranh.
Dữ liệu phi cấu trúc (unstructured data) được ước tính chiếm 80-90% thông tin doanh nghiệp, với khối lượng dữ liệu tăng khoảng 55-65% mỗi năm. Tuy nhiên hầu hết các tổ chức vẫn vật lộn để tận dụng dữ liệu này một cách hiệu quả vì họ thiếu cơ sở hạ tầng kỹ thuật cần thiết để truy cập, tích hợp và sử dụng dữ liệu phi cấu trúc theo những cách đáng tin cậy. Do đó, thị trường cơ sở dữ liệu vector đang mở rộng nhanh chóng: các dự báo cho thấy nó sẽ tăng từ 2,55 tỷ đô la vào năm 2025 lên hơn 15 tỷ đô la vào năm 2035, phản ánh nhu cầu ngày càng tăng về cơ sở hạ tầng có khả năng quản lý và truy xuất dữ liệu này ở quy mô lớn.
Chương này tập trung vào ba công nghệ liên kết nhau tạo thành xương sống của các ứng dụng GenAI hiện đại: các cơ sở tri thức tổ chức và đồng bộ hóa dữ liệu doanh nghiệp; các cơ sở dữ liệu vector lưu trữ và lập chỉ mục dữ liệu đó dưới dạng nhúng (embeddings) nhiều chiều; và RAG là mẫu kiến trúc kết nối chúng với nhau, định tuyến các truy vấn qua các cơ sở tri thức, truy xuất ngữ cảnh liên quan về mặt ngữ nghĩa từ các chỉ mục vector và neo đậu phản hồi của LLM vào thông tin thực tế, cập nhật.
Cơ Sở Tri Thức: Tổ Chức và Lưu Trữ Dữ Liệu (Knowledge Bases: Data Organization and Storage)
Các cơ sở tri thức đã phát triển qua nhiều thập kỷ từ các kho lưu trữ tĩnh thành các hệ thống động, thông minh đóng vai trò là lớp điều phối (orchestration layer) cho việc truy xuất AI doanh nghiệp. Về cốt lõi, một cơ sở tri thức hoạt động như giao diện tới một hoặc nhiều cơ sở dữ liệu vector hoặc chỉ mục truy xuất khác, quản lý cách dữ liệu tổ chức được đưa vào, chuyển đổi và làm cho có thể tìm kiếm được trong suốt vòng đời của nó.
Một cơ sở tri thức không chỉ đơn giản là lưu trữ dữ liệu; nó điều phối đồng bộ hóa định kỳ các nguồn dữ liệu doanh nghiệp — tài liệu, cơ sở dữ liệu, API và các kho lưu trữ khác — vào các cơ sở dữ liệu vector bên dưới, đảm bảo các embedding luôn cập nhật khi nội dung nguồn thay đổi. Nó truy vấn cơ sở tri thức, và cơ sở tri thức này lần lượt tìm kiếm qua các chỉ mục cơ sở dữ liệu vector được kết nối và truy xuất thông tin liên quan về mặt ngữ cảnh. Cùng nhau, cơ sở tri thức, cơ sở dữ liệu vector và RAG không phải là các công nghệ độc lập mà là các thành phần tích hợp chặt chẽ của một kiến trúc truy xuất duy nhất, nơi cơ sở tri thức đóng vai trò là điểm vào.
Cơ Sở Dữ Liệu Vector: Lưu Trữ và Lập Chỉ Mục Dữ Liệu (Vector Databases: Data Storage and Indexing)
Cơ sở dữ liệu vector lưu trữ các embedding vector nhiều chiều đại diện cho văn bản, hình ảnh và các loại nội dung khác, được tối ưu hóa cho tìm kiếm tương tự (similarity search) thay vì dựa vào các truy vấn khớp chính xác. Các giải pháp hàng đầu như Pinecone, Weaviate, Chroma và NVIDIA đã phát triển từ công nghệ ngách thành cơ sở hạ tầng AI doanh nghiệp quan trọng, vì các embedding này cho phép tìm kiếm ngữ nghĩa tìm nội dung liên quan về mặt ý nghĩa hơn là các từ khóa chính xác.
Tạo Sinh Tăng Cường Truy Xuất: Truy Xuất Dữ Liệu và Lắp Ráp Ngữ Cảnh (Retrieval-Augmented Generation: Data Retrieval and Context Assembly)
Quá trình RAG cốt lõi bao gồm nhận truy vấn của người dùng, truy xuất thông tin liên quan từ các cơ sở dữ liệu vector, và sử dụng nội dung đã truy xuất đó để tạo phản hồi chính xác. RAG đã trở nên thiết yếu trong các ứng dụng GenAI ngày nay vì nó làm giảm đáng kể ảo giác (hallucinations) trong khi cung cấp thông tin cập nhật.
Tại Sao Những Công Nghệ Này Thiết Yếu (Why These Technologies Are Essential)
Quan trọng nhất, hệ thống RAG cải thiện độ chính xác và độ tin cậy bằng cách neo đậu các phản hồi vào thông tin có thể xác minh, cập nhật. Ngoài độ chính xác được cải thiện, các công nghệ này cho phép tính liên quan theo thời gian thực mà các mô hình tĩnh không thể đạt được. Các cơ sở tri thức có thể được cập nhật liên tục, cho phép các ứng dụng GenAI truy cập thông tin hiện tại vượt xa ngày cắt (cutoff) huấn luyện vốn có của mô hình ngôn ngữ lớn. Khả năng này được chứng minh là thiết yếu đối với các bối cảnh doanh nghiệp nơi thông tin thay đổi nhanh chóng và các quyết định phụ thuộc vào dữ liệu có sẵn mới nhất.
Lý lẽ kinh tế về cách tiếp cận kiến trúc này cũng không kém phần thuyết phục. Bằng cách truy xuất thông tin từ các nguồn bên ngoài thay vì mã hóa hoàn toàn vào các tham số mô hình, các tổ chức đạt được việc sử dụng tài nguyên tính toán hiệu quả hơn. Chiến lược truy xuất dựa trên truy xuất này làm giảm nhu cầu đào tạo lại mô hình thường xuyên và tốn kém trong khi vẫn duy trì quyền truy cập vào các cơ sở tri thức ngày càng mở rộng. Cuối cùng, các cơ sở dữ liệu vector cung cấp khả năng mở rộng mà các triển khai doanh nghiệp đòi hỏi, xử lý tìm kiếm tương tự trên hàng tỷ vector trong khi hỗ trợ các ứng dụng từ trả lời câu hỏi đơn giản đến các nhiệm vụ suy luận đa bước phức tạp.
Nền Tảng Cơ Sở Tri Thức: Từ Dữ Liệu Đến Tri Thức (Knowledge Base Fundamentals: From Data to Knowledge)
Với tầm quan trọng chiến lược của cơ sở tri thức đã được xác lập, chúng ta giờ đây chuyển sang câu hỏi thực tiễn: Làm thế nào để các tổ chức chuyển đổi dữ liệu doanh nghiệp thô thành tri thức có cấu trúc, sẵn sàng cho AI?
Kiến Trúc Dữ Liệu cho Cơ Sở Tri Thức (Data Architecture for Knowledge Bases)
Nhìn nhận cơ sở tri thức qua lăng kính kiến trúc dữ liệu cho thấy các quyết định cơ sở hạ tầng quan trọng quyết định liệu hệ thống có thể mở rộng, duy trì chất lượng và cung cấp phản hồi đáng tin cậy hay không.
Các thành phần cơ sở tri thức qua lăng kính dữ liệu (Knowledge base components through a data lens)
Các cơ sở tri thức hiện đại cho ứng dụng GenAI được xây dựng trên kiến trúc lớp ngữ nghĩa được giới thiệu trong Chương 3, bao gồm năm lớp dần chuyển đổi dữ liệu doanh nghiệp thô thành tri thức sẵn sàng cho AI. Mỗi lớp xây dựng trên lớp trước trong khi duy trì sự phân tách rõ ràng các mối quan tâm, cho phép triển khai theo gia số.
Nền tảng dữ liệu (Data foundation)
Lớp nền tảng thiết lập cơ sở hạ tầng cơ bản hỗ trợ các hoạt động cơ sở tri thức ở quy mô doanh nghiệp. Điều này bao gồm các pipeline nhập dữ liệu thu thập thông tin từ tài liệu, cơ sở dữ liệu, API và luồng thời gian thực, cùng với cơ sở hạ tầng lưu trữ kết hợp khả năng mở rộng của data lake với quản trị kho dữ liệu. Lớp này phải hỗ trợ cả nguồn dữ liệu có cấu trúc và phi cấu trúc trong khi triển khai kiểm soát bảo mật và quyền truy cập toàn diện ngay từ đầu.
Quản lý siêu dữ liệu và bản thể học (Metadata and ontology management)
Lớp siêu dữ liệu và bản thể học biến đổi các mô tả dữ liệu kỹ thuật thành các định nghĩa ngữ nghĩa có ý nghĩa nghiệp vụ mà các hệ thống GenAI có thể hiểu và truy vấn. Quản lý bản thể học kết nối các cấu trúc dữ liệu kỹ thuật với ý nghĩa nghiệp vụ, cho phép các thuộc tính kỹ thuật được hiểu theo tỷ lệ.
Tuy nhiên, quản lý bản thể học trong bối cảnh cơ sở tri thức GenAI đòi hỏi nhiều hơn là các phân loại tĩnh hoặc các lược đồ siêu dữ liệu phẳng. Sự xuất hiện của các kiến trúc GraphRAG phản ánh nhận thức ngày càng tăng rằng tìm kiếm tương tự vector và duyệt đồ thị là các cách tiếp cận bổ sung cho nhau. Một hệ thống kết hợp duy trì các chỉ mục vector cho tìm kiếm ngữ nghĩa và các cấu trúc đồ thị cho truy xuất nhận thức mối quan hệ. Khi một người dùng hỏi câu hỏi như "Tất cả các yêu cầu tuân thủ nào được đề cập trong các chính sách liên quan đến một khu vực cụ thể?", hệ thống kết hợp có thể đồng thời tìm kiếm các tài liệu liên quan về mặt ngữ nghĩa trong khi duyệt qua các mối quan hệ giữa các thực thể.
Đối với các tổ chức xây dựng cơ sở hạ tầng dữ liệu sẵn sàng cho AI, đầu tư vào quản lý bản thể học dựa trên đồ thị mang lại lợi nhuận kép. Mỗi nguồn dữ liệu mới được tích hợp vào đồ thị tri thức làm giàu ngữ cảnh quan hệ có sẵn cho mọi nút hiện có, khiến việc truy xuất ngày càng chính xác và đầy đủ về mặt ngữ cảnh hơn. Các bản thể học chuyên ngành được xây dựng bằng các tiêu chuẩn như OWL hoặc RDF, như đã thảo luận trong Chương 2, đảm bảo khả năng tương tác giữa các hệ thống trong khi nắm bắt các quy tắc nghiệp vụ, cấu trúc phân cấp và các mối quan hệ kết hợp mà hệ thống AI cần để suy luận.
Pipeline chuyển đổi và làm giàu dữ liệu (Transformation and enrichment pipeline)
Lớp chuyển đổi xử lý quá trình phức tạp cần thiết để chuyển đổi dữ liệu thô thành các định dạng giàu ngữ nghĩa được tối ưu hóa cho tiêu thụ GenAI. Xử lý tài liệu trích xuất cấu trúc và ý nghĩa từ nội dung phi cấu trúc như PDF, email và hình ảnh. Làm sạch dữ liệu giải quyết sự không nhất quán và chuẩn hóa định dạng, trong khi nhận dạng thực thể và trích xuất mối quan hệ khám phá các yếu tố ngữ nghĩa và kết nối trong nội dung. Xác thực chất lượng ở mỗi giai đoạn xử lý đảm bảo rằng các quy trình chuyển đổi duy trì tính toàn vẹn ngữ nghĩa cần thiết cho suy luận AI đáng tin cậy.
Cơ sở hạ tầng vector hóa và lập chỉ mục (Vectorization and indexing infrastructure)
Lớp vector hóa chuyển đổi dữ liệu được làm giàu về mặt ngữ nghĩa thành các embedding vector cho phép tìm kiếm dựa trên tương tự — nền tảng của hệ thống RAG. Các mô hình embedding chuyển đổi văn bản, hình ảnh và nội dung khác thành các biểu diễn vector nhiều chiều, sau đó được lưu trữ trong các cơ sở dữ liệu vector như Pinecone, Weaviate, Milvus hoặc Chroma. Các cơ sở dữ liệu này cho phép tìm kiếm tương tự tìm nội dung liên quan về mặt ngữ nghĩa dựa trên ý nghĩa hơn là từ khóa chính xác. Cấu hình lập chỉ mục phù hợp mang lại hiệu suất truy vấn dưới một giây trong khi hỗ trợ hàng tỷ embedding.
API và suy luận (APIs and reasoning)
Lớp cuối cùng cung cấp các giao diện và khả năng điều phối mà các ứng dụng GenAI sử dụng để truy cập tri thức. Knowledge API cung cấp quyền truy cập theo chương trình vào thông tin ngữ nghĩa, trong khi giao diện truy vấn hỗ trợ các truy vấn ngôn ngữ tự nhiên và lọc theo ngữ cảnh. Quản lý ngữ cảnh duy trì trạng thái qua các tương tác nhiều lượt, và điều phối truy xuất phối hợp các mẫu truy cập thông tin phức tạp cho các quy trình làm việc RAG. Lớp này trừu tượng hóa sự phức tạp của truy cập dữ liệu ngữ nghĩa trong khi cung cấp thông tin ngữ cảnh phong phú mà LLM cần để đưa ra phản hồi có căn cứ.
Quản trị: Nhúng xuyên suốt (Governance: Embedded throughout)
Thay vì tồn tại như một lớp riêng biệt, quản trị dữ liệu được nhúng vào như một nguyên tắc nền tảng xuyên suốt cả năm lớp. Kiểm soát chất lượng xác thực dữ liệu ở mỗi giai đoạn xử lý, các giao thức bảo mật thực thi kiểm soát quyền truy cập trên tất cả các lớp, các khung tuân thủ đảm bảo các yêu cầu quy định được đáp ứng từ nhập đến truy xuất, và theo dõi dòng dữ liệu (lineage tracking) duy trì các nhật ký kiểm toán từ dữ liệu nguồn đến đầu ra do AI tạo ra. Cách tiếp cận tích hợp này đảm bảo rằng quản trị tăng cường thay vì cản trở các hoạt động cơ sở tri thức, cho phép các tổ chức triển khai ứng dụng GenAI một cách tự tin ở quy mô doanh nghiệp.
Tiến Hóa từ Cơ Sở Tri Thức Truyền Thống sang GenAI (Evolution from Traditional to GenAI Knowledge Bases)
Các cơ sở tri thức truyền thống được thiết kế cho thế giới của các truy vấn có cấu trúc và các mối quan hệ rõ ràng. Tuy nhiên, các ứng dụng GenAI đòi hỏi các hệ thống linh hoạt, nhận thức ngữ nghĩa có thể tìm thấy thông tin liên quan dựa trên ý nghĩa hơn là khớp chính xác. Sự tiến hóa này đại diện cho sự thay đổi cơ bản trong cách các tổ chức quản lý và tận dụng tài sản dữ liệu của họ. Các hệ thống truyền thống dựa vào các cách tiếp cận dựa trên quy tắc và khẳng định logic, đòi hỏi cập nhật thủ công và khó xử lý sự phức tạp của ngôn ngữ tự nhiên. Ngược lại, các cơ sở tri thức GenAI hiện đại tận dụng các embedding vector trong không gian nhiều chiều để biểu diễn các mối quan hệ ngữ nghĩa, cho phép truy xuất dựa trên tương tự thay vì khớp chính xác.
Bảng 5-1. Sự khác biệt chính giữa cơ sở tri thức truyền thống và GenAI
| Khía cạnh | Truyền thống | GenAI-enabled | Tác động dữ liệu |
|---|---|---|---|
| Cấu trúc dữ liệu | Lược đồ cứng nhắc | Linh hoạt, ngữ nghĩa | Cho phép xử lý các loại dữ liệu đa dạng |
| Truy cập dữ liệu | Khớp từ khóa chính xác | Tương tự ngữ nghĩa | Cho phép khám phá khái niệm dữ liệu liên quan |
| Cập nhật dữ liệu | Thủ công, định kỳ | Tự động, liên tục | Duy trì độ tươi dữ liệu thời gian thực |
| Mối quan hệ dữ liệu | Chỉ liên kết rõ ràng | Suy luận từ ngữ nghĩa | Hỗ trợ khám phá các kết nối dữ liệu ẩn |
| Quy mô dữ liệu | Bị giới hạn bởi cấu trúc | Hàng tỷ vector | Cho phép mở rộng lên khối lượng dữ liệu doanh nghiệp |
Ví dụ thực tế: JPMorgan Chase là một ví dụ điển hình về chiến lược GenAI ưu tiên dữ liệu, với "trọng tâm sâu vào sản phẩm dữ liệu" cho phép khả năng AI trên toàn công ty. Cách tiếp cận của tổ chức bao gồm áp dụng sớm với các trường hợp sử dụng văn phòng hậu kỳ, đo lường ROI nghiêm ngặt và chuẩn bị cơ sở hạ tầng dữ liệu để tích hợp AI ở quy mô doanh nghiệp. Một khía cạnh quan trọng liên quan đến chuẩn bị dữ liệu cho hệ thống AI thông qua tích hợp cả nguồn dữ liệu phi cấu trúc và có cấu trúc. Như Katie Hainsey, giám đốc điều hành và trưởng bộ phận AI/ML và dữ liệu tại JPMorgan Chase, đã giải thích: "Đó là điều sẽ giúp chúng tôi sẵn sàng cho tương lai, để kích hoạt các công cụ và khả năng này. Theo quan điểm của tôi, đó là về, làm thế nào để chúng tôi làm cho dữ liệu sẵn sàng cho AI?"
Pipeline Chuẩn Bị Dữ Liệu cho Cơ Sở Tri Thức (Data Preparation Pipeline for Knowledge Bases)
Chuyển đổi dữ liệu doanh nghiệp thô thành tri thức sẵn sàng cho AI đòi hỏi một cách tiếp cận có hệ thống cân bằng giữa độ triệt để và hiệu quả. Pipeline chuẩn bị dữ liệu là yếu tố quan trọng nhất trong sự thành công của hệ thống RAG, với nghiên cứu liên tục cho thấy rằng các cải tiến về xử lý dữ liệu mang lại lợi nhuận cao hơn đáng kể so với đầu tư vào sự tinh vi của mô hình.
Các tổ chức phải triển khai các pipeline tiền xử lý mạnh mẽ để đảm bảo chất lượng dữ liệu trước khi tích hợp vào cơ sở tri thức. Các bước tiền xử lý chính bao gồm làm sạch dữ liệu để sửa trùng lặp, lỗi và giá trị thiếu; chuyển đổi dữ liệu để đảm bảo tính nhất quán trên các định dạng như JSON, XML hoặc CSV; và xác thực dữ liệu thông qua xác thực lược đồ, kiểm tra ràng buộc và phát hiện bất thường.
Chuyển Đổi Dữ Liệu Bảy Giai Đoạn (Seven-Stage Data Transformation)
Hành trình từ dữ liệu thô đến tri thức có thể truy xuất được tuân theo bảy giai đoạn riêng biệt, mỗi giai đoạn có các hoạt động cụ thể, tác động chất lượng và công cụ được khuyến nghị. Bảng 5-2 phác thảo các giai đoạn này và tác động tương đối của chúng đối với hiệu suất tổng thể của hệ thống, với chiến lược phân đoạn (chunking) và cải tiến làm sạch dữ liệu mỗi loại mang lại đến 35% độ chính xác truy xuất tốt hơn.
Bảng 5-2. Các giai đoạn pipeline chuyển đổi dữ liệu và tác động chất lượng
| Giai đoạn | Thao tác dữ liệu | Tác động chất lượng | Công cụ/kỹ thuật |
|---|---|---|---|
| 1. Chọn lọc dữ liệu | Đánh giá nguồn, lọc liên quan | Cao — nguyên tắc GIGO (garbage in, garbage out) | Data catalog, kiểm tra nguồn |
| 2. Làm sạch dữ liệu | Loại trùng, sửa lỗi, chuẩn hóa | Nghiêm trọng — tác động 35% hiệu suất | Công cụ chất lượng dữ liệu, pandas |
| 3. Làm giàu dữ liệu | Gán thẻ siêu dữ liệu, trích xuất thực thể, phân loại | Cao — tăng đến 21% độ chính xác truy xuất; độ chính xác cải thiện từ 73% lên 83% khi kết hợp chunking giàu siêu dữ liệu với kỹ thuật embedding được tối ưu hóa | Phân loại LLM, NLP pipeline, mô hình trích xuất thực thể |
| 4. Lọc dữ liệu | Loại bỏ nhiễu, loại bỏ nội dung giá trị thấp | Trung bình — giảm nhiễu truy xuất | Quy tắc tùy chỉnh, bộ lọc ML |
| 5. Phân đoạn dữ liệu | Phân mảnh ngữ nghĩa, bảo toàn ngữ cảnh | Nghiêm trọng — tác động hiệu suất 35% | Semantic chunking, LLMs |
| 6. Nhúng dữ liệu | Tạo biểu diễn vector | Cao — tác động hiệu suất 27% | Mô hình embedding |
| 7. Tự động hóa dữ liệu | Làm mới liên tục, giám sát, cập nhật | Nghiêm trọng — duy trì độ tươi | Dịch vụ đồng bộ knowledge base, Airflow, pipeline hướng sự kiện |
Ví dụ thực tế: Hệ thống Telco-RAG cho thấy chuẩn bị dữ liệu nâng cao cho các miền kỹ thuật, triển khai xử lý nâng cao bằng thuật ngữ chuyên ngành (glossary-enhanced processing) để xử lý thuật ngữ viễn thông và các thuật ngữ kỹ thuật. Hệ thống sử dụng tăng cường truy vấn với bổ sung thuật ngữ chuyên ngành, định tuyến mạng thần kinh để lọc tài liệu liên quan, và các prompt nâng cao kết hợp thuật ngữ chuyên ngành để tạo phản hồi LLM cải tiến. Nó giải quyết các thách thức chuyên ngành bằng cách tích hợp các thuật ngữ chuyên ngành vào các bước nhúng và nâng cao truy vấn, tinh chỉnh các mô hình nhúng trên dữ liệu ngành, và sử dụng các phương pháp tìm kiếm lai kết hợp tương tự vector với khớp từ khóa để truy xuất nội dung kỹ thuật chính xác. Cách tiếp cận toàn diện đối với chuẩn bị dữ liệu này đảm bảo rằng các cơ sở tri thức có thể hỗ trợ hiệu quả các ứng dụng GenAI trên các lĩnh vực đa dạng.
Các Loại Dữ Liệu và Chiến Lược Quản Lý (Data Types and Management Strategies)
Các cơ sở tri thức hiệu quả phải đáp ứng đầy đủ phổ dữ liệu doanh nghiệp, từ tài liệu phi cấu trúc và đa phương tiện đến các cơ sở dữ liệu có cấu trúc chính xác và mọi thứ ở giữa. Mỗi loại dữ liệu đặt ra những thách thức riêng biệt cho việc lưu trữ, xử lý và truy xuất. Ngày càng nhiều, các ứng dụng GenAI mạnh mẽ nhất kết hợp nhiều loại dữ liệu thông qua các chiến lược lai tận dụng điểm mạnh độc đáo của mỗi loại.
Dữ Liệu Phi Cấu Trúc: Thách Thức 80–90% (Unstructured Data: The 80–90% Challenge)
Phần lớn dữ liệu doanh nghiệp ngày nay là phi cấu trúc, và khối lượng dữ liệu đang tăng trưởng với tốc độ chưa từng có. Do đó, dữ liệu phi cấu trúc đại diện cho thách thức chủ đạo trong các triển khai AI doanh nghiệp. Phần lớn dữ liệu này — email, PDF, hình ảnh, tệp âm thanh và video — vẫn bị mắc kẹt trong các hệ thống lưu trữ đang hoạt động. Như Salesforce đã nhận xét, dữ liệu như vậy "có thể có giá trị cao, cung cấp cho doanh nghiệp thông tin AI chính xác và toàn diện hơn vì chúng bắt nguồn từ các tương tác của khách hàng."
Pipeline xử lý được mô tả trong Hình 5-1 chuyển đổi dữ liệu phi cấu trúc thô qua năm giai đoạn có hệ thống. Trích xuất dữ liệu phân tích cú pháp các tệp nguồn như PDF, tài liệu Word, hình ảnh, âm thanh và email bằng các công cụ như Tesseract, PyPDF và Whisper. Chuẩn hóa dữ liệu chuẩn hóa các định dạng, khắc phục các vấn đề mã hóa và căn chỉnh các lược đồ để tạo ra văn bản UTF-8 sạch có cấu trúc nhất quán. Làm giàu dữ liệu áp dụng nhận dạng thực thể, gán thẻ siêu dữ liệu và phân loại chủ đề để thêm ngữ cảnh ngữ nghĩa. Cuối cùng, vector hóa dữ liệu tạo ra các embedding ngữ nghĩa trong 768–1.536 chiều và xây dựng các chỉ mục để tìm kiếm tương tự hiệu quả.
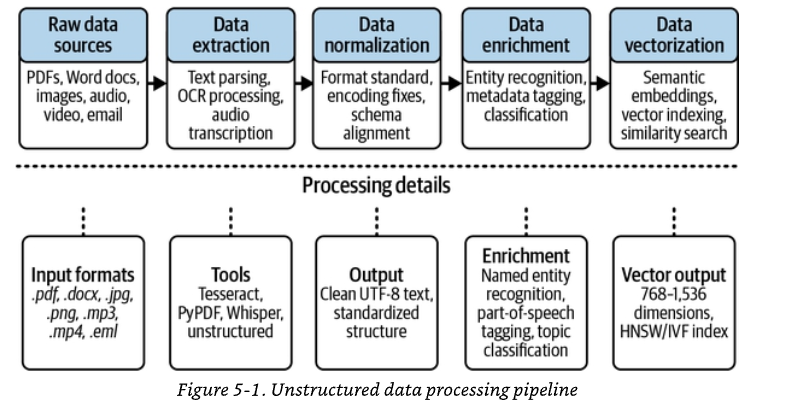
Mỗi danh mục dữ liệu phi cấu trúc đặt ra những thách thức chất lượng riêng biệt mà các tổ chức phải giải quyết trong quá trình chuẩn bị dữ liệu. Dữ liệu văn bản thường chứa sự không nhất quán, giá trị thiếu và thông tin dư thừa. Dữ liệu hình ảnh có những phức tạp riêng với khó khăn bảo toàn cấu trúc, vấn đề duy trì mối quan hệ và các vấn đề độ chính xác OCR có thể ảnh hưởng đến tính toàn vẹn của thông tin cơ bản.
Chiến lược xử lý dữ liệu phi cấu trúc
Các tổ chức thường sử dụng ba chiến lược chính để quản lý dữ liệu phi cấu trúc hiệu quả. Semantic chunking (phân đoạn ngữ nghĩa) bảo toàn ý nghĩa qua các đoạn dữ liệu bằng cách duy trì ranh giới thông tin có ý nghĩa thay vì phân chia tùy tiện, tạo ra các đoạn dựa trên tính gắn kết chủ đề và tác động đáng kể đến hiệu suất truy xuất. Multimodal alignment (căn chỉnh đa phương thức) liên kết các mô tả văn bản với hình ảnh và bảng thông qua các embedding hợp nhất tạo ra các không gian embedding chung nơi các phương thức khác nhau có thể được biểu diễn và so sánh. Metadata enrichment (làm giàu siêu dữ liệu) thêm ngữ cảnh có thể tìm kiếm vào dữ liệu thô thông qua gán thẻ dựa trên người dùng bởi các chuyên gia miền, lập chỉ mục nội dung dựa trên AI để phân loại tự động và các chú thích nâng cao cải thiện khả năng tìm kiếm trên toàn cơ sở tri thức.
Dữ Liệu Có Cấu Trúc: Độ Chính Xác và Mối Quan Hệ (Structured Data: Precision and Relationships)
Trong khi dữ liệu phi cấu trúc chiếm ưu thế về khối lượng doanh nghiệp, dữ liệu có cấu trúc cung cấp nền tảng truy vấn chính xác cho phép truy xuất xác định luận (deterministic retrieval) và mô hình mối quan hệ phức tạp trong hệ thống cơ sở tri thức. Nó hỗ trợ các mẫu truy cập xác định luận và các truy vấn phân tích phức tạp thiết yếu cho thông minh nghiệp vụ và hệ thống hoạt động. Các mối quan hệ rõ ràng, cùng với các lược đồ và ràng buộc được xác định rõ ràng, cho phép xác thực và đảm bảo chất lượng dễ dàng hơn.
Tuy nhiên, tích hợp dữ liệu có cấu trúc từ nhiều nguồn đặt ra nhiều thách thức kỹ thuật mà các tổ chức phải giải quyết để tạo ra các cơ sở tri thức thống nhất, có thể truy vấn. Bảng 5-3 tóm tắt các thách thức tích hợp chính, nguyên nhân gốc rễ và các phương pháp giải quyết đã được chứng minh.
Bảng 5-3. Thách thức tích hợp dữ liệu có cấu trúc và giải pháp
| Thách thức | Mô tả | Phương pháp giải quyết | Tác động dữ liệu |
|---|---|---|---|
| Dị thể lược đồ (Schema heterogeneity) | Cấu trúc dữ liệu khác nhau giữa các nguồn | Ánh xạ lược đồ (cú pháp + ngữ nghĩa) | Cho phép các truy vấn thống nhất |
| Trùng lặp thực thể (Entity duplication) | Cùng thực thể được biểu diễn khác nhau | Phân giải thực thể (xác suất, ML) | Tạo ra một nguồn chân lý duy nhất |
| Xung đột kiểu dữ liệu | Định dạng, đơn vị, mã hóa không tương thích | Chuẩn hóa, tiêu chuẩn hóa | Đảm bảo tính nhất quán |
| Bảo toàn quan hệ (Relationship preservation) | Duy trì kết nối giữa các dữ liệu | Knowledge graph, foreign key | Cho phép suy luận phức tạp |
Ánh xạ lược đồ (schema mapping) giải quyết tính dị thể ngữ nghĩa bằng cách dịch các thực thể từ không gian ngữ nghĩa này sang không gian khác. Phân giải thực thể (entity resolution) xác định và liên kết các bản ghi đề cập đến cùng một thực thể thực tế trên các nguồn dữ liệu khác nhau, tạo ra các chế độ xem hợp nhất thiết yếu cho cơ sở tri thức.
Bảo toàn quan hệ có lẽ là thách thức tích hợp quan trọng nhất đối với cơ sở tri thức, vì các kết nối giữa các thực thể dữ liệu có cấu trúc — mối quan hệ khóa ngoại, phụ thuộc phân cấp, trình tự thời gian và liên kết chéo bảng — mang logic nghiệp vụ quan trọng mà vector embedding một mình không thể biểu diễn. Cơ sở dữ liệu đồ thị như Amazon Neptune và Neo4j giải quyết vấn đề này bằng cách mô hình hóa rõ ràng các thực thể như nút và kết nối của chúng như các cạnh có kiểu, bảo toàn cấu trúc quan hệ tồn tại trong các hệ thống nguồn. Chúng cung cấp hỗ trợ nguyên sinh cho duyệt đa bước (multihop traversal), cho phép hệ thống RAG theo dõi chuỗi quan hệ và cung cấp đầy đủ ngữ cảnh quan hệ đó cho LLM cùng với nội dung được truy xuất về mặt ngữ nghĩa.
Chiến lược dữ liệu lai (Hybrid data strategies)
Các doanh nghiệp hiện đại sử dụng ba mẫu chính để kết hợp dữ liệu có cấu trúc và phi cấu trúc. Mẫu đầu tiên kết hợp tìm kiếm vector cho dữ liệu ngữ nghĩa với SQL cho các truy vấn có cấu trúc chính xác. Mẫu thứ hai kết hợp đồ thị tri thức cho các mối quan hệ dữ liệu rõ ràng với embedding cho tìm kiếm tương tự. Mẫu thứ ba áp dụng kiến trúc lakehouse cung cấp một nền tảng dữ liệu thống nhất với phần mở rộng vector, cung cấp các giải pháp tích hợp cho dữ liệu có cấu trúc, bán cấu trúc và phi cấu trúc trong một lớp lưu trữ và tính toán duy nhất.
Ví dụ thực tế: Goldman Sachs thể hiện tích hợp dữ liệu lai hiệu quả thông qua nền tảng GS AI Platform, kết hợp xử lý dữ liệu có cấu trúc và phi cấu trúc trong kiến trúc ưu tiên tuân thủ. Nền tảng tích hợp nhiều mô hình AI, bao gồm GPT-4, Gemini, Llama và Claude, hoạt động sau tường lửa của công ty với các kiểm soát quản trị toàn diện. Cách tiếp cận lai này đã đạt được hơn 50% mức độ áp dụng trong số 46.000+ nhân viên, với năng suất tăng 20% được báo cáo trong số các nhà phát triển và giảm 35% tỷ lệ dương tính giả trên các hệ thống chống rửa tiền và giám sát giao dịch.
Chất Lượng Dữ Liệu: Yếu Tố Sống Còn (Data Quality: The Make-or-Break Factor)
Sự thành công của các ứng dụng GenAI phụ thuộc căn bản vào chất lượng dữ liệu cơ bản. Khi các tổ chức ngày càng áp dụng GenAI và các hệ thống AI agentic, chất lượng dữ liệu kém nổi lên là rào cản quan trọng nhất đối với việc triển khai hiệu quả, dẫn đến đầu ra không chính xác, giảm niềm tin và thất bại trong triển khai.
Các Vấn Đề Chất Lượng Dữ Liệu Phổ Biến trong Cơ Sở Tri Thức
Cơ sở tri thức cho ứng dụng GenAI phải đối mặt với các vấn đề chất lượng dữ liệu tái diễn ảnh hưởng trực tiếp đến độ chính xác truy xuất và độ tin cậy phản hồi. Bảng 5-4 xác định các vấn đề phổ biến nhất, tác động của chúng đối với đầu ra GenAI và các chiến lược đã được chứng minh để phát hiện và giảm thiểu.
Bảng 5-4. Vấn đề chất lượng dữ liệu trong cơ sở tri thức và chiến lược giảm thiểu
| Vấn đề | Tác động đến GenAI | Phương pháp phát hiện | Chiến lược giảm thiểu |
|---|---|---|---|
| Dữ liệu không chính xác | Ảo giác, câu trả lời sai | Kiểm tra xác thực, kiểm tra nguồn | Nguồn uy tín, kiểm tra thực tế |
| Dữ liệu cũ (Stale data) | Phản hồi lỗi thời, thiếu liên quan | Giám sát độ tươi, dấu thời gian | Làm mới tự động, cập nhật hướng sự kiện |
| Dữ liệu trùng lặp | Thiên kiến, truy xuất dư thừa | Phát hiện tương tự, hashing | Pipeline loại trùng |
| Dữ liệu không đầy đủ | Câu trả lời một phần, khoảng trống | Phân tích phủ sóng, số liệu đầy đủ | Làm giàu dữ liệu, lấp đầy khoảng trống |
| Dữ liệu bị cô lập (Siloed) | Ngữ cảnh hạn chế, tri thức phân mảnh | Kiểm kê nguồn, kiểm tra khả năng tiếp cận | Tích hợp dữ liệu, truy cập thống nhất |
Nghiên cứu cho thấy các vấn đề chất lượng dữ liệu có tác động lan tỏa xuyên suốt hệ thống GenAI. Như Monte Carlo Data ghi nhận, chất lượng dữ liệu kém quyết định liệu các tổ chức có thấy "những hiểu biết đột phá hay những thất bại lan rộng" hay không, với các dự đoán xấu ngày càng khuếch đại khi tăng thêm sự phụ thuộc vào AI. Dữ liệu không chính xác dẫn đến các dự đoán và quyết định AI sai lầm, trong khi dữ liệu thiếu có thể đưa vào thiên kiến hoặc giảm hiệu quả mô hình. Thách thức đặc biệt cấp bách vì các hệ thống AI khuếch đại bất kỳ sự không nhất quán hoặc lỗi nào trong dữ liệu.
Số liệu chất lượng dữ liệu để giám sát liên tục
Các tổ chức phải triển khai giám sát toàn diện trên nhiều chiều: tỷ lệ chính xác (accuracy rate) đo phần trăm điểm dữ liệu chính xác về mặt thực tế; điểm độ tươi (freshness score) theo dõi tuổi trung bình của dữ liệu; chỉ số đầy đủ (completeness index) nắm bắt phần trăm các thuộc tính bắt buộc được điền; số liệu nhất quán (consistency measures) đánh giá tỷ lệ mâu thuẫn trên các nguồn; và phủ sóng xuất xứ (provenance coverage) theo dõi phần trăm dữ liệu với nguồn gốc có thể truy xuất.
Ví dụ thực tế: NatWest Bank đạt được cải thiện 150% trong sự hài lòng của khách hàng sau khi tích hợp GenAI với các hệ thống chatbot. Goldman Sachs báo cáo tăng 20-29% năng suất trong năm đầu triển khai trợ lý AI tăng cường RAG. Bằng cách ưu tiên dữ liệu sạch, có cấu trúc tốt hơn sự tinh vi của mô hình, các tổ chức này chứng minh rằng các lựa chọn kiến trúc dữ liệu thúc đẩy các lợi ích kinh doanh có ý nghĩa.
Nền Tảng Cơ Sở Dữ Liệu Vector: Biểu Diễn Dữ Liệu (Vector Database Fundamentals: Data Representation)
Các kỹ thuật tối ưu hóa đã thảo luận phụ thuộc vào một khả năng nền tảng: chuyển đổi dữ liệu phi cấu trúc thành các biểu diễn toán học mà máy móc có thể tìm kiếm và so sánh. Phần này xem xét các công nghệ cốt lõi làm cho truy xuất ngữ nghĩa có thể, từ các mô hình embedding đến cơ sở hạ tầng cơ sở dữ liệu chuyên biệt để lưu trữ và truy vấn hàng tỷ vector này ở quy mô.
Embedding và Chất Lượng Dữ Liệu
Embedding chuyển đổi dữ liệu phi cấu trúc thành các biểu diễn số học nắm bắt ý nghĩa ngữ nghĩa. Vector embedding là các biểu diễn số học nhiều chiều của dữ liệu (văn bản, hình ảnh, âm thanh) trong không gian đa chiều, nơi sự tương tự ngữ nghĩa được biểu diễn bởi khoảng cách gần. Chúng cho phép khớp khái niệm hơn là chỉ khớp từ khóa, hiểu các mối quan hệ giữa các từ và ý tưởng.
Chất lượng của dữ liệu đầu vào là yếu tố quyết định cơ bản về hiệu quả embedding — thường quan trọng hơn so với lựa chọn mô hình. Các mô hình nhỏ hơn, phù hợp với dữ liệu sạch, nhất quán thường vượt trội hơn các mô hình lớn hơn xử lý dữ liệu không nhất quán hoặc chứa nhiễu.
Tính chiều (dimensionality) là một trong những đánh đổi quan trọng nhất trong thiết kế hệ thống embedding. Các embedding 3.072 chiều cung cấp độ phân giải ngữ nghĩa tối đa nhưng tiêu thụ gần gấp đôi bộ nhớ và băng thông tính toán so với embedding 1.536 chiều. Nhiều mô hình embedding hiện đại hỗ trợ rút gọn chiều tại thời điểm truy vấn, cho phép điều chỉnh động: dùng chiều cao hơn cho các truy vấn phân tích phức tạp, và rút gọn chiều cho các khối lượng công việc nhạy cảm với độ trễ (như chatbot đối diện khách hàng) nơi thời gian phản hồi dưới 100ms quan trọng hơn lợi ích độ chính xác cận biên.
Cơ Sở Hạ Tầng Cơ Sở Dữ Liệu Vector
Cơ sở dữ liệu truyền thống tối ưu hóa cho khớp chính xác và truy vấn có cấu trúc, trong khi cơ sở dữ liệu vector tối ưu hóa cho tìm kiếm tương tự và dữ liệu nhiều chiều. Cơ sở dữ liệu vector thực hiện năm thao tác thiết yếu: - Nhập dữ liệu (Data ingestion): chuyển đổi nội dung thành vector và lưu trữ kèm siêu dữ liệu. - Lập chỉ mục dữ liệu (Data indexing): xây dựng các cấu trúc tìm kiếm hiệu quả (HNSW, IVF, PQ) để hỗ trợ truy xuất nhanh. - Truy xuất dữ liệu (Data retrieval): thực hiện tìm kiếm tương tự bằng thuật toán ANN. - Cập nhật dữ liệu (Data updates): quản lý các thao tác chèn, xóa và sửa đổi vector. - Lọc dữ liệu (Data filtering): kết hợp tìm kiếm tương tự vector với lọc dựa trên siêu dữ liệu.
Hệ thống RAG sản xuất hiếm khi phụ thuộc vào một phương pháp truy xuất duy nhất. Tìm kiếm lai (hybrid search) kết hợp tương tự vector dày đặc với khớp từ khóa thưa để nắm bắt cả ý nghĩa ngữ nghĩa và thuật ngữ chính xác. Hỗ trợ cách tiếp cận lai này đòi hỏi kết hợp nhiều chiến lược lập chỉ mục:
- Chỉ mục đảo ngược (Inverted index): Cực kỳ nhanh cho truy vấn từ khóa/Boolean, cung cấp đường cơ sở từ vựng cho tìm kiếm lai.
- HNSW (Hierarchical Navigable Small World): Chỉ mục ANN dựa trên đồ thị với khả năng thu hồi rất cao (95–99%) và tốc độ truy vấn rất nhanh, nhưng chi phí bộ nhớ cao. Lựa chọn mặc định cho hầu hết ứng dụng RAG xử lý đến 500 triệu vector.
- IVF-Flat (Inverted File với lưu trữ Flat): Cân bằng tốt giữa hiệu quả bộ nhớ và truy vấn, mở rộng đến tập dữ liệu quy mô tỷ vector.
- PQ (Product Quantization): Hiệu quả bộ nhớ xuất sắc, giảm lưu trữ đáng kể với một số đánh đổi độ chính xác (85–90% recall).
Giải Pháp Mã Nguồn Mở (Open Source Solutions)
Cơ sở dữ liệu vector mã nguồn mở cung cấp các giải pháp hiệu quả về chi phí cho các tổ chức tìm kiếm kiểm soát lớn hơn đối với cơ sở hạ tầng vector. Bảng 5-5 so sánh các giải pháp hàng đầu trên ba yếu tố quyết định chính: dung lượng dữ liệu, các tính năng kỹ thuật khác biệt và điều khoản cấp phép.
Bảng 5-5. So sánh cơ sở dữ liệu vector mã nguồn mở
| Cơ sở dữ liệu | Dung lượng dữ liệu | Tính năng dữ liệu chính | Kịch bản dữ liệu tốt nhất | Giấy phép |
|---|---|---|---|---|
| Milvus | 10B+ vector | 14 loại chỉ mục, RaBitQ giảm 72% bộ nhớ | Tập dữ liệu doanh nghiệp lớn | Apache 2.0 |
| Qdrant | Hàng tỷ | Tăng tốc GPU, lọc nâng cao | Truy xuất dữ liệu hiệu suất cao | Apache 2.0 |
| Weaviate | Hàng tỷ | Tìm kiếm lai (vector + từ khóa), mã hóa MUVERA | Các loại dữ liệu hỗn hợp | BSD 3-Clause |
| Chroma | <1M vector | API đơn giản, tự động nhúng | Tạo mẫu, tập dữ liệu nhỏ | Apache 2.0 |
| pgvector | 50M+ hiệu quả | Phần mở rộng PostgreSQL, tích hợp SQL | Dữ liệu PostgreSQL hiện có | PostgreSQL |
So Sánh Thuật Toán Lập Chỉ Mục Dữ Liệu (Data Indexing Algorithm Comparison)
Lựa chọn thuật toán lập chỉ mục là một trong những quyết định cơ sở hạ tầng quan trọng nhất trong triển khai cơ sở dữ liệu vector, vì nó xác định sự đánh đổi cơ bản giữa độ chính xác truy xuất (recall), tốc độ truy vấn và mức tiêu thụ bộ nhớ. Tìm kiếm láng giềng gần nhất chính xác bằng vũ lực sẽ đảm bảo recall hoàn hảo nhưng trở nên không khả thi về mặt tính toán ở quy mô — quét mọi vector trong cơ sở tri thức 100 triệu bản ghi cho mỗi truy vấn sẽ mất vài giây thay vì mili giây. Các thuật toán ANN giải quyết vấn đề này bằng cách xây dựng các cấu trúc dữ liệu chuyên biệt đánh đổi một lượng nhỏ recall để đổi lấy tìm kiếm nhanh hơn đáng kể, thường đạt được 90–99% recall trong khi giảm độ trễ truy vấn từ 10–100 lần so với phương pháp vũ lực.
Bảng 5-6. So sánh thuật toán lập chỉ mục cơ sở dữ liệu vector
| Thuật toán | Cấu trúc dữ liệu | Thời gian xây dựng | Tốc độ truy vấn | Sử dụng bộ nhớ | Recall | Quy mô tốt nhất |
|---|---|---|---|---|---|---|
| HNSW | Đồ thị nhiều lớp | Chậm | Rất nhanh | Cao | Rất cao (95–99%) | <500M vector |
| IVF-Flat | Phân vùng cụm | Nhanh | Nhanh | Trung bình | Cao (90–95%) | 100M–1B vector |
| IVF-PQ | Cụm + nén | Nhanh | Rất nhanh | Thấp | Trung bình (85–90%) | 1B+ vector |
| DiskANN | Đồ thị lưu trên đĩa | Rất chậm | Nhanh | Rất thấp | Cao (90–95%) | 10B+ vector |
| ScaNN | Tối ưu hóa phần cứng | Trung bình | Rất nhanh | Trung bình | Cao (90–95%) | Bất kỳ quy mô (GPU/TPU) |
DiskANN đẩy giới hạn xa hơn bằng cách lưu trữ chỉ mục đồ thị trên đĩa thay vì trong bộ nhớ, cho phép triển khai quy mô 10 tỷ vector với RAM tối thiểu nhưng đòi hỏi thời gian xây dựng lâu hơn. ScaNN, do Google phát triển, tối ưu hóa đặc biệt cho tăng tốc phần cứng trên GPU và TPU, mang lại tốc độ truy vấn rất nhanh trên bất kỳ quy mô dữ liệu nào khi có sẵn cơ sở hạ tầng tính toán chuyên biệt.
Kỹ thuật nén dữ liệu (Data Compression Techniques)
Cơ sở dữ liệu vector hiện đại sử dụng các phương pháp nén tinh vi để tối ưu hóa lưu trữ và hiệu suất: - Lượng tử hóa vô hướng (Scalar quantization): Float32 → Int8 = giảm 75% kích thước, mất chất lượng tối thiểu - Lượng tử hóa nhị phân (Binary quantization): Float32 → 1-bit = giảm 97% kích thước, mất chất lượng vừa phải - Lượng tử hóa tích (Product quantization): Nén không gian con = giảm 10–30 lần
Ví dụ: Milvus RaBitQ đạt đến 32 lần kích thước nén trong khi duy trì 95% recall.
So Sánh Tính Năng Quản Trị Dữ Liệu (Data Governance Feature Comparison)
Các triển khai doanh nghiệp đòi hỏi các khả năng quản trị mạnh mẽ vượt ra ngoài các số liệu hiệu suất thô. Khi một công ty dịch vụ tài chính hoặc tổ chức chăm sóc sức khỏe đánh giá cơ sở dữ liệu vector, các chứng nhận bảo mật, tiêu chuẩn mã hóa và mô hình kiểm soát quyền truy cập thường có trọng lượng lớn hơn các điểm chuẩn độ trễ truy vấn. Khoảng cách quản trị giữa các giải pháp mã nguồn mở và thương mại đại diện cho một trong những chi phí ẩn đáng kể nhất trong lựa chọn cơ sở dữ liệu vector, vì các tổ chức chọn giải pháp mã nguồn mở phải tự xây dựng và duy trì cơ sở hạ tầng mã hóa, kiểm soát quyền truy cập, sao lưu, giám sát và tuân thủ.
Bảng 5-7 so sánh các khả năng quản trị trên hai mô hình triển khai.
Bảng 5-7. Khả năng quản trị dữ liệu qua các mô hình triển khai cơ sở dữ liệu vector
| Tính năng | Mã nguồn mở | Thương mại có quản lý |
|---|---|---|
| Mã hóa dữ liệu | Cài đặt thủ công | Tích hợp (at rest + in transit) |
| Kiểm soát truy cập dữ liệu | RBAC tự triển khai | Enterprise RBAC, SSO |
| Sao lưu dữ liệu | Thủ công | Tự động, point-in-time |
| Giám sát dữ liệu | Công cụ tự lưu trữ | Dashboard tích hợp |
| Tuân thủ dữ liệu | Tự chứng nhận | SOC 2, ISO 27001, GDPR |
| Cô lập dữ liệu | Multi-tenancy thủ công | Multi-tenant nguyên sinh |
Lựa Chọn Dựa Trên Yêu Cầu Dữ Liệu (Selecting Based on Data Requirements)
Với cảnh quan của các giải pháp mã nguồn mở, thương mại và được quản lý đã được xác lập, câu hỏi thực tế là: Giải pháp nào phù hợp với nhu cầu cụ thể của một tổ chức? Câu trả lời phụ thuộc không phải vào cơ sở dữ liệu nào xếp hạng cao nhất trên các điểm chuẩn mà vào mức độ phù hợp của các đặc điểm của nó với bốn yêu cầu giao nhau: quy mô dữ liệu, độ nhạy cảm dữ liệu, cơ sở hạ tầng hiện có và ràng buộc ngân sách.
Quy mô dữ liệu quyết định kiến trúc cơ sở dữ liệu phù hợp với phân loại sơ bộ hữu ích: nhỏ (<10M vector) thích hợp nhất cho Chroma để tạo mẫu nhanh, hoặc pgvector nếu dữ liệu đã có trong PostgreSQL; trung bình (10M–100M vector) phù hợp với hầu hết các giải pháp; lớn (100M–1B vector) phù hợp với Qdrant và Weaviate vì kiến trúc phân tán của chúng cho phép tổ chức quản lý hơn 1 tỷ vector cho các triển khai doanh nghiệp. Độ nhạy cảm dữ liệu xác định liệu dữ liệu vector có thể rời khỏi môi trường kiểm soát của tổ chức hay không. Cơ sở hạ tầng hiện có nên ảnh hưởng đáng kể đến lựa chọn. Ràng buộc ngân sách định hình lựa chọn triển khai.
RAG: Lớp Truy Xuất Dữ Liệu (RAG: The Data Retrieval Layer)
Trước đó chúng ta đã xác lập các nền tảng dữ liệu biến đổi dữ liệu phi cấu trúc thành các cơ sở tri thức động và hệ thống thông minh truy xuất thông tin liên quan từ chúng. Phần này kết hợp những nền tảng này lại với nhau, giải thích cách RAG giải quyết vấn đề truy cập dữ liệu cốt lõi của GenAI, cách dữ liệu chảy qua một hệ thống RAG và cách tối ưu hóa từng giai đoạn đó để đạt chất lượng tối đa.
Tại Sao RAG? Vấn Đề Truy Cập Dữ Liệu (Why RAG? The Data Access Problem)
Các mô hình ngôn ngữ lớn, dù mạnh mẽ đến đâu, đều phải đối mặt với một hạn chế cơ bản: kiến thức của chúng bị đóng băng tại thời điểm đào tạo. Đào tạo lại hoặc tinh chỉnh các mô hình cho các nhiệm vụ cụ thể thì tốn kém và không thể mở rộng cho các môi trường dữ liệu động nơi thông tin thay đổi thường xuyên. Các tổ chức cần các hệ thống GenAI có thể truy cập dữ liệu độc quyền hiện tại của họ để cung cấp các phản hồi chính xác, cập nhật được căn cứ vào các nguồn uy quyền.
RAG giải quyết những hạn chế này bằng cách kết hợp các khả năng tạo sinh của LLM với truy xuất thông tin động, cho phép các hệ thống AI truy cập và suy luận trên kiến thức tổ chức.
Kiến Trúc RAG: Luồng Dữ Liệu (The RAG Architecture: Data Flow)
Hiểu cách dữ liệu chảy qua hệ thống RAG là thiết yếu để thiết kế các triển khai hiệu quả. Hình 5-2 minh họa hành trình từ truy vấn người dùng đến phản hồi có căn cứ, với mỗi giai đoạn đại diện cho một biến đổi dữ liệu quan trọng quyết định chất lượng đầu ra.
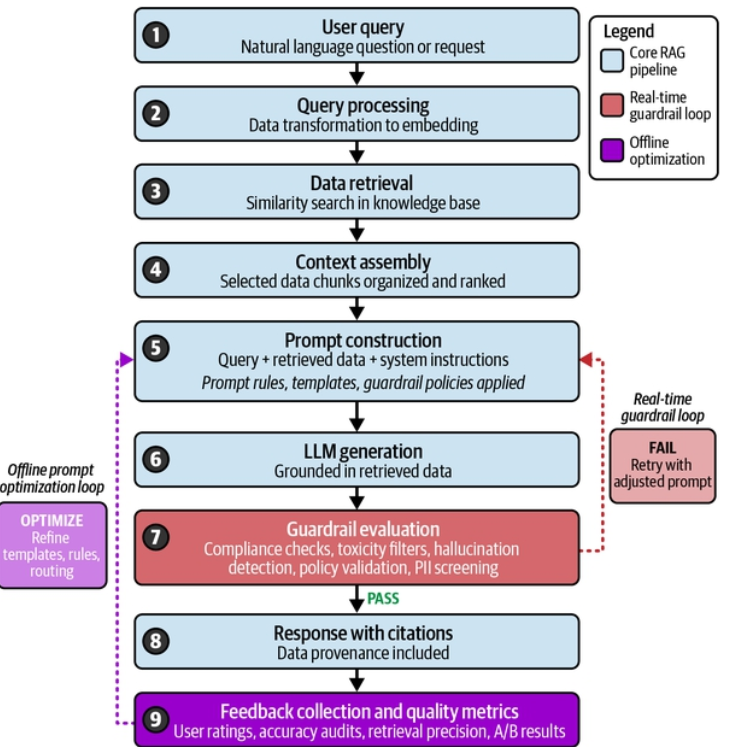
Kiến trúc được thể hiện trong Hình 5-2 biến đổi các hệ thống AI tĩnh thành các ứng dụng năng động, nhận thức tri thức có thể cung cấp các phản hồi liên quan về mặt ngữ cảnh dựa trên thông tin hiện tại.
Lợi ích dữ liệu tập trung của RAG (Data-centric benefits of RAG)
Kiến trúc RAG mang lại những lợi thế riêng biệt giải quyết các thách thức dữ liệu cốt lõi mà doanh nghiệp phải đối mặt khi triển khai hệ thống GenAI. Độ tươi dữ liệu đảm bảo rằng các cơ sở tri thức có thể được cập nhật liên tục, cho phép các ứng dụng GenAI truy cập thông tin hiện tại vượt ra ngoài ngày cắt đào tạo của chúng. Căn cứ dữ liệu có nghĩa là các phản hồi được hỗ trợ bởi các nguồn cụ thể được truy xuất từ cơ sở tri thức, giảm đáng kể các trường hợp ảo giác AI và thông tin bịa đặt. Việc căn cứ này cho phép quy kết dữ liệu, nơi các trích dẫn cung cấp khả năng truy xuất và truy vết thiết yếu cho trách nhiệm giải trình và tuân thủ doanh nghiệp. Chủ quyền dữ liệu đảm bảo kiến thức doanh nghiệp ở trong ranh giới doanh nghiệp trong khi vẫn cung cấp năng lực AI — cơ sở tri thức không bao giờ trở thành một phần tham số của mô hình, duy trì ranh giới quản trị dữ liệu rõ ràng.
Tiến Hóa Kiến Trúc RAG: Từ Đơn Giản đến Agentic (RAG Architecture Evolution: From Simple to Agentic)
Các kiến trúc RAG đã phát triển đáng kể kể từ khi Meta giới thiệu cách tiếp cận này vào năm 2020, với mỗi thế hệ giải quyết các yêu cầu truy xuất và suy luận dữ liệu ngày càng phức tạp. Bảng 5-8 tóm tắt các mẫu kiến trúc chính, từ các triển khai truy xuất cơ bản đến các hệ thống agentic tinh vi tự trị điều phối thu thập tri thức đa bước.
Bảng 5-8. So sánh các loại kiến trúc RAG
| Kiến trúc RAG | Mô tả | Tính năng chính | Phù hợp nhất | Hạn chế |
|---|---|---|---|---|
| Simple RAG | Truy xuất cơ bản từ cơ sở dữ liệu tĩnh | Triển khai đơn giản, ít phức tạp | Trả lời câu hỏi đơn giản, tra cứu thực tế | Nhận thức ngữ cảnh hạn chế, không có bộ nhớ các tương tác trước |
| Simple RAG với bộ nhớ | Thêm lưu trữ cho các tương tác trước | Duy trì lịch sử hội thoại, cung cấp liên tục | Ứng dụng hội thoại, tương tác cá nhân hóa | Tăng độ phức tạp, lo ngại quyền riêng tư tiềm ẩn |
| Branched RAG | Xác định nguồn dữ liệu cụ thể dựa trên đầu vào | Truy xuất có mục tiêu, giảm nhiễu, tri thức chuyên biệt | Ứng dụng chuyên ngành, hệ thống đa miền | Yêu cầu phân loại nhánh chính xác |
| Adaptive RAG | Điều chỉnh chiến lược truy xuất dựa trên độ phức tạp truy vấn | Tối ưu hóa sử dụng tài nguyên, cải thiện độ chính xác | Ứng dụng với các loại truy vấn đa dạng | Yêu cầu phân loại truy vấn |
| Self-RAG | Cho phép tạo truy vấn truy xuất tự trị | Giảm ảo giác, cải thiện độ chính xác thực tế | Ứng dụng yêu cầu độ chính xác thực tế cao | Tăng độ trễ, yêu cầu tính toán cao hơn |
| Agentic RAG | Giới thiệu hành vi tự trị, giống agent | Suy luận phức tạp, sử dụng công cụ, lập kế hoạch đa bước | Nhiệm vụ phức tạp yêu cầu suy luận và lập kế hoạch | Độ phức tạp cao nhất, thách thức để triển khai và gỡ lỗi |
Sự tiến hóa của các kiến trúc RAG phản ánh sự tinh vi ngày càng tăng trong việc xử lý các kịch bản dữ liệu và yêu cầu người dùng phức tạp. RAG đơn giản cung cấp chức năng truy xuất cơ bản, trong khi các kiến trúc nâng cao như agentic RAG nhúng các khả năng agent tự trị bao gồm lập kế hoạch, phản ánh, sử dụng công cụ và các chiến lược thích ứng để điều phối truy xuất và tạo sinh một cách năng động.
Các tổ chức tài chính hàng đầu thể hiện giá trị thực tiễn của sự tiến hóa RAG trên các mức độ tinh vi kiến trúc khác nhau. Triển khai RAG cơ bản của JPMorgan cho xử lý KYC (Know Your Customer — Biết khách hàng của bạn) đạt được tăng 90% năng suất, cho phép 20% ít nhân viên hơn xử lý 48% tệp nhiều hơn. NatWest triển khai RAG có bộ nhớ cho tích hợp dịch vụ khách hàng với chatbot, đạt 150% cải thiện sự hài lòng của khách hàng. Triển khai agentic RAG tinh vi hơn của Goldman Sachs cho quản lý tri thức nội bộ mang lại ước tính tăng năng suất lên đến 29% trong năm đầu tiên.
Sự tiến hóa từ truy xuất cơ bản đến các hệ thống agentic đại diện cho sự thay đổi cơ bản từ truy cập thông tin tĩnh sang công việc tri thức năng động, được kích hoạt bởi suy luận có thể thích ứng với các yêu cầu doanh nghiệp phức tạp trong khi duy trì các lợi ích cốt lõi của các phản hồi AI có căn cứ, có thể xác minh. Điều quan trọng là bắt đầu với các vấn đề kinh doanh rõ ràng và lặp lại dựa trên phản hồi thực tế, theo nguyên tắc bắt đầu chu kỳ học tập hơn là cố gắng "đun sôi đại dương" từ đầu.
Phân Đoạn Dữ Liệu: Yếu Tố Quan Trọng cho Hiệu Suất RAG (Data Chunking: Critical for RAG Performance)
Các mô hình ngôn ngữ lớn phải đối mặt với các hạn chế cơ bản làm cho phân đoạn dữ liệu trở nên thiết yếu cho các triển khai RAG hiệu quả. Cửa sổ ngữ cảnh LLM bị giới hạn, thường dao động từ 4k đến 128k token, trong khi các tài liệu doanh nghiệp thường vượt xa những giới hạn này đáng kể. Điều này tạo ra nhu cầu quan trọng phải truy xuất các đoạn có liên quan nhất thay vì toàn bộ tài liệu.
Nghiên cứu chứng minh rằng chiến lược phân đoạn dữ liệu có tác động ấn tượng nhất đến hiệu suất RAG, với một nghiên cứu được trích dẫn trong phần "Biến đổi dữ liệu bảy giai đoạn" cho thấy cải thiện hiệu suất 35% từ việc chọn chiến lược phân đoạn tối ưu, so với cải thiện 27% từ embeddings tốt hơn và chỉ 6% cải thiện từ việc thay đổi LLM.
Hiểu biết quan trọng cần rút ra ở đây là phân đoạn dữ liệu quan trọng hơn lựa chọn mô hình từ 5 đến 6 lần. Phát hiện này thay đổi cơ bản cách các tổ chức nên ưu tiên các nỗ lực tối ưu hóa RAG — tập trung vào cải thiện các thành phần truy xuất mang lại lợi ích hiệu suất lớn nhất, thay vì theo đuổi các mô hình ngôn ngữ tinh vi hơn.
Các Chiến Lược Phân Đoạn Dữ Liệu Toàn Diện (Comprehensive Data Chunking Strategies)
Việc chọn đúng phương pháp phân đoạn đòi hỏi hiểu biết về cách các chiến lược khác nhau xử lý cấu trúc tài liệu, tính liên kết ngữ nghĩa và độ chính xác truy xuất. Bảng 5-9 so sánh các chiến lược phân đoạn chính có sẵn cho các triển khai RAG doanh nghiệp, nêu bật sự đánh đổi và các trường hợp sử dụng tối ưu.
Bảng 5-9. So sánh các chiến lược phân đoạn cho triển khai RAG doanh nghiệp
| Chiến lược | Mô tả | Ưu điểm | Nhược điểm | Trường hợp sử dụng tốt nhất |
|---|---|---|---|---|
| Phân đoạn kích thước cố định (Fixed-size chunking) | Chia văn bản thành các đoạn bằng nhau (vd: 400 từ hoặc 800 ký tự) | Triển khai đơn giản, hiệu quả tính toán, kích thước đoạn có thể dự đoán | Có thể phá vỡ đơn vị ngữ nghĩa, có thể cắt câu một cách khó xử | Triển khai đơn giản, tài liệu đồng nhất |
| Phân đoạn theo câu (Sentence-based chunking) | Chia văn bản tại ranh giới câu tự nhiên bằng dấu câu | Bảo toàn tính dễ đọc, đảm bảo các đoạn tự chứa, tôn trọng luồng ngôn ngữ tự nhiên | Kích thước đoạn thay đổi, có thể bỏ lỡ các mối quan hệ ngữ nghĩa sâu hơn | Nội dung có cấu trúc câu rõ ràng, văn bản hội thoại |
| Phân đoạn đệ quy (Recursive chunking) | Áp dụng quy tắc chia nhỏ theo thứ bậc (phần → đoạn → câu) | Bảo toàn cấu trúc tài liệu, triển khai linh hoạt, tương thích với cửa sổ ngữ cảnh mô hình | Triển khai phức tạp hơn, phụ thuộc vào cấu trúc tài liệu | Hướng dẫn kỹ thuật, tài liệu có cấu trúc, bài báo học thuật |
| Phân đoạn ngữ nghĩa (Semantic chunking) | Chia văn bản dựa trên nghĩa sử dụng embeddings hoặc độ tương tự ngữ nghĩa | Tính liên kết, phù hợp với ý định người dùng, cải thiện độ chính xác truy xuất | Chi phí cao, yêu cầu embedding trong tiền xử lý | Tài liệu pháp lý, văn bản y tế |
| Phân đoạn cửa sổ trượt (Sliding window chunking) | Tạo các đoạn chồng chéo bằng cách trượt cửa sổ kích thước cố định qua văn bản | Bảo toàn ngữ cảnh qua ranh giới, cải thiện độ chính xác truy xuất, xử lý văn bản liên tục | Giới thiệu chồng chéo nội dung giữa các đoạn, có thể tiêu thụ token cửa sổ ngữ cảnh LLM với thông tin dư thừa khi truy xuất | Văn bản phi cấu trúc, bản ghi âm, nhật ký trò chuyện |
| Phân đoạn phân cấp (Hierarchical chunking) | Bảo toàn cấu trúc tài liệu trong cây từ phần đến câu | Cho phép điều hướng linh hoạt, cải thiện độ chính xác và thu hồi, điều chỉnh phạm vi nội dung trả về | Thêm độ phức tạp vào logic tiền xử lý và truy xuất | Hợp đồng pháp lý, báo cáo tài chính, thông số kỹ thuật |
| Phân đoạn theo chủ đề (Topic-based chunking) | Nhóm văn bản theo đơn vị chủ đề sử dụng thuật toán như Phân phối Dirichlet ẩn (LDA) | Giữ nội dung liên quan lại với nhau, phù hợp với ý định người dùng, cải thiện tính liên kết ngữ nghĩa | Thêm độ phức tạp, có thể yêu cầu chuyên môn lĩnh vực | Nội dung dài, báo cáo nghiên cứu, bài báo |
| Phân đoạn động điều khiển bởi AI (AI-driven dynamic chunking) | Sử dụng LLM để xác định ranh giới đoạn một cách thích ứng | Tạo các đoạn liên kết ngữ nghĩa, nắm bắt khái niệm hoàn chỉnh, thích nghi với cấu trúc tài liệu | Ranh giới đoạn không xác định qua các lần nhập liệu lặp lại có thể làm phức tạp tính tái tạo và khả năng kiểm toán trong môi trường được quản lý | Tài liệu có giá trị cao, nội dung kỹ thuật phức tạp |
Nghiên cứu cho thấy kích thước đoạn tối ưu thay đổi theo tập dữ liệu và độ phức tạp của nhiệm vụ. Các đoạn nhỏ hơn (64–128 token) hoạt động tốt nhất cho các truy vấn dựa trên sự kiện ngắn gọn, trong khi các đoạn lớn hơn (512–1.024 token, hoặc ~1.800–3.600 ký tự) phục vụ tốt hơn các tập dữ liệu yêu cầu ngữ cảnh rộng.
Hướng Dẫn Phân Đoạn Dữ Liệu Theo Loại (Data-Specific Chunking Guidelines)
Các loại nội dung khác nhau đòi hỏi các phương pháp phân đoạn phù hợp để tối đa hóa hiệu quả truy xuất. Bảng 5-10 cung cấp các khuyến nghị dựa trên các thực hành tốt nhất hiện tại để khớp chiến lược phân đoạn với các loại tài liệu cụ thể và các trường hợp sử dụng thường gặp trong cơ sở tri thức doanh nghiệp. Các khuyến nghị này giả định kích thước cửa sổ ngữ cảnh LLM, khả năng mô hình embedding và độ trưởng thành của công cụ tiền xử lý hiện tại; khi các mô hình ngôn ngữ nhỏ trở nên nhanh hơn và rẻ hơn, phân đoạn động điều khiển bởi AI có khả năng trở thành phương pháp mặc định cho hầu hết các loại nội dung. Đáng chú ý, các cân nhắc chính trong bảng này có thể phục vụ trực tiếp như hướng dẫn prompt cho phân đoạn dựa trên LLM — thay vì triển khai các bộ phân tích dựa trên quy tắc phức tạp, các tổ chức có thể truyền các hướng dẫn này như system prompt cho một mô hình ngôn ngữ nhỏ và để mô hình xử lý các quyết định phân đoạn, biến chuyên môn lĩnh vực thành các template prompt có thể tái sử dụng.
Bảng 5-10. Khuyến nghị phân đoạn theo loại nội dung
| Loại nội dung | Chiến lược đề xuất | Kích thước đoạn | Chồng chéo | Các cân nhắc chính |
|---|---|---|---|---|
| Hợp đồng pháp lý | Phân đoạn phân cấp | 512–1.024 token | 40–50% | Bảo toàn cấu trúc điều khoản; duy trì tham chiếu luật định và trích dẫn án lệ |
| Báo cáo tài chính | Phân đoạn phân cấp | 512–1.024 token | 30–40% | Bảo toàn mối quan hệ phần và ngữ cảnh số; bảng yêu cầu trích xuất chuyên biệt (mô hình đa phương thức hoặc phân tích bảng) trước khi phân đoạn để duy trì mối quan hệ hàng/cột |
| Tài liệu kỹ thuật | Phân đoạn đệ quy | 256–512 token | 20–30% | Tôn trọng cấu trúc tiêu đề; bảo toàn khối code; duy trì chuỗi bước |
| Văn bản y tế/lâm sàng | Phân đoạn ngữ nghĩa | 256–512 token | 40–50% | Bảo toàn mối quan hệ chẩn đoán/điều trị; duy trì ngữ cảnh thuật ngữ y tế |
| Nội dung hội thoại | Phân đoạn theo câu hoặc theo lượt | 128–256 token | 20–30% | Nhóm cặp hỏi/đáp và yêu cầu/phản hồi như đơn vị nguyên tử; bảo toàn siêu dữ liệu gán nhận người nói; duy trì chuỗi thời gian qua các lượt trao đổi |
| Bài báo nghiên cứu | Phân đoạn phân cấp hoặc ngữ nghĩa | 512–1.024 token | 20–30% | Tận dụng cấu trúc bài báo chuẩn (tóm tắt, phương pháp, kết quả, thảo luận); bảo toàn ngữ cảnh trích dẫn và tham chiếu chéo; duy trì luồng lập luận |
| Nhật ký hỗ trợ khách hàng | Phân đoạn theo vé hoặc đệ quy | 128–256 token | 30–40% | Coi mỗi chuỗi vấn đề-giải pháp là đơn vị nguyên tử; bảo toàn chuỗi leo thang và thứ tự thời gian; duy trì liên kết giữa mô tả triệu chứng và các bước giải quyết |
| Tài liệu sản phẩm | Phân đoạn đệ quy | 256–512 token | 20–30% | Duy trì nhóm tính năng, bảo toàn các bước quy trình |
| Bài báo tin tức | Phân đoạn ngữ nghĩa | 256–512 token | 10–20% | Bảo toàn tính liên kết đoạn văn, duy trì cấu trúc tường thuật |
| FAQ và bài viết tri thức | Phân đoạn cặp hỏi/đáp | 128–256 token | 10–20% | Coi mỗi cặp hỏi/đáp là đơn vị nguyên tử; không chia nhỏ trong một cặp bất kể độ dài token; gắn thẻ siêu dữ liệu đơn giản (danh mục, sản phẩm, phiên bản) tăng cường lọc |
Làm Phong Phú Siêu Dữ Liệu Đoạn (Chunk Metadata Enrichment)
Làm phong phú các đoạn với siêu dữ liệu là một trong những tối ưu hóa có tác động cao nhất ngoài chiến lược phân đoạn, với nghiên cứu chứng minh cải thiện độ chính xác truy xuất lên đến 21% và cải thiện độ chính xác từ 73% lên 83% khi siêu dữ liệu như thực thể, chủ đề và thuộc tính nguồn được tích hợp vào biểu diễn đoạn:
- Siêu dữ liệu cấu trúc (Structural metadata): Tiêu đề phần, tiêu đề tài liệu, số trang
- Siêu dữ liệu thời gian (Temporal metadata): Ngày tạo, ngày sửa đổi cuối, phiên bản
- Siêu dữ liệu nguồn (Source metadata): Tác giả, bộ phận, hệ thống gốc
- Siêu dữ liệu ngữ nghĩa (Semantic metadata): Thực thể được trích xuất, chủ đề, danh mục
Chiến Lược Chồng Chéo để Liên Tục Dữ Liệu (Overlap Strategy for Data Continuity)
Các chiến lược chồng chéo bảo toàn ngữ cảnh qua ranh giới đoạn, ngăn chặn mất ý nghĩa xảy ra khi nội dung liên quan bị chia giữa các đoạn kề nhau. Tỷ lệ chồng chéo phù hợp phụ thuộc vào đặc điểm nội dung và yêu cầu truy xuất:
- Chồng chéo 20–30%: Tiêu chuẩn cho hầu hết tài liệu
- Chồng chéo 40–50%: Phụ thuộc ngữ cảnh cao (pháp lý, y tế)
- Chồng chéo 10–20%: Nội dung có cấu trúc cao, được tiêu chuẩn hóa
- Cửa sổ trượt (Sliding window): Chồng chéo liên tục cho các tường thuật
Các tổ chức hàng đầu áp dụng các chiến lược phân đoạn đặc thù theo lĩnh vực để tối đa hóa hiệu suất RAG. Phân đoạn phân cấp là phương pháp được khuyến nghị cho tài liệu tài chính, bảo toàn cấu trúc báo cáo, bảng và tài liệu quy định. Hệ thống RAG pháp lý tương tự tận dụng phân đoạn phân cấp để duy trì cấu trúc luật định và trích dẫn án lệ, cho phép nghiên cứu pháp lý và kiểm tra tuân thủ đáng tin cậy hơn. Các triển khai RAG chăm sóc sức khỏe hưởng lợi từ phân đoạn ngữ nghĩa duy trì mối quan hệ chẩn đoán/điều trị, cải thiện hỗ trợ quyết định lâm sàng bằng cách giữ các khái niệm y tế liên quan lại với nhau.
Hiểu biết chính là chiến lược phân đoạn phải phù hợp với cấu trúc tài liệu và yêu cầu trường hợp sử dụng. Phân đoạn kém chia các phần có ý nghĩa giữa câu hoặc qua các chủ đề không liên quan dẫn đến kết quả truy xuất bị phân mảnh, trong khi phân đoạn đúng giữ nguyên ngữ cảnh và cho phép so khớp chính xác hơn cho các truy vấn. Các tổ chức nên bắt đầu với các phương pháp phân đoạn đơn giản hơn và lặp lại dựa trên các số liệu hiệu suất để gặt hái toàn bộ tiềm năng của tối ưu hóa có tác động cao này.
Tối Ưu Hóa Truy Xuất Dữ Liệu cho RAG (Data Retrieval Optimization for RAG)
Tối ưu hóa cách dữ liệu được truy xuất có thể mang lại cải thiện đáng kể về độ chính xác và độ trễ trong các hệ thống RAG. Bảng 5-11 so sánh các phương pháp truy xuất chính có sẵn, từ đường cơ sở đơn phương pháp đến các kỹ thuật lai và tổ hợp kết hợp nhiều nguồn dữ liệu để cải thiện độ chính xác.
Bảng 5-11. Các phương pháp truy xuất dữ liệu RAG
| Phương pháp | Nguồn dữ liệu | Cơ chế | Hiệu suất | Khi nào dùng |
|---|---|---|---|---|
| Chỉ dày đặc (Dense only) | Vector embeddings | Tương tự ngữ nghĩa | Đường cơ sở | Tìm kiếm ngữ nghĩa chung |
| Chỉ thưa (Sparse only) | Chỉ mục từ khóa (BM25) | Khớp thuật ngữ | Tốt cho thuật ngữ chính xác | Truy vấn thuật ngữ đã biết |
| Lai (dense + sparse) | Vector embeddings và chỉ mục từ khóa | Kết hợp có trọng số | 35%+ trên benchmark QA; thay đổi theo lĩnh vực | Các loại truy vấn hỗn hợp |
| Tổ hợp (Ensemble) | Nhiều bộ truy xuất | Bỏ phiếu/xếp hạng | +20–30% | Nhu cầu độ chính xác cao |
Tìm kiếm lai kết hợp nhiều phương pháp truy xuất để tận dụng điểm mạnh bổ sung của chúng. Trên các benchmark chuẩn như BEIR, các phương pháp lai liên tục vượt trội so với truy xuất đơn phương pháp, với mức tăng từ cải thiện khiêm tốn trên các tập dữ liệu đặc thù theo lĩnh vực đến 35% hoặc nhiều hơn trên các benchmark trả lời câu hỏi rộng, đặc biệt cho các truy vấn chứa cả khái niệm ngữ nghĩa và thuật ngữ cụ thể. Sự kết hợp tìm kiếm vector với các phương pháp dựa trên từ khóa như BM25 cân bằng truy xuất thông tin truyền thống với các phương pháp neural.
Chiến Lược Xếp Hạng Lại Dữ Liệu (Data Reranking Strategies)
Trong khi truy xuất ban đầu trả về một tập ứng viên các tài liệu có liên quan, các kết quả hàng đầu không phải lúc nào cũng được sắp xếp tối ưu cho ý định truy vấn cụ thể của người dùng. Xếp hạng lại (Reranking) áp dụng các mô hình tinh vi hơn cho tập ban đầu này, tinh chỉnh thứ tự dựa trên phân tích ngữ nghĩa sâu hơn về mối quan hệ truy vấn–tài liệu. Phương pháp hai giai đoạn này — truy xuất ban đầu nhanh theo sau bởi xếp hạng lại chính xác — cân bằng nhu cầu về tốc độ ở quy mô với các yêu cầu độ chính xác của hệ thống sản xuất. Cross-encoder reranking, ví dụ, đã chứng minh mức tăng đáng kể trên các benchmark, với cải thiện lên đến 10 điểm NDCG (normalized discounted cumulative gain) so với truy xuất bi-encoder trên MS MARCO và cải thiện 59% mean reciprocal rank (MRR) tuyệt đối trên các nhiệm vụ truy xuất tài liệu tài chính, mặc dù nó giới thiệu độ trễ bổ sung phải được quản lý thông qua thiết kế kiến trúc cẩn thận.
Bảng 5-12. Chiến lược xếp hạng lại dữ liệu
| Kỹ thuật | Cách hoạt động | Tác động dữ liệu | Hiệu suất | Chi phí | Phù hợp nhất |
|---|---|---|---|---|---|
| Không xếp hạng lại | Sử dụng điểm truy xuất nguyên trạng | N/A | Đường cơ sở | Thấp | Ứng dụng đơn giản |
| Cross-encoder | Chú ý toàn bộ truy vấn/tài liệu | Tính lại điểm tất cả ứng viên | +5–10 điểm NDCG so với bi-encoder; đến +28% NDCG@10 | Cao | Nhu cầu độ chính xác cao |
| Đa giai đoạn (Multistage) | Lọc nhanh → xếp hạng lại chính xác | Chỉ xử lý top k | Gần chất lượng cross-encoder ở độ trễ thấp hơn 2–3× | Trung bình | Cân bằng độ chính xác/tốc độ |
| Ngữ cảnh hóa (Contextual) | Sử dụng ngữ cảnh, lịch sử người dùng | Liên quan cá nhân hóa | Thay đổi theo triển khai | Trung bình | Hệ thống cá nhân hóa |
| Dựa trên LLM (LLM-based) | LLM đánh giá mức độ liên quan | Chấm điểm tinh vi | Mạnh nhất trên truy vấn multi-hop phức tạp; chi phí tính toán cao nhất | Rất cao | Ứng dụng quan trọng |
Xếp hạng lại cải thiện độ chính xác truy xuất bằng cách áp dụng các mô hình tinh vi hơn cho một tập ban đầu các tài liệu được truy xuất. Cross-encoder áp dụng cơ chế chú ý qua các cặp truy vấn/tài liệu để đánh giá mức độ liên quan chính xác hơn, trong khi xếp hạng đa giai đoạn sử dụng các mô hình ngày càng phức tạp hơn trên các tập tài liệu nhỏ hơn. Phương pháp phân lớp này cho phép hệ thống cân bằng chi phí tính toán với độ chính xác, sử dụng các phương pháp nhanh nhẹ nhàng cho truy xuất ban đầu và dành đánh giá cross-encoder tốn kém cho các ứng viên hứa hẹn nhất.
Biến Đổi Truy Vấn để Truy Xuất Dữ Liệu Tốt Hơn (Query Transformation for Better Data Retrieval)
Các kỹ thuật biến đổi truy vấn (query transformation) sửa đổi truy vấn người dùng để cải thiện hiệu quả truy xuất trước khi tìm kiếm được thực thi. Mở rộng truy vấn (Query expansion) thêm từ đồng nghĩa và các thuật ngữ liên quan để mở rộng phạm vi tìm kiếm, cải thiện thu hồi cho các truy vấn phức tạp hoặc mơ hồ có thể bỏ lỡ các tài liệu liên quan do không khớp từ vựng. Viết lại truy vấn (Query rewriting) diễn đạt lại các truy vấn mơ hồ hoặc có cấu trúc kém để rõ ràng hơn, giúp thu hẹp khoảng cách giữa cách người dùng tự nhiên diễn đạt nhu cầu thông tin và cách nội dung được lập chỉ mục. Phân rã truy vấn (Query decomposition) chia nhỏ các truy vấn phức tạp thành các truy vấn con đơn giản hơn, cho phép truy xuất chính xác hơn cho các câu hỏi đa phần mà mỗi thành phần có thể yêu cầu nguồn thông tin khác nhau. Hypothetical Document Embeddings (HyDE) áp dụng phương pháp sinh bằng cách trước tiên tạo ra một câu trả lời giả thuyết lý tưởng cho truy vấn và sau đó sử dụng văn bản được tạo ra đó để tìm kiếm các tài liệu thực tế tương tự. Trong nghiên cứu HyDE gốc, kỹ thuật zero-shot này đã cải thiện NDCG@10 từ 44,5 lên 61,3 trên TREC DL-20 so với baseline Contriever không giám sát — mức tăng tương đối 38% — và đạt được điểm mean average precision (mAP) cạnh tranh với các bộ truy xuất fine-tuned có giám sát, tất cả mà không cần bất kỳ nhãn liên quan nào.
Các kỹ thuật biến đổi này có một đánh đổi chung: trong khi chúng có thể cải thiện đáng kể thu hồi và độ chính xác, chúng yêu cầu điều chỉnh cẩn thận để tránh lệch khỏi ý định truy vấn gốc. Các tổ chức nên triển khai biến đổi truy vấn tăng dần, đo lường tác động đến chất lượng truy xuất và điều chỉnh tham số dựa trên các số liệu hiệu suất đặc thù theo lĩnh vực.
Kỹ Thuật Prompt cho RAG: Tối Ưu Hóa Cung Cấp Ngữ Cảnh cho LLM (Prompt Engineering for RAG)
Sau khi các đoạn liên quan đã được truy xuất, xếp hạng lại và tổng hợp, cơ hội tối ưu hóa cuối cùng — thường bị đánh giá thấp — nằm ở cách ngữ cảnh đó được cấu trúc và cung cấp cho LLM thông qua prompt. Như được minh họa trong bước 5 của kiến trúc luồng dữ liệu RAG (Hình 5-2), xây dựng prompt là giai đoạn kết hợp truy vấn người dùng và dữ liệu được truy xuất thành đầu vào mà LLM sẽ suy luận. Chất lượng của việc xây dựng này trực tiếp quyết định liệu mô hình có tạo ra phản hồi có căn cứ, chính xác hay mặc định cho kiến thức tham số của nó và có nguy cơ ảo giác.
Kỹ thuật prompt RAG hiệu quả bao gồm một số kỹ thuật khác biệt vượt ra ngoài việc đơn giản nối các đoạn được truy xuất với truy vấn của người dùng. Thiết kế system prompt thiết lập khung hành vi cho LLM, xác định vai trò của nó, ngữ cảnh lĩnh vực mà nó nên giả định và các hướng dẫn rõ ràng để ưu tiên thông tin được truy xuất hơn dữ liệu huấn luyện của nó. Định dạng ngữ cảnh (Context formatting) cấu trúc các đoạn được truy xuất theo cách LLM có thể phân tích hiệu quả nhất — ví dụ, phân định rõ ràng từng nguồn với nhãn siêu dữ liệu như tiêu đề tài liệu, ngày tháng và điểm liên quan để mô hình có thể cân nhắc và gán nhận thông tin phù hợp. Tính cụ thể hướng dẫn (Instruction specificity) hướng dẫn mô hình cách xử lý xung đột giữa các nguồn được truy xuất, khi nào thừa nhận sự không chắc chắn và liệu có trích dẫn các đoạn đã thông báo cho câu trả lời của nó hay không.
Các ví dụ few-shot được nhúng trong template prompt có thể tiếp tục hiệu chỉnh hành vi mô hình bằng cách chứng minh định dạng dự kiến và phong cách suy luận cho các phản hồi đặc thù theo lĩnh vực.
Trong các triển khai RAG doanh nghiệp, kỹ thuật prompt mở rộng đến việc tập hợp prompt động, trong đó template prompt tự thích nghi dựa trên đặc điểm truy vấn. Một tra cứu thực tế đơn giản có thể yêu cầu hướng dẫn hệ thống ngắn gọn và một đoạn được truy xuất duy nhất, trong khi một câu hỏi phân tích phức tạp có thể đòi hỏi một prompt phức tạp hơn bao gồm nhiều nguồn, hướng dẫn rõ ràng để tổng hợp và so sánh, và thuật ngữ hoặc ngữ cảnh từ điển đặc thù theo lĩnh vực. Các tổ chức nên coi kỹ thuật prompt như một ngành tối ưu hóa liên tục thay vì cấu hình một lần, thiết lập phiên bản prompt và các khung A/B testing đánh giá có hệ thống cách các thay đổi đối với hướng dẫn hệ thống, định dạng ngữ cảnh và ví dụ few-shot ảnh hưởng đến độ chính xác truy xuất và chất lượng phản hồi.
Hệ thống Telco-RAG được thảo luận trước đó trong chương này minh họa nguyên tắc này thông qua các prompt được tăng cường từ điển, tiêm các định nghĩa thuật ngữ đặc thù theo lĩnh vực vào template prompt để giúp LLM diễn giải và tạo phản hồi chính xác bằng cách sử dụng từ vựng chuyên biệt. Bằng cách coi prompt như một thành phần được thiết kế của pipeline RAG, tùy thuộc vào sự nghiêm ngặt tương tự như chiến lược phân đoạn hoặc lựa chọn mô hình embedding, các tổ chức có thể khai thác nhiều giá trị hơn đáng kể từ cơ sở hạ tầng truy xuất hiện có mà không cần đầu tư thêm vào chuẩn bị dữ liệu hoặc nâng cấp mô hình.
Hiệu Quả Dữ Liệu và Tối Ưu Hóa Chi Phí (Data Efficiency and Cost Optimization)
Tối ưu hóa các hệ thống RAG đòi hỏi cân bằng cẩn thận các đánh đổi giữa độ sâu truy xuất, yêu cầu chất lượng dữ liệu và chi phí vận hành. Bảng 5-13 minh họa cách các chiến lược truy xuất khác nhau tác động đến các chiều này, từ các phương pháp top-1 tối thiểu lý tưởng cho các tra cứu đơn giản đến các chiến lược thích ứng điều chỉnh linh hoạt dựa trên độ phức tạp truy vấn.
Bảng 5-13. Cân bằng số lượng dữ liệu so với chất lượng trong truy xuất
| Chiến lược truy xuất | Khối lượng dữ liệu | Tập trung chất lượng | Chi phí API | Độ trễ | Phù hợp nhất |
|---|---|---|---|---|---|
| Truy xuất top-1 | Tối thiểu | Phải hoàn hảo | Thấp nhất | Nhanh nhất | Tra cứu đơn giản |
| Truy xuất top-3 | Thấp | Cần độ chính xác cao | Thấp | Nhanh | RAG tiêu chuẩn |
| Truy xuất top-5 | Trung bình | Độ chính xác tốt | Trung bình | Trung bình | Truy vấn phức tạp |
| Truy xuất top-10 | Cao | Ưu tiên phạm vi bao phủ | Cao | Chậm hơn | Nghiên cứu, phân tích |
| Thích ứng (1–10) | Thay đổi | Phụ thuộc ngữ cảnh | Thay đổi | Thay đổi | Hệ thống hướng đến người dùng |
Chiến Lược Bộ Nhớ Đệm Dữ Liệu (Data Caching Strategies)
Các cơ chế bộ nhớ đệm có thể cải thiện đáng kể hiệu suất và giảm chi phí. Nghiên cứu trên nhiều khung bộ nhớ đệm ngữ nghĩa đã cho thấy bộ nhớ đệm có thể giảm độ trễ truy vấn từ 40–50% và cắt giảm các lệnh gọi LLM API thừa gần 70% trong các hệ thống có mô hình truy vấn lặp đi lặp lại, với tỷ lệ cache hit dao động từ 18–60% tùy thuộc vào sự đa dạng truy vấn và lĩnh vực.
Ở cấp độ đơn giản nhất, nhiều dịch vụ cơ sở tri thức và cơ sở dữ liệu vector được quản lý bao gồm bộ nhớ đệm kết quả truy vấn tích hợp như một tính năng nền tảng. Amazon Bedrock Knowledge Bases, ví dụ, lưu vào bộ nhớ đệm các kết quả truy xuất được truy cập thường xuyên trong cơ sở hạ tầng được quản lý của nó, không yêu cầu cấu hình bổ sung ngoài việc bật tính năng. Pinecone, Weaviate và các dịch vụ cơ sở dữ liệu vector được quản lý khác tương tự duy trì các lớp bộ nhớ đệm nội bộ lưu trữ các vector hot và kết quả truy vấn được yêu cầu thường xuyên trong bộ nhớ, xử lý tự động việc vô hiệu hóa bộ nhớ đệm và độ tươi khi chỉ mục cơ bản được cập nhật. Đối với các tổ chức sử dụng các dịch vụ được quản lý này, bộ nhớ đệm phần lớn là minh bạch; nền tảng xử lý nó như một phần của dịch vụ.
Khi khối lượng công việc vượt quá khả năng bộ nhớ đệm nền tảng tích hợp có thể xử lý hoặc khi các tổ chức yêu cầu kiểm soát chi tiết hơn đối với hành vi bộ nhớ đệm, cơ sở hạ tầng bộ nhớ đệm bên ngoài trở nên cần thiết. Amazon ElastiCache (Redis hoặc Memcached), Redis Enterprise hoặc các kho dữ liệu trong bộ nhớ tương tự có thể được triển khai như một lớp bộ nhớ đệm chuyên dụng giữa ứng dụng và cơ sở dữ liệu vector. Trong kiến trúc này, ứng dụng đầu tiên kiểm tra bộ nhớ đệm để tìm truy vấn khớp hoặc tương tự ngữ nghĩa trước khi thực hiện tìm kiếm vector đầy đủ. Phương pháp này đặc biệt hiệu quả cho các triển khai doanh nghiệp nơi hàng nghìn người dùng có thể hỏi các biến thể của cùng một câu hỏi. Chatbot tuân thủ của một công ty dịch vụ tài chính, ví dụ, sẽ nhận được các câu hỏi quy định có cấu trúc tương tự lặp đi lặp lại, khiến tỷ lệ cache hit đặc biệt cao.
Triển khai tinh vi nhất là bộ nhớ đệm ngữ nghĩa (semantic caching), vượt ra ngoài khớp truy vấn chính xác để nhận ra rằng các câu hỏi được diễn đạt khác nhau có thể tìm kiếm cùng một thông tin. Bộ nhớ đệm ngữ nghĩa sử dụng locality-sensitive hashing (LSH) hoặc so sánh embedding nhẹ để xác định liệu truy vấn đến có đủ tương tự với truy vấn/kết quả đã lưu vào bộ nhớ đệm trước đó hay không, cho phép tái sử dụng kết quả đã lưu và giảm đáng kể các lệnh gọi cơ sở dữ liệu vector tốn kém.
Chỉ Mục Vector trong Sản Xuất (Vector Indexes for Production)
Trong các triển khai cơ sở dữ liệu vector sản xuất, ba loại chỉ mục phục vụ các mục đích bổ sung nhau:
Chỉ mục vector cho tương tự ngữ nghĩa (Vector indexes for semantic data similarity): Các phương pháp dựa trên đồ thị như HNSW cung cấp thu hồi xuất sắc (95–99%) và thời gian truy vấn nhanh, làm cho chúng lý tưởng cho các ứng dụng tìm kiếm ngữ nghĩa.
Chỉ mục B-tree truyền thống cho lọc siêu dữ liệu (Traditional B-tree indexes for metadata filtering): Cho phép lọc hiệu quả trên các thuộc tính có cấu trúc như dấu thời gian, danh mục và ID người dùng.
Truy vấn kết hợp (Combined queries): Hệ thống có thể thực thi tìm kiếm tương tự vector cùng với bộ lọc siêu dữ liệu, giảm đáng kể tập ứng viên trước khi thực hiện các thao tác ANN tốn kém.
Trong bối cảnh cơ sở dữ liệu vector sản xuất, các cơ chế bộ nhớ đệm cung cấp cải thiện hiệu suất đáng kể:
- Bộ nhớ đệm kết quả truy vấn (Query result caching) lưu trữ kết quả cho các truy vấn thường xuyên, đạt được giảm độ trễ đáng kể trong các hệ thống có mô hình truy vấn lặp đi lặp lại.
- Bộ nhớ đệm dữ liệu hot (Hot data caching) xảy ra khi các vector được truy cập thường xuyên ở lại trong bộ nhớ, trong khi dữ liệu cold nằm trên bộ lưu trữ đĩa.
- Bộ nhớ đệm ngữ nghĩa (Semantic caching) sử dụng LSH để cho phép các truy vấn tương tự tái sử dụng kết quả đã lưu vào bộ nhớ đệm, giảm các lệnh gọi cơ sở dữ liệu vector tốn kém.
Phân Vùng Dữ Liệu cho Quy Mô (Data Partitioning for Scale)
Các chiến lược phân vùng hiệu quả cho phép cơ sở dữ liệu vector xử lý các tập dữ liệu quy mô petabyte trong khi duy trì hiệu suất truy vấn dưới giây:
- Sharding ngang (Horizontal sharding) phân phối các vector trên nhiều node, cho phép thực thi truy vấn song song.
- Phân vùng dựa trên siêu dữ liệu (Metadata-based partitioning) định tuyến truy vấn theo tenant, danh mục hoặc ranh giới thời gian để giảm không gian tìm kiếm.
- Lưu trữ phân cấp (Hierarchical storage) duy trì dữ liệu hot trên SSD với dữ liệu cold trên đĩa, sử dụng bộ nhớ đệm thông minh để hiện thực hóa các vector được truy cập thường xuyên.
Giám Sát Chất Lượng Dữ Liệu trong Sản Xuất (Data Quality Monitoring in Production)
Các hệ thống cơ sở dữ liệu vector sản xuất yêu cầu giám sát toàn diện để duy trì hiệu suất và độ chính xác. Không giống như các cơ sở dữ liệu truyền thống nơi tính đúng đắn truy vấn là nhị phân — kết quả khớp hoặc không — chất lượng cơ sở dữ liệu vector giảm dần khi embeddings trôi dạt, chỉ mục phân mảnh và dữ liệu nguồn phát triển. Không có giám sát liên tục, độ chính xác truy xuất có thể xói mòn âm thầm, khiến hệ thống RAG trả về các kết quả ngày càng không liên quan trong khi vẫn có vẻ hoạt động bình thường. Bảng 5-14 xác định năm chỉ số quan trọng mà các nhóm vận hành nên theo dõi trong các triển khai cơ sở dữ liệu vector sản xuất, cùng với các ngưỡng mục tiêu và các kích hoạt hành động cho biết khi nào cần can thiệp.
Bảng 5-14. Các chỉ số dữ liệu quan trọng cho cơ sở dữ liệu vector
| Chỉ số | Đo lường gì | Mục tiêu | Ngưỡng hành động |
|---|---|---|---|
| Độ chính xác truy xuất (Retrieval precision) | % kết quả liên quan trong top k | >80% | <70%, điều tra |
| Thu hồi truy xuất (Retrieval recall) | % tài liệu liên quan được truy xuất | >90% | <80%, xem xét lại chỉ mục |
| Độ trễ truy vấn (Query latency) | Thời gian phản hồi (p95) | <100 ms | >200 ms, tối ưu hóa |
| Độ tươi dữ liệu (Data freshness) | Thời gian kể từ lần cập nhật cuối | <1 giờ | >24 giờ, làm mới |
| Chất lượng chỉ mục (Index quality) | Tỷ lệ % láng giềng gần nhất thực sự được ANN trả về so với tìm kiếm brute-force chính xác | >95% recall@10 | <90%, xây dựng lại chỉ mục |
Phát Hiện Độ Trôi Dữ Liệu (Data Drift Detection)
Giám sát liên tục không gian embedding ngăn chặn sự giảm hiệu suất theo thời gian. Kỷ luật giám sát cốt lõi bao gồm theo dõi các thay đổi phân phối dữ liệu bằng cách đo độ dịch chuyển centroid và phương sai độ tương tự cosine trong không gian embedding. Các chỉ số này tiết lộ khi nào các mối quan hệ ngữ nghĩa được mã hóa trong các embeddings hiện có bắt đầu phân kỳ khỏi ý nghĩa hiện tại của nội dung cơ bản — một sự thay đổi có thể xảy ra dần dần khi các tài liệu mới được nhập hoặc khi dữ liệu nguồn phát triển, hoặc đột ngột khi các cập nhật mô hình embedding thay đổi cách văn bản được biểu diễn về mặt toán học.
Các hệ thống cảnh báo tự động nên kích hoạt khi độ trôi vượt quá các ngưỡng được xác định trước, báo hiệu nhu cầu tiềm năng cho việc tái lập chỉ mục hoặc căn chỉnh mô hình. Khi các mô hình dữ liệu phát triển đáng kể vượt quá khả năng bù trừ độ trôi, các hệ thống phải bắt đầu tái tạo embedding để duy trì chất lượng truy xuất.
Tái lập chỉ mục không phải là thao tác tầm thường. Đối với các doanh nghiệp có danh mục nội dung lớn chứa hàng chục triệu tài liệu, việc tái tạo embeddings có thể mất hàng ngày đến hàng tuần và phát sinh chi phí đáng kể trong các lệnh gọi API embedding. Các bộ test đặc thù theo lĩnh vực cung cấp mạng lưới an toàn để xác nhận các thay đổi embedding trước khi triển khai sản xuất, so sánh độ chính xác, thu hồi và các chỉ số độ trễ giữa các mô hình embedding cũ và mới để xác nhận ngang bằng hiệu suất hoặc cải thiện trước khi di chuyển lưu lượng hoàn toàn.
Luồng Dữ Liệu Đầu Cuối: KB + Cơ Sở Dữ Liệu Vector + RAG (End-to-End Data Flow: KB + Vector DB + RAG)
Hình 5-3 mang lại toàn bộ vòng đời dữ liệu trong các hệ thống GenAI sản xuất, từ nhập liệu cơ sở tri thức qua biến đổi dữ liệu và truy xuất đến tạo sinh và phản hồi liên tục.
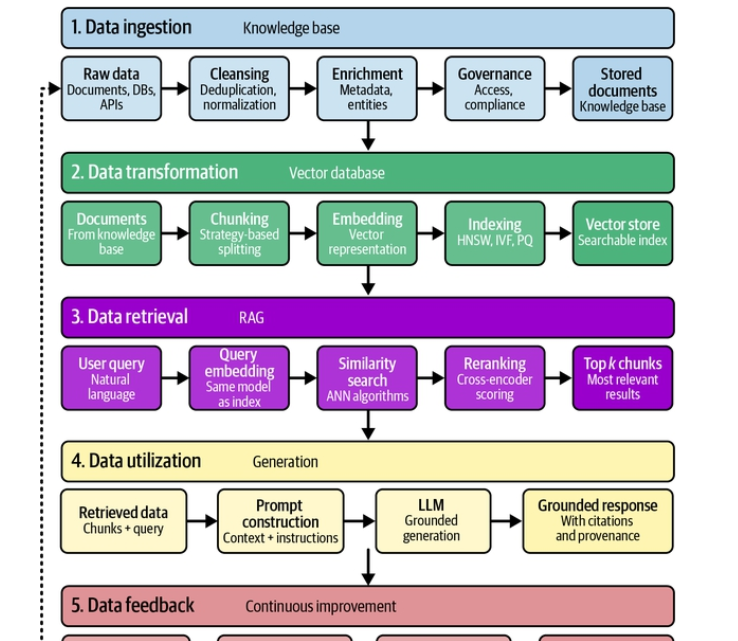
Vòng đời này bao gồm năm giai đoạn tích hợp: (1) Nhập liệu dữ liệu — làm sạch, xóa trùng và làm phong phú dữ liệu thô trước khi lưu trữ vào cơ sở tri thức; (2) Biến đổi dữ liệu — phân đoạn tài liệu, tạo vector embedding và lập chỉ mục vào cơ sở dữ liệu vector; (3) Truy xuất dữ liệu — xử lý truy vấn người dùng, tìm kiếm tương tự ANN, xếp hạng lại và chọn top k đoạn; (4) Sử dụng dữ liệu — xây dựng prompt, tạo sinh LLM và phản hồi có căn cứ với trích dẫn; (5) Phản hồi dữ liệu — cải tiến liên tục dựa trên chất lượng phản hồi và phản hồi người dùng.
Triển Khai Đa Phương Thức Nâng Cao (Advanced Multimodal Implementations)
Các hệ thống RAG hiện đại mở rộng ra ngoài văn bản để xử lý các loại dữ liệu đa dạng, xử lý các loại nội dung khác nhau thông qua các đường ống chuyên biệt trong pipeline đa phương thức. Quy trình này tuân theo quy trình embedding và phân đoạn tiêu chuẩn cho tìm kiếm ngữ nghĩa, trong khi xử lý bảng yêu cầu các quy trình trích xuất và phân đoạn chuyên biệt bảo toàn nội dung với siêu dữ liệu vị trí để duy trì mối quan hệ hàng/cột. Xử lý hình ảnh tận dụng các mô hình ngôn ngữ-thị giác để tạo ra các mô tả có thể tìm kiếm từ hình ảnh, chuyển đổi nội dung trực quan thành các biểu diễn văn bản có thể nhúng cùng với các tài liệu văn bản thông thường. Truy xuất đa phương thức (Cross-modal retrieval) cho phép kết nối giữa các loại nội dung khác nhau trong một không gian vector chung, cho phép một truy vấn ngôn ngữ tự nhiên duy nhất bề mặt các kết quả có liên quan trên các tài liệu văn bản, hình ảnh, bảng và sơ đồ đồng thời.
Xử lý video và âm thanh đại diện cho biên giới tiếp theo của RAG đa phương thức, đặc biệt cho các công ty truyền thông nơi các danh mục nội dung rộng lớn của phát sóng lưu trữ, bài thuyết trình được ghi âm hoặc phỏng vấn được phiên âm chứa tri thức thể chế phong phú trước đây không thể tìm kiếm được. Nền tảng phát trực tuyến, ví dụ, có thể xây dựng các hệ thống đề xuất có căn cứ trong nội dung ngữ nghĩa thực sự của thư viện của nó thay vì phân loại thể loại bề mặt. Các tổ chức này ngày càng triển khai các đường ống chuyển đổi speech-to-text kết hợp với phân chia người nói và phát hiện cảnh để biến đổi nội dung video/âm thanh lưu trữ thành tài sản tri thức được phân đoạn, nhúng và có thể truy xuất.
Đồng Bộ Hóa Dữ Liệu Thời Gian Thực (Real-Time Data Synchronization)
Các hệ thống sản xuất yêu cầu cập nhật dữ liệu liên tục để duy trì độ chính xác. Cơ sở dữ liệu vector yêu cầu cập nhật tăng dần mà không cần xây dựng lại chỉ mục hoàn toàn, hỗ trợ các cơ sở tri thức động phát triển cùng với thông tin tổ chức. Điều này bao gồm các kỹ thuật hiệu quả để nhập thông tin tăng dần nhanh chóng trong khi duy trì hiệu suất truy vấn dưới giây.
Các khung quản trị dữ liệu trong sản xuất mang lại các lợi ích vận hành có thể đo lường bao gồm giảm thời gian dành cho báo cáo tuân thủ, tăng độ tin cậy mô hình AI thông qua các tập dữ liệu được chứng nhận chất lượng cao và giảm ảo giác thông qua lựa chọn và lọc dữ liệu nghiêm ngặt.
Lựa Chọn Cơ Sở Hạ Tầng Phù Hợp với Quy Mô (Infrastructure Selection)
Lựa chọn cơ sở hạ tầng cuối cùng phải phù hợp với nhu cầu tổ chức trên toàn phổ quy mô dữ liệu. Các tổ chức nhỏ có thể đạt được hiệu suất hiệu quả về chi phí với các tùy chọn như Milvus hoặc Qdrant, trong khi những tổ chức hoạt động ở 100 triệu vector nên xem xét các nền tảng thương mại như Pinecone. Các doanh nghiệp quản lý hơn 1 tỷ vector yêu cầu các giải pháp mục đích xây dựng như Milvus hoặc Pinecone có thể duy trì hiệu suất truy vấn dưới giây qua khối lượng công việc cao ở quy mô. Như đã thảo luận trong phần "Lựa Chọn Dựa Trên Yêu Cầu Dữ Liệu", quy mô dữ liệu chỉ là một chiều của lựa chọn cơ sở hạ tầng; độ phức tạp truy vấn, tích hợp cơ sở hạ tầng hiện có và các ràng buộc ngân sách đều định hình lựa chọn cuối cùng, và lựa chọn phù hợp cho môi trường phát triển có thể khác đáng kể so với lựa chọn phù hợp cho triển khai sản xuất.
Tóm Tắt (Summary)
Chương này là hành trình toàn diện qua cơ sở hạ tầng dữ liệu cung cấp năng lượng cho các ứng dụng GenAI hiện đại. Chúng ta bắt đầu bằng cách kiểm tra thách thức dữ liệu GenAI và khám phá cách các yêu cầu cơ sở tri thức AI khác biệt cơ bản so với các cơ sở dữ liệu truyền thống — nghiên cứu McKinsey 2024 cho thấy 42% doanh nghiệp triển khai GenAI trích dẫn chất lượng dữ liệu kém là trở ngại hàng đầu, nhấn mạnh rằng nền tảng dữ liệu quyết định kết quả AI.
Thông qua phân tích chi tiết các giải pháp cơ sở dữ liệu vector, từ các tùy chọn mã nguồn mở như Milvus và Qdrant đến các nền tảng thương mại như Pinecone hoặc Weaviate, chúng ta đã xác lập rằng việc chọn đúng cơ sở dữ liệu vector đòi hỏi cân bằng các yêu cầu hiệu suất phù hợp, quy mô dữ liệu và các mô hình chi phí. Chỉ các cơ sở dữ liệu vector được xây dựng có mục đích mới có thể cung cấp bộ máy truy vấn mà các hệ thống sản xuất yêu cầu để duy trì hiệu suất truy vấn dưới giây trong khi xử lý hàng tỷ vector, bao gồm các chiến lược lập chỉ mục lai, bộ nhớ đệm thông minh, lọc siêu dữ liệu và giám sát mạnh mẽ.
Phần "Luồng Dữ Liệu Đầu Cuối: KB + Cơ Sở Dữ Liệu Vector + RAG" mang lại toàn bộ vòng đời dữ liệu, từ nhập liệu cơ sở tri thức qua nhúng vector đến tạo sinh có RAG, cho thấy qua các câu chuyện thành công cụ thể từ JPMorgan, NatWest và Goldman Sachs rằng các tổ chức đang đạt được cải thiện năng suất 20–90% thông qua các triển khai AI lấy dữ liệu làm trung tâm.
Thông điệp trung tâm xuyên suốt chương này vẫn rõ ràng: trong kỷ nguyên GenAI, lợi thế cạnh tranh quyết định nằm ở chuẩn bị dữ liệu, chất lượng, quản trị và cơ sở hạ tầng, không phải ở việc theo đuổi các mô hình mới nhất. Các tổ chức đầu tư có hệ thống vào kiến trúc cơ sở tri thức, chất lượng dữ liệu, cơ sở hạ tầng vector chuyên biệt và tối ưu hóa liên tục tạo ra các hệ thống không chỉ cung cấp các bản demo ấn tượng mà còn là giá trị kinh doanh có thể đo lường biến đổi cách thức hoạt động và cạnh tranh của các tổ chức.
Chương 6. Tối Ưu Hóa Ứng Dụng AI cho Sẵn Sàng Sản Xuất (AI Application Optimization for Production Readiness)
Khoảng cách giữa một nguyên mẫu AI hoạt động tốt và một hệ thống sẵn sàng đưa vào sản xuất rộng hơn nhiều so với những gì hầu hết các chuyên gia lường trước. Các giải pháp hoạt động xuất sắc trong môi trường phát triển thường vấp ngã khi đối mặt với quy mô, độ phức tạp và tính khó đoán định của vận hành thực tế. Những mô hình tạo ra bản demo ấn tượng có thể vật lộn với dữ liệu doanh nghiệp nhiễu. Các tác nhân phản hồi xuất sắc với prompt kiểm thử được chọn lọc kỹ có thể sụp đổ dưới sức nặng của codebase hàng triệu token. Các hệ thống trông có vẻ vững chắc khi hoạt động độc lập có thể trở nên bất khả thi để giám sát, bảo mật hoặc mở rộng khi triển khai trên toàn tổ chức.
Chương này tồn tại để thu hẹp khoảng cách đó.
Hành Trình từ Nguyên Mẫu đến Sản Xuất (The Journey from Prototype to Production)
Xây dựng một ứng dụng AI chỉ là bước khởi đầu. Hành trình từ nguyên mẫu đến sản xuất đòi hỏi sự phối hợp cẩn thận của nhiều chiến lược tối ưu hóa—nâng cao chất lượng và độ chính xác của phản hồi, đáp ứng các yêu cầu hiệu năng nghiêm ngặt, giảm chi phí vận hành và đơn giản hóa độ phức tạp của hệ thống. Thành công trong nỗ lực này không đạt được thông qua một kỹ thuật đơn lẻ hay giải pháp thần kỳ nào. Thay vào đó, nó đòi hỏi một cách tiếp cận toàn diện được xây dựng trên một sự thật nền tảng: dữ liệu của bạn là mạch máu của ứng dụng AI.
Mặc dù mọi chuyên gia đều đồng ý rằng chất lượng dữ liệu thúc đẩy hiệu năng AI, nhưng ít người có thể nói rõ chính xác cách chuẩn bị dữ liệu đó để đạt kết quả tốt nhất. Khoảng cách giữa biết và làm chính là nơi hầu hết các dự án AI vấp ngã. Bí quyết không nằm ở các thuật toán phức tạp hay các mô hình tiên tiến mà ở cách bạn tiếp cận chiến lược việc chuẩn bị dữ liệu—kiến tạo nền móng trước khi xây ngôi nhà.
Xuyên suốt chương này, chúng tôi sẽ trang bị cho bạn các chiến lược, mẫu thiết kế và hướng dẫn thực tế cần thiết để biến ứng dụng AI của bạn từ một thử nghiệm đầy hứa hẹn thành một hệ thống cấp doanh nghiệp. Hành trình của chúng ta đi qua năm giai đoạn liên kết với nhau.
Thứ nhất, chúng ta thiết lập nền tảng đánh giá chất lượng dữ liệu và tiền xử lý. Bạn sẽ học lý do tại sao các kết quả kinh doanh phải thúc đẩy các yêu cầu chất lượng dữ liệu, cách đón nhận tính linh hoạt thay vì các lược đồ cứng nhắc, và cách thiết kế dữ liệu mô-đun có thể tối ưu hóa cả hiệu quả lưu trữ lẫn hiệu năng truy vấn. Qua các ví dụ cụ thể, chúng ta chứng minh rằng cùng một dữ liệu có thể phục vụ các mục đích hoàn toàn khác nhau tùy thuộc vào cách chuẩn bị.
Thứ hai, chúng ta giải quyết thách thức quản lý ngữ cảnh ở quy mô lớn. Khi cửa sổ ngữ cảnh (context window) đã mở rộng từ hàng nghìn đến hàng triệu token, các chiến lược mới đã xuất hiện để xử lý đầu vào lớn mà không hy sinh chất lượng đầu ra. Chúng ta giới thiệu quy trình ba bước có hệ thống—phân đoạn (segmentation), suy luận từng đoạn (segment inference) và tổ chức (organization)—cho phép các ứng dụng của bạn lý luận trên các tập dữ liệu mà nếu không có thì sẽ áp đảo khả năng của mô hình.
Thứ ba, chúng ta khám phá ranh giới của lý luận tự động (automated reasoning). Từ các trigger dựa trên token đến các mẫu kiến trúc như chain-of-thought, tree-of-thought và graph-of-thought, chúng ta xem xét cách khai thác khả năng lý luận của các mô hình nền tảng hiện đại. Bạn sẽ học khi nào token lý luận tạo ra giá trị, khi nào chúng gây ra chi phí không cần thiết, và cách hiệu chỉnh các khả năng này cho các trường hợp sử dụng cụ thể của mình.
Thứ tư, chúng ta giới thiệu một cách tiếp cận mang tính chuyển đổi trong quản lý dữ liệu doanh nghiệp: lớp metadata ngữ nghĩa thông minh (intelligent semantic metadata layer). Khi các tổ chức vật lộn với petabyte dữ liệu phi cấu trúc—tài liệu, hình ảnh, tệp kế thừa và các định dạng chuyên biệt—các phương pháp truy xuất truyền thống không còn đáp ứng được. Chúng ta trình bày một mẫu thiết kế xây dựng trên công nghệ đồ thị tri thức (knowledge graph) cho phép các tác nhân AI khám phá, diễn giải và lý luận trên nội dung doanh nghiệp ở quy mô lớn, mà không cần di chuyển dữ liệu toàn bộ hay từ bỏ cơ sở hạ tầng hiện có.
Cuối cùng, chúng ta đề cập đến thực tế vận hành của việc triển khai tác nhân AI trong môi trường sản xuất. Độ chính xác một mình không đảm bảo thành công. Chúng ta cung cấp một khung toàn diện để đánh giá các khả năng mà ứng dụng của bạn cần, từ tùy chọn runtime lõi và triển khai đến bảo mật, khả năng quan sát (observability) và điều phối đa tác nhân (multi-agent orchestration). Chúng ta kết thúc với phân tích so sánh các nền tảng tác nhân AI hàng đầu, cung cấp hướng dẫn chọn lựa cơ sở hạ tầng phù hợp nhất với yêu cầu tổ chức của bạn.
Các kỹ thuật được trình bày ở đây không phải là các khái niệm lý thuyết mà là các phương pháp thực tế đã được chứng minh trong môi trường sản xuất. Chúng phản ánh những bài học rút ra từ các triển khai thực tế—từ các nhà sản xuất bán dẫn quản lý hàng nghìn tỷ tệp tích lũy qua nhiều thập kỷ đến các công ty thiết bị y tế điều hướng các yêu cầu quy định phức tạp.
Dù bạn đang chuẩn bị ứng dụng AI đầu tiên cho môi trường sản xuất hay tối ưu hóa một hệ thống hiện có để có quy mô và độ tin cậy lớn hơn, chương này cung cấp bản thiết kế bạn cần. Con đường từ nguyên mẫu đến sản xuất đòi hỏi nhiều nỗ lực, nhưng với các chiến lược đúng đắn, nó hoàn toàn có thể đạt được.
Hãy bắt đầu.
Chuẩn Bị Ứng Dụng AI của Bạn cho Thành Công Sản Xuất (Preparing Your AI Application for Production Success)
Hầu hết các sáng kiến AI không thất bại vì thiếu mô hình tinh vi mà trong không gian bất ổn giữa ý định và thực thi, nơi dữ liệu không được chuẩn bị với đủ sự cẩn thận chiến lược. Hãy xem việc chuẩn bị dữ liệu như việc đặt móng kết cấu của một tòa nhà: nếu bạn vội vàng với phần móng, không có gì bạn xây dựng phía trên sẽ đứng vững lâu dài. Làm đúng điều này, và mọi thứ khác sẽ theo sau. Vậy làm thế nào để bạn xây dựng một chiến lược dữ liệu thắng lợi? Câu trả lời nằm ở hai trụ cột nền tảng mà chúng ta sẽ khám phá tiếp theo.
Hai Trụ Cột của Tối Ưu Hóa AI (The Twin Pillars of AI Optimization)
Chiến lược chuẩn bị dữ liệu của bạn phải được dẫn dắt bởi hai yếu tố không thể tách rời:
- Kết quả kinh doanh mong muốn của bạn. Mục tiêu cụ thể nào ứng dụng AI của bạn phải đạt được để tạo ra giá trị?
- Mức độ sẵn sàng dữ liệu của bạn. Trạng thái hiện tại của cơ sở hạ tầng dữ liệu, chất lượng và khả năng truy cập của bạn là gì?
Hai yếu tố này có mối liên hệ nội tại và không thể được giải quyết riêng lẻ. Không giống như các phương pháp quản lý dữ liệu truyền thống, nơi bạn có thể triển khai một giải pháp phổ quát—chẳng hạn một lược đồ hình sao chuẩn (canonical star schema) trong kho dữ liệu cho dữ liệu quan hệ phục vụ nhiều trường hợp sử dụng—các ứng dụng AI đòi hỏi một cách tiếp cận tinh tế hơn, đặc thù theo ngữ cảnh. Mô hình một kích cỡ phù hợp cho tất cả đơn giản là không áp dụng được ở đây, ít nhất là không với khả năng công nghệ hiện tại của chúng ta.
Trong các phần tiếp theo, chúng ta sẽ khám phá các kỹ thuật cụ thể, có thể hành động để chuẩn bị cơ sở hạ tầng dữ liệu của bạn nhằm tối ưu hóa hiệu năng ứng dụng AI trong khi duy trì sự phù hợp với các mục tiêu kinh doanh cụ thể của bạn. Đây không phải là các khái niệm lý thuyết mà là các phương pháp thực tế đã được chứng minh để thu hẹp khoảng cách giữa tiềm năng AI và thực tế sản xuất.
Thiết Kế Quy Trình Dữ Liệu Hiệu Quả cho Hệ Thống AI Sản Xuất (Engineering Efficient Data Workflows for Production AI Systems)
Trong phần này, bạn sẽ học cách thiết kế các quy trình dữ liệu hiệu quả cho hệ thống AI sản xuất bằng cách căn chỉnh chất lượng dữ liệu với mục tiêu kinh doanh, thiết kế các chỉ mục kho vector (vector store indexes) theo mô-đun, quản lý cửa sổ ngữ cảnh lớn và tinh chỉnh lý luận tự động cho cả hiệu năng lẫn chi phí. Hãy bắt đầu bằng cách chuyển hóa các nguyên tắc cấp cao này thành các nguyên tắc đánh giá chất lượng dữ liệu và tiền xử lý thực tế, phác thảo cách kiểm tra, làm sạch và cấu trúc dữ liệu đầu vào để nó phục vụ trung thực cho các mục tiêu AI của bạn.
Đánh Giá Chất Lượng Dữ Liệu và Các Nguyên Tắc Tiền Xử Lý Cơ Bản (Data Quality Assessment and Preprocessing Fundamentals)
Khi tối ưu hóa các ứng dụng AI, một câu hỏi quan trọng nảy sinh: Làm thế nào bạn xác định chất lượng thích hợp của dữ liệu đầu vào cho trường hợp sử dụng cụ thể của mình? Trong khi Chương 4 đề cập đến các cân nhắc chất lượng dữ liệu chung như quản lý dữ liệu nhạy cảm và định dạng dữ liệu, chương này tập trung vào một thách thức tinh tế hơn: căn chỉnh chất lượng dữ liệu với mục tiêu kinh doanh trong các hệ thống AI.
Kết quả kinh doanh thúc đẩy yêu cầu chất lượng dữ liệu
Nguyên tắc nền tảng rất đơn giản: kết quả kinh doanh mong muốn của bạn nên quyết định điều gì tạo thành "chất lượng" trong dữ liệu đầu vào của bạn. Những gì xuất hiện như nhiễu trong một ngữ cảnh có thể là thông tin thiết yếu trong ngữ cảnh khác.
Hãy xem xét email dịch vụ khách hàng sau từ công ty hư cấu TechCorp. Email thường chứa hai thành phần chính—tiêu đề (headers), được in đậm ở đây (bao gồm tên và địa chỉ email của người gửi và người nhận, dấu thời gian và dòng tiêu đề), và nội dung thư (body content, tin nhắn thực tế):
From: "Michael Chen" \<michael.chen@techcorp.com> Date: Monday, August 25, 2025 at 9:36 PM To: sarah \<sarah@mycompany.com> Cc: Subject: Resolution for Your Recent Order Issue - Order #12345
Dear Sarah,
Thank you for contacting us about the delayed delivery of your order #12345. I sincerely apologize for the inconvenience this has caused.
I've investigated your order and found that it was delayed due to a warehouse processing error. To resolve this immediately, I've:
- Expedited your order for next-day delivery at no additional cost
- Applied a $25 credit to your account for the inconvenience
- Added tracking information that you'll receive via text and email
Your order will arrive tomorrow by 6 P.M., and you'll receive tracking updates throughout the day.
If you have any other concerns or questions, please don't hesitate to reach out to me directly at this email or call our priority line at (555) 123-4567.
Thank you for your patience and for being a valued customer.
Best regards,
Michael Chen Customer Success Specialist TechCorp Solutions michael.chen@techcorp.com Direct: (555) 123-4567
Để thấy cùng một dữ liệu có thể chuyển đổi giữa tín hiệu và nhiễu như thế nào tùy thuộc vào câu hỏi bạn đặt ra, hãy đánh giá ví dụ email này qua hai góc nhìn kinh doanh khác nhau:
Kịch bản 1: Phân loại ý định (Intent classification)
Nếu mục tiêu kinh doanh của bạn là hiểu ý định khách hàng để định tuyến email đến các phòng ban thích hợp, tiêu đề email trở thành nhiễu làm giảm hiệu năng mô hình. Trong giai đoạn xử lý dữ liệu, những tiêu đề này nên được loại bỏ, cho phép mô hình nền tảng tập trung hoàn toàn vào nội dung thư, nơi ý định được thể hiện.
Kịch bản 2: Phân tích tương tác (Interaction analysis)
Ngược lại, nếu bạn cần phân tích tần suất tương tác giữa các khách hàng cụ thể (ví dụ: Sarah) và các đại diện dịch vụ (ví dụ: Michael Chen), thì các tiêu đề—đặc biệt là địa chỉ email và dấu thời gian—trở thành dữ liệu chính yếu cần quan tâm. Trong trường hợp này, nội dung thư là nhiễu cần được lọc ra.
Bản chất phụ thuộc vào nội dung của chất lượng dữ liệu thách thức các phương pháp truyền thống. Cố gắng ép buộc tính nhất quán cấu trúc vào một hệ thống với các ràng buộc chất lượng cố định có thể tích cực cản trở mục tiêu kinh doanh của bạn. Thay vào đó, quản lý dữ liệu mô-đun (modular data management) được thiết kế để cung cấp cho bạn sự linh hoạt để phản ánh các khía cạnh khác nhau của chất lượng khi các trường hợp sử dụng phát triển.
Đối với những chuyên gia quen thuộc với phân tích dữ liệu truyền thống, cách tiếp cận này có thể có vẻ phản trực giác—thậm chí là một ý tưởng lỗi thời. Tuy nhiên, một số dữ liệu có giá trị tiềm ẩn; thông tin được cho là không liên quan hôm nay có thể trở nên quan trọng khi giải quyết các thách thức kinh doanh của ngày mai.
Sự linh hoạt này đặt ra một mối lo thực tế: Bao nhiêu bản sao và phiên bản dữ liệu bạn nên duy trì? Câu trả lời nằm ở quản lý dữ liệu linh hoạt thông qua vector store. Hình 6-1 minh họa khái niệm này bằng ví dụ email dịch vụ khách hàng của chúng ta.
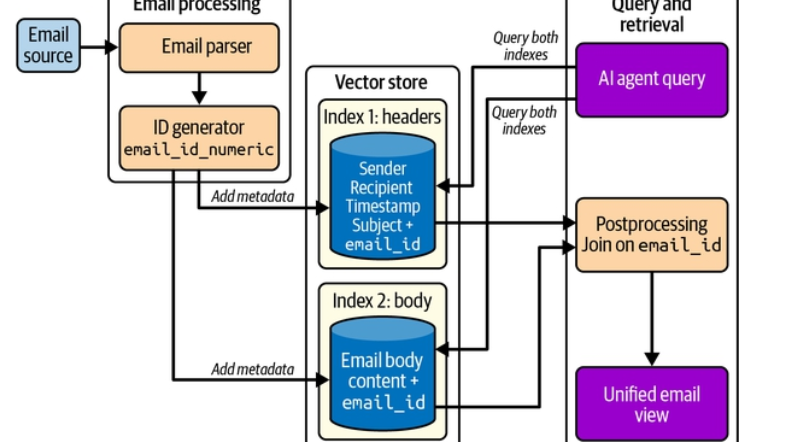
Kiến trúc này sử dụng nhiều chỉ mục trong vector store:
- Chỉ mục 1 (Index 1) chỉ chứa tiêu đề email (người gửi, người nhận, dấu thời gian, chủ đề).
- Chỉ mục 2 (Index 2) lưu trữ nội dung thư email.
Mỗi email đi qua một bước xử lý, ở đó nó được phân tích và nhận một mã định danh duy nhất (email_id_numeric) được thêm vào metadata khi các đoạn được chèn vào chỉ mục cơ sở dữ liệu vector. Cách tiếp cận này phản ánh khái niệm khóa thay thế (surrogate key) được sử dụng để nối các bảng trong kho dữ liệu truyền thống.
Nếu một trường hợp sử dụng trong tương lai yêu cầu cả hai thành phần, các tác nhân AI của bạn có thể truy vấn cả hai chỉ mục đồng thời. Các thao tác hậu xử lý sau đó có thể nối các kết quả bằng mã định danh chung, tạo ra một chế độ xem hợp nhất của toàn bộ email mà không lưu trữ các bản sao dư thừa.
Các thực hành tốt nhất cho thiết kế dữ liệu mô-đun
Nguyên tắc chính là khái niệm hóa dữ liệu của bạn như các tập hợp con mô-đun, mỗi tập chỉ chứa thông tin tối thiểu cần thiết để giải quyết các vấn đề kinh doanh cụ thể. Cách tiếp cận này cung cấp một số lợi thế:
Hiệu quả lưu trữ (Storage efficiency)
Loại bỏ lưu trữ dữ liệu dư thừa.
Hiệu năng truy vấn (Query performance)
Các chỉ mục nhỏ hơn, tập trung cải thiện tốc độ truy xuất.
Linh hoạt (Flexibility)
Các kết hợp mới có thể được tạo ra khi yêu cầu phát triển.
Bảo trì (Maintenance)
Các cập nhật chỉ ảnh hưởng đến các chỉ mục liên quan.
Tối ưu hóa chi phí (Cost optimization)
Các yêu cầu lưu trữ và xử lý được giảm thiểu.
Bằng cách áp dụng cách tiếp cận mô-đun này, bạn tạo ra một nền tảng có thể thích nghi có thể phát triển cùng với nhu cầu kinh doanh trong khi duy trì hiệu năng tối ưu và hiệu quả chi phí trong các ứng dụng AI của bạn. Bây giờ, hãy xem xét cách chuẩn bị ngữ cảnh phù hợp cho ứng dụng AI của bạn để nó có thể hoạt động tốt.
Hiểu Cửa Sổ Ngữ Cảnh và Các Tác Động của Chúng (Understanding Context Windows and Their Implications)
Kể từ khi ChatGPT ra đời vào năm 2022, kích thước cửa sổ ngữ cảnh đã tăng lên đáng kể. Trong khi mô hình GPT-3.5 khi ra mắt có độ dài ngữ cảnh tối đa là 4.096 token, tương đương khoảng 3.000 từ (một token tương đương với ba hoặc bốn ký tự, hoặc xấp xỉ ba phần tư một từ trong tiếng Anh), thì một số mô hình frontier hiện nay hỗ trợ cửa sổ ngữ cảnh lên đến 1M token. Khi các mô hình này cải thiện, mang lại hiệu năng mạnh mẽ ở kích thước ngữ cảnh lớn trong khi chi phí suy luận (inference cost) trên mỗi token dần giảm, các ứng dụng AI hiện đại ngày càng tận dụng kích thước ngữ cảnh lớn hơn. Tuy nhiên, một số lĩnh vực vẫn vượt quá các giới hạn này. Ví dụ, hãy xem xét mã hệ thống nhúng (embedded systems code) cho một công ty sản xuất chip: codebase có thể đủ lớn để yêu cầu hơn 1M-token cửa sổ ngữ cảnh, điều mà hầu hết các mô hình frontier chưa thể hỗ trợ.
Một thách thức nền tảng khi làm việc với các mô hình nền tảng nằm ở mối quan hệ giữa kích thước ngữ cảnh và chất lượng đầu ra. Các chuyên gia AI đã quan sát thấy rằng khi cửa sổ ngữ cảnh mở rộng, chúng thường đưa vào nhiễu có thể che khuất thông tin quan trọng cần thiết cho các phản hồi chính xác. Hiện tượng này đã dẫn đến việc thiết lập một thực hành tốt nhất quan trọng: tiền xử lý tích cực để loại bỏ nội dung không cần thiết trước khi suy luận mô hình.
Khi xử lý các tập dữ liệu lớn vượt quá giới hạn token của mô hình hoặc chứa nhiễu đáng kể làm giảm chất lượng đầu ra, một cách tiếp cận chiến lược trở nên thiết yếu. Giải pháp là triển khai một quy trình có hệ thống để xử lý các ngữ cảnh đầu vào lớn, đảm bảo rằng các mô hình nhận thông tin sạch, liên quan trong khi duy trì chiều sâu dữ liệu cần thiết cho các tác vụ lý luận phức tạp.
Xử Lý Ngữ Cảnh Đầu Vào Lớn (Handling Large Input Contexts)
Như được mô tả trong Hình 6-2, xử lý các ngữ cảnh đầu vào lớn là một quy trình ba bước:
1. Phân đoạn (Segmentation)
Đầu tiên, bạn phân đoạn (chunk) các đầu vào lớn thành các đoạn văn bản nhỏ hơn.
2. Suy luận từng đoạn (Segment inference)
Tiếp theo, bạn chạy suy luận trên mỗi đoạn. Điều này có thể được thực hiện song song để cải thiện hiệu năng. Ví dụ, giả sử bạn đang phân loại lịch sử tin nhắn Slack với tổng kích thước dữ liệu là 1M token. Giả sử mỗi đoạn có ngữ cảnh 100k-token, bạn có thể xử lý 10 đoạn song song, với mỗi suy luận phân loại phần văn bản của nó.
3. Tổ chức (Organization)
Cuối cùng, bạn kết hợp các đầu ra từ bước trước. Trong ví dụ Slack, các danh mục được tạo ra cho mỗi đoạn sẽ được tổng hợp bằng một quy trình combiner hoặc tác nhân hợp nhất tất cả đầu ra của các đoạn và tạo ra phản hồi cuối cùng.
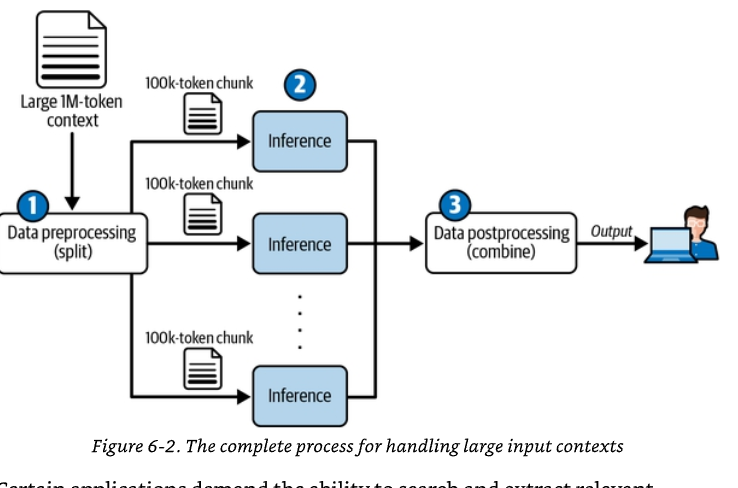
Một số ứng dụng đòi hỏi khả năng tìm kiếm và trích xuất thông tin liên quan từ các codebase lớn mà không tải code lên các hệ thống lưu trữ bên ngoài. Cách tiếp cận này phản ánh kiến trúc RAG nhưng hoạt động hoàn toàn trong pipeline xử lý, giải quyết các ràng buộc bảo mật quan trọng khi các tổ chức không thể chấp nhận rủi ro làm lộ tài sản sở hữu trí tuệ hoặc dữ liệu nhạy cảm ra các kho dữ liệu lâu dài.
Hãy xem xét thách thức khi làm việc với các codebase như những codebase được tìm thấy trong các hệ thống nhúng. Những tệp nguyên khối khổng lồ này phổ biến trong các ngành công nghiệp nơi các hệ thống kế thừa đã phát triển thành các kiến trúc phức tạp, liên kết với nhau. Khi các nhà phát triển cần sửa đổi các hàm cụ thể hoặc gỡ lỗi các đoạn code cụ thể, việc truyền toàn bộ codebase qua cửa sổ ngữ cảnh của mô hình vừa tốn kém vừa không thực tế.
Giải pháp là triển khai một tác nhân tìm kiếm chuyên biệt hoạt động theo các giai đoạn riêng biệt. Đầu tiên, nó phân đoạn codebase lớn thành các đoạn có thể quản lý và xác định các phần liên quan dựa trên truy vấn hoặc yêu cầu sửa đổi cụ thể. Một tác nhân phối hợp sau đó phân tích các đoạn được tóm tắt và trích xuất chỉ các khối code liên quan, do đó tạo ra một ngữ cảnh tập trung cho hệ thống AI chính để xử lý. Sau khi sửa đổi code liên quan, một tác nhân thứ cấp xử lý giai đoạn tích hợp, hợp nhất code đã cập nhật trở lại cấu trúc gốc trong khi thực hiện kiểm thử toàn diện ở cấp độ các thay đổi.
Phương pháp tìm kiếm trong ngữ cảnh (in-context search) này bảo tồn bảo mật dữ liệu trong khi duy trì chiều sâu phân tích cần thiết cho các sửa đổi code phức tạp. Dù làm việc với C, C++ hay assembly code, cách tiếp cận này giữ dữ liệu ở chỗ trong khi cung cấp khả năng hiểu thông minh cấp AI.
Tối Ưu Hóa Chất Lượng Suy Luận Bằng Lý Luận Tự Động (Optimizing Inference Quality Using Automated Reasoning)
Các cơ chế lý luận đại diện cho bước tiến hóa tiếp theo trong các hệ thống AI nhận thức ngữ cảnh, nơi các mô hình không chỉ xử lý thông tin mà còn tích cực lý luận qua các vấn đề bằng cách sử dụng khung ngữ cảnh mà bạn cung cấp.
Lý luận tự động (automated reasoning) đề cập đến khả năng của các hệ thống AI thực hiện suy luận logic, giải quyết vấn đề và ra quyết định thông qua các quy trình tính toán có hệ thống. Nó có thể được phân loại thành ba loại:
- Lý luận dựa trên token (Token-based reasoning)
- Lý luận kiến trúc (Architectural reasoning)
- Các mẫu xử lý (Processing patterns)
Lý luận dựa trên token (Token-based reasoning)
Lý luận dựa trên token có thể được kích hoạt hoặc dẫn dắt bởi các loại token khác nhau. Các loại này bao gồm:
Token lý luận tự động (Automated reasoning tokens)
Đây là các token hoặc cụm từ rõ ràng kích hoạt các quy trình lý luận trong các mô hình AI. Hãy nghĩ về chúng như các công tắc nhận thức cho biết mô hình cần tham gia vào quá trình suy nghĩ có chủ ý.
Ví dụ: Khi bạn bao gồm các cụm từ như "Think step by step" (Suy nghĩ từng bước) trong prompt—thường là trong system prompt—mô hình nhận ra đây là tín hiệu để phân tích vấn đề một cách có hệ thống thay vì nhảy vào kết luận:
python prompt = "Think step by step: How do we optimize database performance?"
Token lý luận đã học (Learned reasoning tokens)
Đây là các token mà các mô hình đã học để liên kết với lý luận sâu hơn qua quá trình huấn luyện, ngay cả khi không có hướng dẫn rõ ràng.
Ví dụ: Các mô hình có thể học rằng một số loại vấn đề phức tạp tự động kích hoạt các quy trình lý luận, chẳng hạn như các bài toán tối ưu hóa đa biến hoặc câu đố logic.
Token nhạy cảm với ngữ cảnh (Context-sensitive tokens)
Các token này điều chỉnh cách tiếp cận lý luận của mô hình dựa trên ngữ cảnh và lĩnh vực cụ thể của vấn đề. Prompt và ngữ cảnh xung quanh xác định chiến lược lý luận nào được kích hoạt.
Ví dụ: Một prompt có thể báo hiệu rõ ràng cho mô hình áp dụng chế độ lý luận có cấu trúc:
```python prompt = """ Use systematic reasoning to solve this:
step_by_step Problem: {complex_problem}
""" ```
Lý luận kiến trúc (Architectural reasoning)
Có ba khung lý luận chính cấu trúc cách các mô hình ngôn ngữ giải quyết các vấn đề phức tạp: chain-of-thought (CoT), tree-of-thought (ToT) và graph-of-thought (GoT).
Chain-of-thought (Chuỗi suy nghĩ)
CoT reasoning liên quan đến việc phân tách các vấn đề phức tạp thành một chuỗi logic các bước trung gian, trong đó mỗi bước được xây dựng dựa trên bước trước. Cách tiếp cận này đặc biệt hữu ích cho các tác vụ như phân tích đa bước, giải quyết bài toán toán học và các tác vụ lý luận phức tạp khác. Tuy nhiên, nó không cần thiết cho tất cả các tác vụ và thực sự gây ra thêm chi phí, bao gồm tăng độ trễ và số lượng token đầu ra. Các tác vụ đơn giản không cần giải thích thường là các ứng cử viên kém cho CoT reasoning.
Khi giải quyết bài toán toán học bằng lời, CoT reasoning trước tiên xác định thông tin đã cho và sau đó xác định những gì cần tính toán, thiết lập công thức liên quan, thực hiện các phép tính từng bước và cuối cùng xác minh câu trả lời.
Khả năng phân bổ token cho lý luận cho phép các nhà phát triển kiểm soát độ sâu của quy trình lý luận dựa trên độ phức tạp của tác vụ, với số lượng token lý luận lớn hơn cho phép lập kế hoạch chi tiết hơn, từng bước. Dấu vết lý luận (reasoning trace) có thể hiển thị trong đầu ra của mô hình khi các token này được bật. Quan trọng là, các token lý luận được tính vào tổng giới hạn token đầu ra, vì vậy số lượng được phân bổ phải luôn thấp hơn giới hạn đó.
Đây là ví dụ không có token lý luận nào được phân bổ cho mô hình lý luận:
Prompt: I have 5 apples in a basket. I added 6 bananas to it. Then I gave away 2 apples and 3 bananas but added 7 plums. I ate 2 plums and a banana. How many total fruits are left in the basket?
Output: 10 Fruits Input- 75 tokens, Output -203 tokens, Latency-4380 ms
Lưu ý: Đầu ra của mô hình bao gồm nội dung lý luận do các khả năng lý luận học được cố hữu của nó, làm tăng số lượng token đầu ra. Để đơn giản, nội dung lý luận này đã được loại bỏ khỏi đầu ra được trình bày trong sách.
Đây là ví dụ với 1.024 token lý luận được phân bổ cho cùng mô hình lý luận:
Prompt: I have 5 apples in a basket. I added 6 bananas to it. Then I gave away 2 apples and 3 bananas but added 7 plums. I ate 2 plums and a banana. How many total fruits are left in the basket?
Output: 10 Fruits Input- 75 tokens, Output - 470 tokens, Latency-7132 ms
So sánh hai lần chạy cho thấy các tác động đáng kể: số lượng token đầu ra tăng hơn gấp đôi và tổng độ trễ gần như tăng gấp đôi, dẫn đến chi phí suy luận cao hơn đáng kể cho lần chạy thứ hai. Điều này nhấn mạnh tầm quan trọng của việc hiệu chỉnh cẩn thận việc phân bổ token lý luận. Để tránh cấp phát quá mức, bạn nên kiểm thử lặp đi lặp lại cấu hình của mình bằng cách sử dụng một mẫu prompt đại diện phản ánh các mẫu sử dụng thực tế.
Tree-of-thought (Cây suy nghĩ)
ToT reasoning sử dụng khám phá phân nhánh để đánh giá nhiều đường lý luận có thể đồng thời, như các nhánh trên cây, trước khi chọn hướng hứa hẹn nhất. Ví dụ, khi lập kế hoạch cho một dự án, ToT có thể khám phá các cách tiếp cận khác nhau (Nhánh A: phương pháp agile; Nhánh B: phương pháp waterfall; Nhánh C: mô hình hybrid), đánh giá ưu và nhược điểm của mỗi nhánh và sau đó chọn con đường tối ưu.
Graph-of-thought (Đồ thị suy nghĩ)
GoT reasoning sử dụng các mối quan hệ dựa trên mạng lưới, hình thành các mạng liên kết nơi các khái niệm và bước lý luận khác nhau có thể ảnh hưởng lẫn nhau theo những cách phức tạp. Ví dụ, trong chẩn đoán y tế, các triệu chứng, kết quả xét nghiệm, bệnh sử và các phương pháp điều trị tiềm năng tạo thành một mạng lưới trong đó mỗi yếu tố có thể ảnh hưởng đến việc diễn giải các yếu tố khác.
Lựa chọn khung lý luận (Reasoning framework selection)
Prompt của bạn rất quan trọng trong việc xác định kỹ thuật lý luận nào sẽ được sử dụng. Nếu bạn cần một kỹ thuật cụ thể, hãy chỉ định nó trong prompt:
prompt = """
Can you solve this by using the tree-of-thought technique?
Context:
Bob is in the living room.
He walks to the kitchen, carrying a cup.
He puts a ball in the cup and carries the cup to the bedroom.
He turns the cup upside down, then walks to the garden.
He puts the cup down in the garden, then walks to the garage.
Question: Where is the ball?
"""
Output:
# Tree-of-Thought Solution
I'll solve this by exploring multiple reasoning paths and evaluating them.
## Initial State Analysis
**Thought 1:** Track the ball's location through each action
**Thought 2:** Track the cup's state (upright/upside down) and contents
**Thought 3:** Identify the critical action that affects the ball
Let me explore each thought:
---
## Path 1: Direct Ball Tracking
1. **Initial**: Bob is in living room (ball location unknown initially)
2. **Kitchen**: Bob walks to kitchen with cup (no ball mentioned yet)
3. **Ball enters**: Bob puts ball IN the cup (ball is now in cup)
4. **To bedroom**: Bob carries cup to bedroom (ball still in cup)
5. **Critical action**: Bob turns cup upside down in bedroom
- **This releases the ball!** The ball falls out in the BEDROOM
6. **To garden**: Bob walks to garden (ball was left behind in bedroom)
7. **Cup down**: Bob puts cup down in garden (cup is empty)
8. **To garage**: Bob walks to garage (ball still in bedroom)
**Conclusion from Path 1: Ball is in the BEDROOM**
---
## Path 2: Cup State Tracking
- Cup starts upright → ball can stay inside
- Cup turned upside down in bedroom → ball falls out
- Cup moved to garden while upside down → already empty
- **Ball location: BEDROOM** (where it fell out)
---
## Path 3: Location Verification
Could the ball be anywhere else?
- ❌ Living room? No, ball was put in cup after leaving
- ❌ Kitchen? No, ball added here but then moved
- ✅ **Bedroom?** Yes - cup was inverted here
- ❌ Garden? No, ball already fell out before cup arrived
- ❌ Garage? No, Bob went there alone
---
## Final Answer
**The ball is in the BEDROOM.**
The critical moment was when Bob turned the cup upside down in the bedroom,
causing the ball to fall out. The cup then traveled empty to the garden and Bob
continued to the garage, but the ball remained where it fell.
Nếu không có cách tiếp cận lý luận có cấu trúc nào khác được chỉ định rõ ràng, CoT thường được sử dụng theo mặc định. Tùy thuộc vào tác vụ, vấn đề có thể được phân loại động, với prompt được điều chỉnh để tận dụng chiến lược lý luận phù hợp nhất.
Các mẫu xử lý (Processing patterns)
Ngoài các kỹ thuật cấp token và kiến trúc, nhiều mô hình lý luận hiện đại cũng dựa vào các mẫu xử lý riêng biệt—các cách có cấu trúc để tổ chức quá trình suy nghĩ của chúng theo thời gian, định hình cách chúng khám phá các tùy chọn, tinh chỉnh các câu trả lời một phần và đi đến các quyết định cuối cùng. Hãy xem xét một vài mẫu hàng đầu:
Suy nghĩ đan xen (Interleaved thinking)
Sử dụng lý luận và phản hồi xen kẽ. Mô hình luân phiên giữa lý luận nội bộ và tạo ra đầu ra, tinh chỉnh cách tiếp cận của nó khi tiến hành.
Ví dụ: Khi được giao nhiệm vụ viết báo cáo ra mắt sản phẩm phức tạp, mô hình trước tiên lập kế hoạch cấu trúc và soạn thảo phác thảo cho thị trường toàn cầu, sau đó điều chỉnh phác thảo dựa trên thông tin nhân khẩu học cho các khu vực cụ thể, và cuối cùng tiến hành tạo nội dung trong khi liên tục đánh giá và điều chỉnh cách tiếp cận của mình.
Lý luận đệ quy (Recursive reasoning)
Sử dụng phân tách vấn đề tự tham chiếu (self-referential problem decomposition). Mô hình áp dụng cùng quy trình lý luận cho các bài toán con ngày càng nhỏ hơn cho đến khi đạt được các thành phần có thể quản lý được.
Ví dụ: Khi được giao nhiệm vụ cải thiện hiệu quả hoạt động trong một công ty lớn với nhiều tầng phân cấp, mô hình trước tiên xem xét cải tiến cấp phòng ban, sau đó tối ưu hóa cấp nhóm và sau đó cải tiến quy trình riêng lẻ, áp dụng cùng khung phân tích ở mỗi cấp độ.
Lý luận đa giai đoạn (Multistage reasoning)
Sử dụng xử lý nhận thức theo lớp (layered cognitive processing). Điều này liên quan đến nhiều giai đoạn lý luận riêng biệt, mỗi giai đoạn có trọng tâm và phương pháp luận riêng.
Ví dụ: Giả sử một trợ lý AI được giao nhiệm vụ thiết kế chiến lược sao lưu tiết kiệm chi phí cho cơ sở dữ liệu sản xuất của một công ty. Mô hình chia vấn đề thành bốn giai đoạn riêng biệt:
1. Xác định vấn đề và định nghĩa phạm vi: Làm rõ vấn đề bằng cách xác định các hệ thống quan trọng, thời gian phục hồi chấp nhận được và ràng buộc ngân sách.
2. Thu thập và phân tích dữ liệu: Thu thập và phân tích thông tin về mức sử dụng lưu trữ hiện tại, tỷ lệ lỗi lịch sử và các công nghệ sao lưu có sẵn.
3. Tạo và đánh giá giải pháp: Đề xuất các chiến lược ứng cử (ví dụ: sao lưu đầy đủ hàng ngày, sao chép liên tục), so sánh độ tin cậy và chi phí của chúng, và đề xuất tùy chọn tốt nhất.
4. Lập kế hoạch triển khai và đánh giá rủi ro: Lên lịch các công việc sao lưu, xác định các cảnh báo giám sát và đánh giá các rủi ro như lỗi mạng hoặc bỏ lỡ cửa sổ sao lưu.
Mẫu lý luận mà một mô hình sử dụng thường được xác định bởi cấu trúc prompt, các tùy chọn mô hình tùy chọn và đôi khi các hướng dẫn rõ ràng của người dùng. Ví dụ sau đây minh họa cách mỗi mẫu được mô tả ở đây có thể được kích hoạt cho một câu hỏi nhất định:
Câu hỏi: Cho danh sách số [2, 3, 4, 5, 6], tìm tất cả các cặp duy nhất có tổng là số nguyên tố. Hiển thị quá trình lý luận của bạn.
# Interleaved Thinking System Prompt
interleaved_system_prompt = (
"You are an AI agent that alternates between thinking and acting."
"For each step: reason about which numbers might form pairs, simulate "
"checking their sums, observe whether the sum is prime, and repeat until all "
"pairs are considered."
"Present the answer at the end."
)
# Recursive Reasoning System Prompt
recursive_system_prompt = (
"You are an AI agent that recursively breaks problems into smaller subproblems."
"For each pair, calculate the sum, check if it is prime, and if not, move to "
"the next pair."
"Continue recursively until all pairs are tested, then list those whose sums "
"are prime."
)
# Multistage Reasoning System Prompt
multistage_system_prompt = (
"You are an AI agent that solves problems in clearly defined stages."
"Stage 1: List all possible pairs from the given numbers."
"Stage 2: For each pair, calculate their sum."
"Stage 3: Check which sums are prime numbers."
"Stage 4: Present the pairs whose sums are prime."
)
LƯU Ý
Code đầy đủ cho ví dụ này có thể tải xuống từ kho lưu trữ GitHub của sách. Nó đã được kiểm thử để hoạt động với các mô hình Amazon Bedrock, nhưng bạn có thể sửa đổi nó khi cần thiết cho mô hình bạn đang sử dụng. Lưu ý rằng không phải tất cả các mô hình đều hỗ trợ lý luận. Tham khảo thẻ mô hình hoặc tài liệu để xác định xem mô hình bạn chọn có cung cấp các khả năng này hay không.
Các khả năng lý luận tự động—dù dựa trên token, kiến trúc hay theo mẫu—tạo thành xương sống trí tuệ của việc ra quyết định AI tinh vi. Tuy nhiên, tiềm năng thực sự của chúng vẫn chưa được hiện thực hóa nếu không có quyền truy cập vào đúng dữ liệu, được cung cấp trong đúng ngữ cảnh, vào đúng thời điểm. Lý luận đơn thuần không làm cho một hệ thống AI sẵn sàng sản xuất; điều phân biệt các nguyên mẫu thử nghiệm với các giải pháp cấp doanh nghiệp là khả năng điều hướng thông minh qua các cảnh quan dữ liệu phức tạp thông qua các lớp metadata đáng tin cậy và đồ thị tri thức liên kết. Các yếu tố nền tảng này biến đổi cách các tác nhân AI khám phá, diễn giải và hành động dựa trên dữ liệu có sẵn, cho phép chúng hoạt động đáng tin cậy ở quy mô lớn trong các môi trường thực tế. Trong phần tiếp theo, chúng ta khám phá cách metadata ngữ nghĩa thông minh đóng vai trò là cầu nối quan trọng này giữa sức mạnh lý luận thô và sẵn sàng sản xuất.
Sẵn Sàng Metadata cho Hệ Thống AI Tác Nhân (Metadata Readiness for Agentic AI Systems)
Xây dựng một tác nhân AI là đơn giản. Tuy nhiên, đó chỉ là bước khởi đầu. Các tổ chức doanh nghiệp đang ngồi trên một mỏ vàng kiến thức chưa được khai thác. Như đã thảo luận trong Chương 5, các ước tính ngành cho thấy 80–90% dữ liệu doanh nghiệp tồn tại dưới dạng phi cấu trúc—tài liệu, hình ảnh, bài thuyết trình và các tệp mà các hệ thống AI truyền thống gặp khó khăn để tận dụng hiệu quả.
Các Thách Thức về Quy Mô và Độ Phức Tạp (The Challenges of Scale and Complexity)
Quy mô của thách thức này thật đáng kinh ngạc. Một doanh nghiệp điển hình quản lý từ hàng chục terabyte đến nhiều petabyte dữ liệu phi cấu trúc, phản ánh hàng thập kỷ kiến thức tổ chức tích lũy và tương đương với hàng trăm triệu—và trong một số trường hợp, hơn một nghìn tỷ (quadrillion)—tệp riêng lẻ. Đây không phải là các dự báo trừu tượng; chúng phản ánh các thực tế mà chúng tôi đã chứng kiến trực tiếp trong các ngành công nghiệp.
Trong nhiều trường hợp, kho lưu trữ khổng lồ này về trí tuệ tổ chức vẫn chưa được khai thác và chưa được chuẩn bị cho việc tiêu thụ AI.
Sự phức tạp bên trong (The complexity within)
Thách thức mở rộng ra ngoài khối lượng thuần túy. Các tệp này trải dài qua toàn bộ phổ định dạng doanh nghiệp điển hình:
- Tài liệu Office, chẳng hạn như các tệp Word (.docx), Excel (.xls), PowerPoint (.ppt)
- Định dạng di động (portable formats), chẳng hạn như PDF, tệp văn bản thuần túy và kho lưu trữ nén (.zip)
- Định dạng kế thừa và chuyên biệt, chẳng hạn như tệp kỹ thuật độc quyền và tài liệu được quét
Quan trọng hơn, nội dung trong các tệp này thường không tuân theo phân loại đơn giản. Một kho lưu trữ doanh nghiệp duy nhất có thể chứa:
- Bản phác thảo kỹ thuật vẽ tay
- Hình ảnh y tế (chụp X-quang ngực, MRI)
- Tài liệu quy trình nhà máy
- Hướng dẫn hỗ trợ
- Bảng dữ liệu phức tạp
- Ghi chú và chú thích viết tay
- Các tường thuật văn bản tiêu chuẩn
Sự đa dạng này đại diện cho thành phần thực sự của dữ liệu phi cấu trúc doanh nghiệp—và nó đặt ra một trở ngại ghê gớm cho các hệ thống AI đang cố gắng trích xuất thông tin chi tiết có thể hành động.
Tại sao các phương pháp truyền thống không đủ (Why traditional approaches fall short)
Để các tác nhân AI cung cấp giá trị kinh doanh có ý nghĩa, chúng phải hiểu không chỉ dữ liệu nào tồn tại mà còn ý nghĩa của nó trong ngữ cảnh. Các pipeline RAG truyền thống và vector store, mặc dù mạnh mẽ cho nội dung có cấu trúc tốt, vẫn gặp khó khăn trong việc cung cấp cho các tác nhân ngữ cảnh tinh tế cần thiết để trả lời các câu hỏi doanh nghiệp phức tạp. Chúng truy xuất các mảnh; chúng không hiểu các mối quan hệ.
Mô hình mới: Metadata ngữ nghĩa thông minh (A new paradigm: Intelligent semantic metadata)
Đây là nơi metadata ngữ nghĩa thông minh (intelligent semantic metadata) xuất hiện. Đó là một cách tiếp cận chuyển đổi trong quản lý dữ liệu doanh nghiệp thu hẹp khoảng cách giữa các hiện vật kỹ thuật thô và sự hiểu biết kinh doanh có ý nghĩa.
Thay vì coi metadata như một danh mục thụ động của các thuộc tính tệp, cách tiếp cận này xây dựng các lớp ý nghĩa ngữ nghĩa phong phú, liên kết với nhau cho phép các tác nhân AI:
- Khám phá dữ liệu liên quan trên các kho lưu trữ phân tán
- Diễn giải nội dung trong ngữ cảnh kinh doanh thích hợp của nó
- Lý luận về các mối quan hệ trải dài qua tài liệu, hệ thống và lĩnh vực
Lĩnh vực này vẫn đang hình thành, và mẫu thiết kế chúng ta trình bày trong phần tiếp theo được rút ra từ các thành công sớm nhưng thuyết phục mà chúng tôi đã quan sát trong các môi trường sản xuất. Những gì theo sau không phải là lý thuyết; nó được thông báo bởi triển khai thực tế và kết quả có thể đo lường được.
Mẫu Thiết Kế: Tận Dụng Tệp Thô Trực Tiếp (Pattern: Leveraging Raw Files Directly)
Nhiều trường hợp sử dụng của doanh nghiệp ưu tiên hoặc yêu cầu các khối lượng công việc AI hoạt động trực tiếp trên các tệp ở định dạng gốc của chúng, mà không cần di chuyển sang các kho lưu trữ dữ liệu chuyên biệt.
Thực tế thực địa là:
- Dữ liệu doanh nghiệp cư trú trong các định dạng gốc (PDF, CSV, tài liệu Word, kho lưu trữ nén, tệp MIME, v.v.) trên các nguồn phân tán.
- Nhúng tất cả các tệp vào vector store không phải là một tùy chọn, vì nhiều lý do khác nhau.
- Các đặc điểm tệp có xu hướng có thể quản lý được khi tách biệt—phân tích của chúng tôi tại một số tổ chức cho thấy trung bình ít hơn 20.000 token (khoảng 40 trang) mỗi tệp.
Tại sao các tổ chức chọn con đường này (Why organizations choose this path)
Khách hàng ngày càng tìm kiếm các giải pháp có thể truy vấn các tệp thô tại chỗ, mà không cần sao chép dữ liệu sang các hệ thống thứ cấp hoặc di chuyển nội dung vào cơ sở dữ liệu vector. Các động lực khác nhau, nhưng một số trong số những cái chúng tôi thường gặp nhất bao gồm:
Bảo mật và tuân thủ (Security and compliance)
Dữ liệu nhạy cảm không thể rời khỏi các môi trường được kiểm soát.
Chi phí (Cost)
Nhúng và lưu trữ hàng tỷ đến hàng nghìn tỷ vector là cực kỳ tốn kém.
Chưa được chứng minh ở quy mô lớn (Unproven at scale)
Vector store chưa phải là kho lưu trữ dữ liệu được chứng minh cho sự đa dạng và quy mô lớn này.
Đơn giản hóa hoạt động (Operational simplicity)
Tránh thêm một kho lưu trữ dữ liệu khác giảm độ phức tạp kiến trúc.
Độ tươi mới của dữ liệu (Data freshness)
Truy cập tại chỗ loại bỏ độ trễ đồng bộ hóa.
Sự xuất hiện của metadata ngữ nghĩa thông minh (The emergence of intelligent semantic metadata)
Khi các hệ thống AI tác nhân phổ biến, các tổ chức đối mặt với một yêu cầu chung: hướng dẫn các tác nhân AI điều hướng qua các cảnh quan dữ liệu phi cấu trúc rộng lớn, đi đến chính xác các tài liệu được yêu cầu và trích xuất các câu trả lời chính xác.
Yêu cầu này đã dẫn đến sự ra đời của khái niệm một lớp metadata ngữ nghĩa thông minh (intelligent semantic metadata layer)—một bản đồ phong phú, liên kết với nhau của nội dung doanh nghiệp cho các hệ thống AI biết không chỉ dữ liệu sống ở đâu mà còn nó có nghĩa gì và nó liên quan đến các tài sản tri thức khác như thế nào.
Một phép loại suy rất có tính gợi ý: giống như Hive Metastore hướng dẫn các công cụ xử lý xác định vị trí các tệp dữ liệu phù hợp trong một data lake truyền thống, một lớp metadata ngữ nghĩa thông minh hướng dẫn các tác nhân AI khám phá, diễn giải và lý luận trên nội dung phi cấu trúc ở quy mô lớn.
Hãy khám phá cách metadata ngữ nghĩa thông minh có thể biến đổi dữ liệu doanh nghiệp của bạn từ một kho lưu trữ tĩnh thành một tài sản tri thức tích cực.
Xây Dựng Tác Nhân Nhận Thức Dữ Liệu Qua Metadata Ngữ Nghĩa Thông Minh (Building Data-Aware Agents Through Intelligent Semantic Metadata)
Dù tổ chức vận hành trực tiếp trên các tệp thô hay tăng cường một cơ sở dữ liệu vector hiện có, lớp metadata ngữ nghĩa thông minh đóng vai trò là mô liên kết (connective tissue) biến các tài liệu riêng lẻ thành một đồ thị tri thức có thể điều hướng. Nó cung cấp một cách tiếp cận kiến trúc thống nhất giải quyết cả hai kiến trúc.
Được xây dựng trên công nghệ đồ thị tri thức, cách tiếp cận này tạo ra một hệ sinh thái metadata phong phú hướng dẫn tất cả các tác nhân AI và khối lượng công việc xử lý các tài liệu riêng lẻ. Khi nội dung này đi qua lớp metadata ngữ nghĩa thông minh, một ứng dụng AI có thể liên kết từng tài liệu, kết nối nó với ngữ cảnh phù hợp, và xây dựng một cấu trúc tri thức liên kết chặt chẽ từ một bộ sưu tập doanh nghiệp. Các tác nhân AI hiện tại và tương lai sau đó có thể duyệt qua đồ thị để nhanh chóng xác định tài liệu nào liên quan đến nhiệm vụ chúng đang thực hiện. Điều này được mô tả trong phần "After" của Hình 6-3.
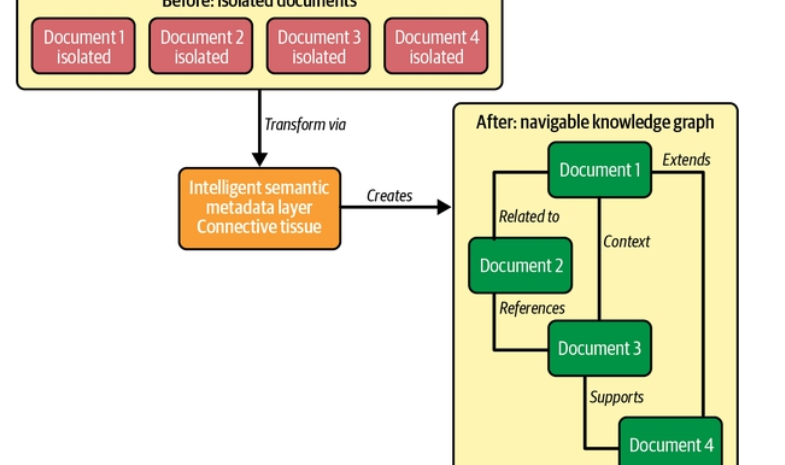
Các khả năng cốt lõi (Core capabilities)
Lớp metadata ngữ nghĩa thông minh cung cấp năm khả năng nền tảng biến đổi cách các hệ thống AI tương tác với dữ liệu doanh nghiệp:
Lập bản đồ mối quan hệ ngữ cảnh (Contextual relationship mapping)
Nắm bắt các mối quan hệ rõ ràng và ngầm định giữa tài liệu, tài sản dữ liệu và các thực thể kinh doanh, cho phép các tác nhân AI duyệt qua các kết nối thay vì tìm kiếm độc lập.
Phân loại thông minh và gắn thẻ ngữ nghĩa (Intelligent classification and semantic tagging)
Tự động phân loại nội dung bằng các mô hình phân loại nhận biết lĩnh vực, áp dụng các thẻ ngữ nghĩa phản ánh ý nghĩa kinh doanh thay vì các thuộc tính kỹ thuật.
Phân loại học kinh doanh phân cấp (Hierarchical business taxonomy)
Duy trì các phân loại học có cấu trúc phản ánh các lĩnh vực kiến thức tổ chức, phân cấp sản phẩm, khung quy định và các danh mục hoạt động.
Liên kết ngữ nghĩa được nhúng (Embedded semantic links)
Lưu trữ các kết nối ngữ nghĩa trực tiếp trong các thuộc tính node, cho phép duyệt đồ thị phong phú mà không cần suy luận runtime tốn kém.
Ánh xạ bản thể học và phả hệ nguồn (Ontology mapping and source lineage)
Căn chỉnh nội dung với các bản thể học doanh nghiệp trong khi bảo tồn phả hệ đầy đủ, ghi lại nguồn gốc dữ liệu, cách nó đã chuyển đổi và hệ thống nào vẫn là chuẩn mực. Cùng nhau, các khả năng này tạo ra một kiến trúc tri thức sống tiến hóa cùng với doanh nghiệp, thay vì một chỉ mục tĩnh suy giảm theo thời gian.
Lợi ích hiệu quả hoạt động (Operational efficiency gains)
Ngoài sự phong phú ngữ nghĩa, lớp metadata ngữ nghĩa thông minh cung cấp các lợi ích hoạt động có thể đo lường trực tiếp ảnh hưởng đến chi phí, hiệu năng và trải nghiệm người dùng. Các lợi ích này bao gồm:
Câu trả lời trực tiếp từ đồ thị (Direct graph answers)
Đối với một tập hợp con đáng kể của các truy vấn, bản thân đồ thị tri thức chứa đủ ngữ cảnh để trả về câu trả lời trực tiếp, loại bỏ hoàn toàn nhu cầu truy xuất tài liệu hạ lưu, phân đoạn hoặc xử lý LLM. Điều này làm giảm đáng kể độ trễ và chi phí tính toán cho các mẫu câu hỏi phổ biến.
Duyệt đồ thị thông minh (Intelligent graph traversal)
Đối với các truy vấn phức tạp yêu cầu tài liệu nguồn, lớp metadata cho phép duyệt chính xác đến các tài liệu liên quan hoặc, trong trường hợp các tệp lớn, đến các đoạn tài liệu cụ thể. Các tác nhân AI điều hướng các mối quan hệ ngữ nghĩa để xác định các nguồn có thẩm quyền, cải thiện cả độ chính xác lẫn khả năng giải thích.
Giảm chi phí tính toán (Reduced computational overhead)
Bằng cách lọc và nhắm mục tiêu truy xuất ở lớp metadata, các tổ chức giảm đáng kể: - Tiêu thụ token (LLM xử lý ít đoạn không liên quan hơn) - Các thao tác nhúng (vectorization chọn lọc được sử dụng, thay vì lập chỉ mục toàn diện) - Độ trễ phản hồi (định tuyến thông minh cho phép thời gian phản hồi nhanh hơn)
Mệnh đề giá trị (The value proposition)
Để tóm tắt, Bảng 6-1 so sánh các cách tiếp cận tìm kiếm dựa trên RAG truyền thống với một lớp metadata ngữ nghĩa thông minh theo một số chiều quan trọng.
Bảng 6-1. Tìm kiếm dựa trên RAG so với lớp metadata ngữ nghĩa
| Chiều | RAG truyền thống | Lớp metadata ngữ nghĩa |
|---|---|---|
| Di chuyển dữ liệu | Bắt buộc | Tùy chọn—hoạt động tại chỗ |
| Độ chính xác truy xuất | Dựa trên độ tương đồng | Duyệt nhận thức ngữ cảnh |
| Giải quyết truy vấn | Luôn yêu cầu LLM | Nhiều truy vấn được trả lời trực tiếp |
| Khả năng mở rộng | Giảm hiệu suất theo khối lượng | Duy trì độ chính xác ở quy mô |
| Khả năng giải thích | Embedding mờ đục | Phả hệ và mối quan hệ có thể truy vết |
Để làm mọi thứ cụ thể hơn, trong phần tiếp theo chúng ta sẽ xem xét một ví dụ thực tế về cách lớp metadata ngữ nghĩa thông minh hoạt động.
Ví Dụ Triển Khai: Tận Dụng Tệp Thô Trực Tiếp (Example Implementation: Leveraging Raw Files Directly)
Hãy xem xét một tình huống trong đó một tác nhân AI cần trả lời các câu hỏi liên quan đến lĩnh vực chăm sóc sức khỏe/y tế, dựa trên một kho tài liệu trải dài hàng triệu tệp. Câu hỏi người dùng ví dụ chúng ta sẽ sử dụng cho mục đích minh họa là:
CÂU HỎI: "Những loại thuốc nào được bác sĩ kê đơn, và hướng dẫn cụ thể cho từng loại là gì?"
Các bước của tác nhân AI (AI agent steps)
Tác nhân AI sử dụng metadata ngữ nghĩa làm điểm khởi đầu, truy cập nó qua một máy chủ MCP cơ sở dữ liệu đồ thị để khám phá lược đồ có sẵn. Trong minh họa này, chúng ta sẽ sử dụng Amazon Neptune làm cơ sở dữ liệu đồ thị ngữ nghĩa và giải thích hành vi của tác nhân từng bước:
1. Tác nhân bắt đầu bằng cách chạy khám phá lược đồ đối với metadata ngữ nghĩa:
get_graph_schema {}
Điều này tiết lộ một mô hình dữ liệu chăm sóc sức khỏe phong phú với các loại node khác nhau, bao gồm Doctor, Prescription, Medication, Dosage, Patient và Healthcare_Provider, liên kết với nhau bởi nhiều loại mối quan hệ.
Lược đồ phơi bày các mẫu mối quan hệ chính sẽ hướng dẫn việc tìm kiếm. Ví dụ: - Doctor → PRESCRIBED_BY → Prescription - Prescription → CONTAINS → Medication - Medication → HAS_DOSAGE → Dosage
Việc trinh sát ban đầu này là quan trọng—nếu không hiểu cấu trúc đồ thị, tác nhân sẽ tìm kiếm mù quáng qua hàng triệu node tiềm năng. Lược đồ cung cấp lớp tin cậy đầu tiên: hiểu dữ liệu nào tồn tại và cách nó được tổ chức.
2. Tiếp theo, tác nhân kiểm tra cách các thuốc kết nối với các thực thể khác. Lưu ý rằng các mô hình frontier hiện đại có thể tạo mã như sau với độ chính xác cao:
g.V().hasLabel('Medication').limit(1)
.bothE()
.project('label','direction','otherVertex')
.by(label())
.by(__.choose(__.inV().hasLabel('Medication'),
constant('out'),
constant('in')))
.by(__.otherV().label())
Kết quả:
[
{"label": "PRESCRIBED", "direction": "out", "otherVertex": "Patient"},
{"label": "PRESCRIBED", "direction": "out", "otherVertex": "Patient"},
{"label": "CONTAINS", "direction": "out", "otherVertex": "Prescription"}
]
Điều này tiết lộ mẫu duyệt chính xác: Các thuốc có các cạnh CONTAINS đến từ Prescriptions, không phải cạnh đi ra.
3. Với hướng mối quan hệ chính xác được xác định, tác nhân xây dựng một truy vấn tinh chỉnh duyệt ngược từ Medications đến Doctors:
g.V().hasLabel('Medication').as('medication')
.in('CONTAINS').hasLabel('Prescription').as('prescription')
.in('PRESCRIBED_BY').hasLabel('Doctor').as('doctor')
.select('doctor','medication','prescription')
.by(valueMap('name:String','prescribing_doctor:String').fold())
.by(valueMap('medication_name:String','dosage:String',
'frequency:String','s3FilePath').fold())
.by(valueMap('prescriptionDate:String','s3FilePath').fold())
Kết quả thành công, chuỗi tin cậy Doctor → Prescription → Medication được thiết lập, với mỗi node có thể truy vết đến tài liệu nguồn của nó qua s3FilePath đảm bảo xuất xứ dữ liệu.
4. Để lấy tất cả các tệp cần thiết để trả lời câu hỏi, tác nhân truy vấn tất cả các đường dẫn tệp duy nhất:
g.V().or(hasLabel('Medication'),
hasLabel('Prescription'),
hasLabel('Doctor'))
.values('s3FilePath')
.dedup().fold()
Kết quả: Ba tệp nguồn duy nhất được xác định:
["s3://.../Doc2-Masked.docx", "s3://.../Mock data.xlsx", "s3://.../test_docs/Doc3.docx"]
Truy vấn này thiết lập phả hệ dữ liệu—tác nhân bây giờ biết chính xác tài liệu nguồn nào đã đóng góp vào đồ thị tri thức, tạo ra một dấu vết kiểm toán cho sự tuân thủ và tin cậy.
Với xuất xứ được thiết lập, tác nhân tải xuống các tệp nguồn để xác minh và làm phong phú dữ liệu đồ thị:
aws s3 cp "s3://.../Doc2-Masked.docx" ./Doc2-Masked.docx
aws s3 cp "s3://.../Mock data.xlsx" ./Mock-data.xlsx
5. Tác nhân sau đó diễn giải động các tệp và trích xuất ngữ cảnh liên quan cần thiết để đạt được đầu ra mong muốn:
TRẢ LỜI: Chứa 100 hồ sơ bệnh nhân với các thuốc được kê đơn bao gồm: - Ibuprofen - kê đơn cho nhiều bệnh nhân vì Tăng huyết áp và Hen suyễn - Aperin - cho Hen suyễn, Rối loạn ám ảnh cưỡng chế, Lo lắng - Amoxicillin - cho Tăng huyết áp, Hen suyễn, Lo lắng - Atorvastin - cho PTSD, Rối loạn co giật, Tăng huyết áp, Rối loạn ám ảnh cưỡng chế - Insulin - cho Hen suyễn, Lo lắng, PTSD, Rối loạn co giật - Diazepam - cho PTSD, Rối loạn ám ảnh cưỡng chế, Rối loạn co giật, Lo lắng - Pandac - cho Tăng huyết áp, PTSD, Rối loạn ám ảnh cưỡng chế, Hen suyễn, Lo lắng - Warfarin - cho Hen suyễn, Rối loạn ám ảnh cưỡng chế, Lo lắng, PTSD, Rối loạn co giật
Tóm tắt Thuốc được Kê đơn bởi Bác sĩ:
Bác sĩ Moey đã kê đơn: - Thuốc: Ibuprofen (200mg) - Liều lượng: 3 lần mỗi ngày - Hướng dẫn: Tránh dùng khi bụng đói - Liên hệ: 77 123-456-789
Tệp Excel cho thấy 100 bệnh nhân với nhiều loại thuốc được kê đơn, nhưng tên bác sĩ cụ thể và hướng dẫn chi tiết cho từng loại thuốc chỉ được tìm thấy trong đồ thị cho đơn thuốc Ibuprofen của Bác sĩ Moey.
Lưu ý rằng con số 100 bệnh nhân được đạt đến trực tiếp bằng cách sử dụng metadata trong đồ thị, trong đó mỗi bệnh nhân là một node, và không yêu cầu xử lý tệp thực sự.
Báo cáo của tác nhân rằng Bác sĩ Moey đã kê đơn Ibuprofen với các hướng dẫn cụ thể, tuy nhiên, không chỉ được trích xuất từ đồ thị. Thông tin này được: - Khám phá qua duyệt mối quan hệ có hệ thống - Liên kết với tệp nguồn Doc2-Masked.docx - Tham chiếu chéo với hồ sơ bệnh nhân trong Mock data.xlsx - Xác minh qua nhiều cách tiếp cận truy vấn
Sự thông minh trong cách tiếp cận (The intelligence in the approach)
Điều làm cho việc truy xuất này trở nên thông minh là phương pháp luận có hệ thống của tác nhân:
- Lập kế hoạch chiến lược: Thực hiện khám phá lược đồ trước để giảm thiểu các truy vấn không cần thiết.
- Thích nghi động: Khi các truy vấn thất bại, chẩn đoán nguyên nhân bằng khám phá có mục tiêu.
- Suy nghĩ hai chiều: Kiểm tra hướng mối quan hệ thay vì đưa ra giả định.
- Thiết lập xuất xứ: Theo dõi mọi phần dữ liệu trở lại nguồn của nó.
- Xác minh toàn diện: Tham chiếu chéo dữ liệu đồ thị với tài liệu nguồn.
- Tối ưu hóa hiệu quả: Sử dụng loại trùng lặp để xác định các tệp duy nhất trước khi tải xuống.
Các thuộc tính càng được làm phong phú thêm vào các node và cạnh đồ thị, metadata ngữ nghĩa càng trở nên thông minh, cung cấp cho các tác nhân khả năng bỏ qua các cuộc gọi LLM phụ trợ và tải xuống tệp, đồng thời trả lời trực tiếp các truy vấn từ đồ thị.
Ví dụ 6-1 cho thấy một node bệnh nhân mẫu (một trong các thực thể trong tệp Mock data.xlsx) và các thuộc tính của nó ở định dạng JSON, đại diện cho metadata cho thực thể đó.
Ví dụ 6-1. Biểu diễn JSON của một node bệnh nhân trong cơ sở dữ liệu đồ thị
{
"n": {
"~id": "patient_P0003",
"~entityType": "node",
"~labels": ["Patient"],
"~properties": {
"medical_record_number:String": "MRN-[ẨN]",
"treatment_start_date:String": "2025-03-07",
"s3FilePath": "s3://[ẨN]/Mock data.xlsx",
"national_id:String": "[ẨN]600",
"phone_number:String": "001-373-489-[ẨN]",
"home_address:String": "[ẨN] Forest Suite 240, Laura, KY 92825",
"name:String": "Raj [ẨN]ali",
"date_of_birth:String": "2006-[ẨN]",
"email_address:String": "raj.[ẨN]ali@example.com"
}
}
}
Hình 6-4 là biểu diễn đồ họa về cách các node và cạnh kết nối với một tình trạng bất lợi. Hướng của mỗi mối quan hệ được chỉ ra, giúp các tác nhân hiểu rõ hơn các mối quan hệ và từ đó đưa ra các truy vấn chính xác hơn.
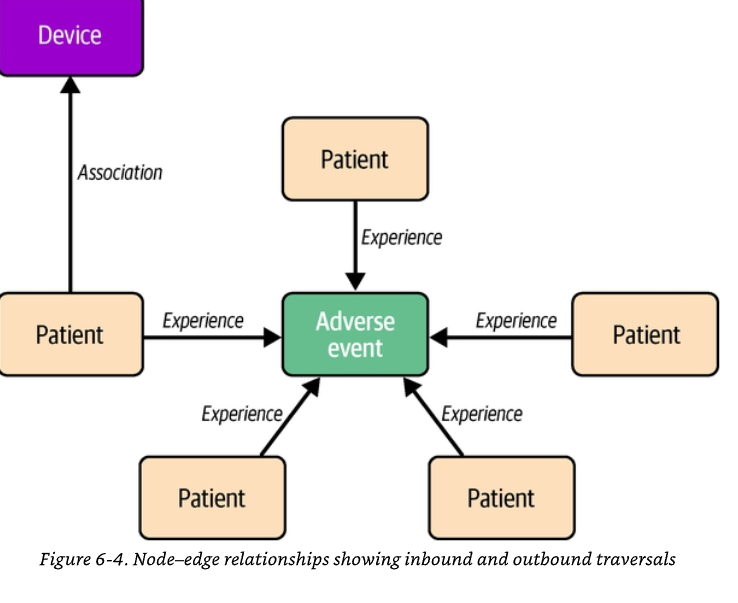
Từ Nội Dung Thô đến Trí Tuệ Ngữ Nghĩa: Xây Dựng Lớp Metadata (From Raw Content to Semantic Intelligence: Constructing the Metadata Layer)
Chúng ta đã thiết lập tại sao lớp metadata ngữ nghĩa thông minh là cần thiết và các khả năng điều hướng, truy xuất ngữ cảnh và trả lời trực tiếp mà nó mang lại chỉ có thể thực hiện được vì ai đó—hoặc thứ gì đó—đã xây dựng một cấu trúc tri thức liên kết chặt chẽ. Trong phần tiếp theo, chúng ta khám phá cách tiếp cận kiến trúc biến đổi dữ liệu phi cấu trúc thành một kết cấu tri thức mà các hệ thống AI có thể lý luận. Bạn sẽ học cách thiết kế một lớp metadata ngữ nghĩa phong phú, đa tầng từ ngoài vào trong bằng cách bắt đầu với các câu hỏi mà các tác nhân của bạn cần trả lời, và sau đó dần dần làm phong phú đồ thị đó bằng trích xuất metadata tự động, các pipeline tải và xác thực mạnh mẽ, và vòng phản hồi liên tục với mô hình phù hợp với nhu cầu kinh doanh đang phát triển.
Bắt đầu với kết quả cuối (Start with the end in mind)
Cách tiếp cận hiệu quả nhất để xây dựng một lớp metadata ngữ nghĩa là bắt đầu ngược từ các mẫu tiêu thụ. Trước khi viết một dòng code hay xử lý tệp, các tổ chức phải phát triển sự hiểu biết rõ ràng về hai điều:
- Định dạng, khối lượng, phân phối dữ liệu nguồn trên các hệ thống doanh nghiệp
- Những câu hỏi nào sẽ được đặt ra (các truy vấn, trường hợp sử dụng và các mẫu quyết định mà các tác nhân AI phải hỗ trợ)
Tư duy ưu tiên tiêu thụ này đảm bảo rằng mọi yếu tố của lược đồ metadata của bạn phục vụ một mục đích—nắm bắt các thực thể, mối quan hệ và thuộc tính trực tiếp cho phép các câu trả lời mà người dùng của bạn cần.
Thiết kế lược đồ đồ thị (Designing the graph schema)
Sau khi các trường hợp sử dụng được làm rõ, bước tiếp theo là thiết kế lược đồ cho cơ sở dữ liệu đồ thị của bạn. Lược đồ này định nghĩa:
Loại node (Node types): Các thực thể được đại diện (tài liệu, con người, sản phẩm, quy trình, khái niệm)
Loại mối quan hệ (Relationship types): Cách các thực thể kết nối (được tác giả bởi, tham chiếu, thuộc về, bắt nguồn từ)
Thuộc tính (Properties): Các thuộc tính được lưu trữ trên các node và cạnh (ngày tháng, phân loại, điểm tin cậy, phả hệ nguồn)
Đón nhận sự lặp lại thay vì hoàn hảo (Embracing iteration over perfection)
Không có lược đồ phổ quát nào phù hợp cho tất cả các trường hợp sử dụng—và đó là một tính năng, không phải là hạn chế. Các cơ sở dữ liệu đồ thị cung cấp tính linh hoạt vốn có mà các cấu trúc quan hệ không thể sánh kịp. Các đặc điểm chính bao gồm:
Tính linh hoạt của lược đồ (Schema flexibility): Các node và mối quan hệ có thể phát triển mà không phá vỡ các cấu trúc hiện có.
Làm phong phú thêm dần (Additive enrichment): Các thuộc tính mới có thể được gắn vào các node hiện có khi sự hiểu biết sâu hơn.
Mở rộng trường hợp sử dụng (Use case expansion): Các loại node và mối quan hệ bổ sung có thể được giới thiệu khi các trường hợp sử dụng mới xuất hiện.
Điều này có nghĩa là thiết kế lược đồ không bao giờ là một công việc làm một lần. Các triển khai thành công nhất coi lớp metadata là một tài sản sống, được tinh chỉnh lặp đi lặp lại khi tổ chức tìm hiểu thêm về dữ liệu, người dùng và ứng dụng AI của mình. Mỗi lần lặp cải thiện độ chính xác, mở rộng phạm vi và nâng cao khả năng sử dụng.
LƯU Ý
Hãy cưỡng lại sự cám dỗ cố gắng thiết kế lược đồ "hoàn hảo" ngay từ đầu. Bắt đầu với một lược đồ tập trung giải quyết các trường hợp sử dụng ưu tiên cao nhất của bạn, và sau đó phát triển có chủ đích khi các yêu cầu xuất hiện.
Trích xuất và tạo metadata (Extracting and generating metadata)
Sau khi lược đồ được định nghĩa, thách thức tiếp theo là điền vào nó với dữ liệu được trích xuất từ các tệp nguồn. Đây là nơi tự động hóa thông minh trở nên thiết yếu. Một cách tiếp cận thực tế liên quan đến việc xử lý từng tệp riêng lẻ để trích xuất các thực thể, mối quan hệ và thuộc tính cần thiết bởi lược đồ của bạn. Quy trình làm việc thường theo mẫu được hiển thị trong Hình 6-5.
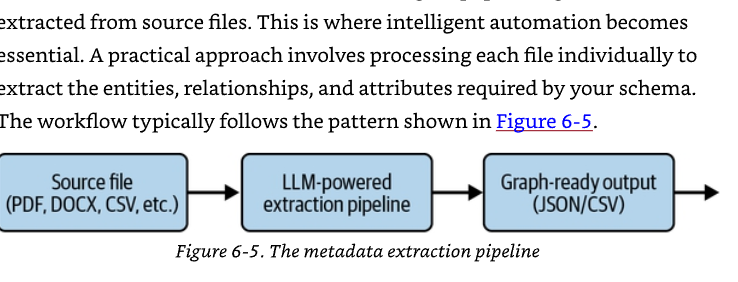
Tận dụng kỹ thuật prompt (Leveraging prompt engineering)
Như được mô tả trong Hình 6-5, các pipeline trích xuất hiện đại tận dụng các mô hình ngôn ngữ lớn được hướng dẫn bởi các prompt được thiết kế cẩn thận để tạo ra metadata mong muốn. Mô hình sẽ:
- Xác định các thực thể được đặt tên liên quan đến lĩnh vực của bạn
- Phân loại tài liệu theo các phân loại học kinh doanh
- Trích xuất các mối quan hệ giữa các khái niệm, con người và quy trình
- Tạo các thẻ ngữ nghĩa và tóm tắt
- Xuất dữ liệu có cấu trúc tuân theo lược đồ đồ thị của bạn
Quy trình trích xuất này có thể được chạy tại thời điểm ingestion hoặc được áp dụng hồi tố vào các kho tệp hiện có. Đầu ra sau đó có thể được nhập trực tiếp vào cơ sở dữ liệu đồ thị của bạn bằng cách sử dụng các công cụ tải gốc.
Khi xử lý các tệp lớn vượt quá giới hạn token, Bảng 6-2 phác thảo các vấn đề phổ biến và giải pháp của chúng:
Bảng 6-2. Các vấn đề và giải pháp khi xử lý tệp lớn
| Vấn đề | Giải pháp |
|---|---|
| Tệp vượt quá giới hạn token | Tách thành các phần logic (chương, trang, phần) |
| Mất ngữ cảnh do tách | Coi mỗi đoạn như một đơn vị độc lập với liên kết tệp cha |
| Tính liên tục mối quan hệ | Duy trì các kết nối rõ ràng giữa các đoạn và tài liệu nguồn |
Mỗi đoạn được xử lý độc lập trong quá trình trích xuất và sau đó được kết nối lại trong đồ thị thông qua các mối quan hệ bảo tồn tính toàn vẹn tài liệu và ngữ cảnh điều hướng.
Tải và kích hoạt lớp metadata (Loading and activating the metadata layer)
Bước cuối cùng biến đổi metadata được trích xuất thành một đồ thị tri thức hoạt động. Điều này bao gồm:
- Xác thực (Validation): Đảm bảo dữ liệu được trích xuất tuân theo các ràng buộc lược đồ và ngưỡng chất lượng.
- Nhập (Ingestion): Tải các node, mối quan hệ và thuộc tính vào cơ sở dữ liệu đồ thị.
- Lập chỉ mục (Indexing): Cấu hình các chỉ mục để duyệt hiệu quả và hiệu năng truy vấn.
- Kích hoạt (Activation): Kết nối lớp metadata với các tác nhân AI và khối lượng công việc ứng dụng.
Sau khi được tải, lớp metadata ngữ nghĩa thông minh, được hỗ trợ bởi đồ thị tri thức, hướng dẫn các hệ thống AI đến thông tin chính xác mà chúng cần.
Vòng đời lặp đi lặp lại (The iterative lifecycle)
Điều đáng nhấn mạnh là quá trình này là chu kỳ, không phải tuyến tính, như được phác thảo trong Hình 6-6.
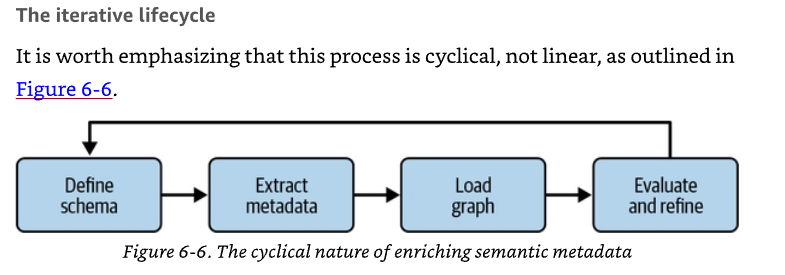
Khi các ứng dụng AI tận dụng lớp metadata, các vòng phản hồi tiết lộ:
- Các thực thể hoặc mối quan hệ còn thiếu
- Sự không nhất quán trong phân loại
- Các mẫu câu hỏi mới yêu cầu sự tiến hóa của lược đồ
- Cơ hội làm phong phú sâu hơn
Mỗi chu kỳ củng cố nền tảng, dần dần cải thiện độ chính xác, phạm vi bao phủ và sự tin tưởng của người dùng trong ứng dụng AI. Tuy nhiên, độ chính xác một mình không đảm bảo thành công. Cột mốc cuối cùng trên hành trình đến sẵn sàng sản xuất của bạn là đảm bảo các ứng dụng agentic của bạn được chuẩn bị về mặt hoạt động để thực hiện ở quy mô lớn.
Các Khả Năng Chính cho Sẵn Sàng Sản Xuất của Nền Tảng AI Tác Nhân (Key Capabilities for Production Readiness for Agentic AI Platforms)
Đạt được sẵn sàng sản xuất cho các ứng dụng AI tác nhân đòi hỏi đánh giá có chủ ý về một số khả năng chính, mỗi khả năng đóng một vai trò riêng biệt trong việc đảm bảo hệ thống của bạn hoạt động đáng tin cậy, an toàn và hiệu quả ở quy mô lớn. Khung dưới đây phác thảo bảy lĩnh vực quan trọng cần đánh giá khi chuẩn bị ứng dụng của bạn cho triển khai sản xuất.
Điều quan trọng cần nhận ra là không phải mọi ứng dụng đều đòi hỏi mọi khả năng. Trường hợp sử dụng cụ thể, yêu cầu tổ chức và mức độ chấp nhận rủi ro của bạn sẽ xác định lĩnh vực nào xứng đáng đầu tư sâu nhất. Mục tiêu không phải là triển khai tất cả mọi thứ mà là đưa ra các quyết định sáng suốt về những gì ứng dụng của bạn thực sự cần để thành công trong sản xuất:
Runtime lõi và triển khai (Core runtime and deployment)
Nền tảng của bất kỳ hệ thống tác nhân cấp sản xuất nào bắt đầu với cơ sở hạ tầng tính toán mạnh mẽ. Điều này bao gồm các tùy chọn runtime serverless cho khả năng mở rộng đàn hồi, hỗ trợ cho các khối lượng công việc dài hạn vượt quá thời gian chờ yêu cầu thông thường, cô lập phiên để đảm bảo hoạt động multitenant an toàn và tính linh hoạt triển khai trải dài qua môi trường cloud native và tự lưu trữ.
Khả năng tương tác framework và giao thức (Framework and protocol interoperability)
Khi hệ sinh thái tác nhân trưởng thành, khả năng tương tác đã trở nên thiết yếu. Lĩnh vực khả năng này bao gồm hỗ trợ cho nhiều framework tác nhân (Strands, LangGraph, LlamaIndex, Google ADK, OpenAI Agent SDK, v.v.), tuân thủ các tiêu chuẩn giao thức đang nổi lên như MCP để tích hợp công cụ và hỗ trợ cho các mẫu giao tiếp agent-to-agent (A2A). Cùng nhau, các tính năng này cho phép triển khai không phụ thuộc framework và tương lai hóa kiến trúc của bạn trước những thay đổi hệ sinh thái nhanh chóng.
Tích hợp và thực thi công cụ (Tool integration and execution)
Các tác nhân lấy phần lớn giá trị của mình từ khả năng tương tác với các hệ thống bên ngoài. Lĩnh vực khả năng này bao gồm các biến đổi cổng API, các connector dựng sẵn cho các dịch vụ phổ biến, tự động hóa trình duyệt cho các tác vụ dựa trên web, môi trường thực thi mã sandboxed và các pipeline xử lý tệp hoặc tài liệu.
Quản lý bộ nhớ và tri thức (Memory and knowledge management)
Quản lý ngữ cảnh hiệu quả phân biệt một tác nhân có khả năng với một tác nhân thực sự thông minh. Lĩnh vực này đề cập đến cách ứng dụng của bạn xử lý bộ nhớ ngắn hạn trong một phiên, bộ nhớ dài hạn qua các phiên, tìm kiếm ngữ nghĩa để truy xuất ngữ cảnh, truy xuất tri thức qua RAG và các kho tùy chỉnh cho phép học trong ngữ cảnh động từ các prompt của người dùng.
Bảo mật và tuân thủ (Security and compliance)
Các triển khai doanh nghiệp đòi hỏi các kiểm soát bảo mật nghiêm ngặt. Lĩnh vực khả năng này bao gồm quản lý danh tính và token, hỗ trợ luồng OAuth 2.0 để ủy quyền an toàn, tích hợp với các nhà cung cấp danh tính doanh nghiệp, các tùy chọn triển khai VPC và mạng riêng và các guardrail có thể cấu hình để thực thi ranh giới an toàn và tuân thủ chính sách.
Khả năng quan sát và đảm bảo chất lượng (Observability and quality assurance)
Bạn không thể vận hành những gì bạn không thể quan sát. Lĩnh vực khả năng này đảm bảo khả năng hiển thị toàn diện vào hành vi tác nhân thông qua khả năng quan sát dựa trên OpenTelemetry, bảng điều khiển thời gian thực, các công cụ gỡ lỗi quy trình làm việc trực quan, khung đánh giá và kiểm thử để đảm bảo chất lượng liên tục và các registry tác nhân với phiên bản để quản lý triển khai theo thời gian.
Khả năng đa tác nhân và tương tác (Multi-agent and interaction capabilities)
Khi các kiến trúc tác nhân ngày càng phức tạp hơn, điều phối qua nhiều tác nhân chuyên biệt trở nên quan trọng. Lĩnh vực khả năng này bao gồm các mẫu phối hợp đa tác nhân, các quy trình làm việc có người trong vòng lặp (human-in-the-loop) cho phép giám sát và can thiệp, và các khả năng phản hồi streaming cho các tương tác người dùng thời gian thực.
Lựa Chọn Nền Tảng Tác Nhân AI Hàng Đầu (Leading AI Agent Platform Choices)
Bức tranh nền tảng tác nhân AI đã trưởng thành nhanh chóng, với một số nhà cung cấp nổi lên là những người đi đầu cung cấp một số hoặc tất cả các khả năng cốt lõi mà chúng ta vừa mô tả. Phần này cung cấp một tổng quan so sánh về các tùy chọn hàng đầu hiện có ngày nay trên tất cả các lĩnh vực khả năng này, dựa trên kinh nghiệm của chúng tôi làm việc với hàng chục doanh nghiệp có quy mô khác nhau—bao gồm nhiều công ty Fortune 500—trong năm 2024–2025. Chúng ta xem xét năm nền tảng trong so sánh:
- Amazon Bedrock AgentCore
- Google Vertex AI
- Azure AI Foundry
- LangSmith Deployment (trước đây là LangGraph Platform)
- CrewAI Enterprise
Tuy nhiên, một lời cảnh báo: đánh giá được trình bày ở đây phản ánh một ảnh chụp tại thời điểm được ghi lại khi viết cuốn sách này. Hệ sinh thái tác nhân AI đang phát triển với tốc độ phi thường—các tính năng, mô hình định giá và khả năng mới được giới thiệu thường xuyên. Những gì đúng hôm nay có thể thay đổi vào ngày mai. Chúng tôi khuyến khích bạn xác nhận các so sánh này với các dịch vụ mới nhất trước khi đưa ra các quyết định kiến trúc hoặc nhà cung cấp cho môi trường sản xuất của bạn.
Chiến Lược Runtime Lõi và Triển Khai (Core Runtime and Deployment Strategy)
Để chọn chiến lược runtime lõi và triển khai phù hợp cho các ứng dụng agentic của bạn, việc so sánh cách các nền tảng hàng đầu xử lý thực thi, cô lập và tích hợp framework sẽ rất hữu ích. Bảng 6-3 tóm tắt các đặc điểm chính.
Bảng 6-3. Đặc điểm runtime và triển khai của các nền tảng AI tác nhân hàng đầu
| Nền tảng | Mô hình triển khai | Runtime tối đa | Cô lập phiên | Hỗ trợ framework |
|---|---|---|---|---|
| Amazon Bedrock AgentCore | Serverless | Tối đa 8 giờ (dài nhất) | Cô lập microVM hoàn toàn | Bất kỳ framework nào |
| Google Vertex AI | Serverless | Không ràng buộc rõ ràng (theo tài nguyên) | Managed runtime + thực thi sandboxed (VPC-SC tùy chọn) | ADK, LangGraph, LangChain (đầy đủ); CrewAI, các framework khác qua template tùy chỉnh |
| Azure AI Foundry | Managed service | Tùy thuộc vào dịch vụ cơ sở | Tùy thuộc vào hosting | Framework-agnostic (công cụ Azure-native) |
| LangSmith Deployment | Cloud/hybrid/self-hosted | Tùy thuộc vào triển khai | Tùy thuộc vào hosting | LangGraph-native; có thể mở rộng cho các framework khác |
| CrewAI Enterprise | Cloud/self-hosted/on-premises | Không ràng buộc rõ ràng; hỗ trợ long-running | Logical/agent-level | Chỉ CrewAI |
Khả năng runtime mở rộng tám giờ của AgentCore đặc biệt đáng chú ý cho các tác vụ tác nhân phức tạp, đa bước đòi hỏi xử lý liên tục trong nhiều giờ. Các trường hợp sử dụng ví dụ bao gồm mua sắm, quản lý đơn hàng và logistics, tạo báo giá và quản lý hàng tồn kho, nơi hai hoặc nhiều tác vụ phụ thuộc lẫn nhau có thể được xử lý cách nhau nhiều giờ.
Tích Hợp Framework, Công Cụ và Hỗ Trợ Giao Thức (Framework, Tool Integration, and Protocol Support)
Để hiểu cách mỗi nền tảng kết nối vào hệ sinh thái công cụ mở đang nổi lên, việc nhìn xa hơn runtime lõi và xem xét các khả năng giao thức, cổng và thực thi sẽ hữu ích. Bảng 6-4 tóm tắt tích hợp cấp framework.
Bảng 6-4. So sánh tích hợp framework mở
| Nền tảng | MCP | A2A | Cổng API | Thực thi code |
|---|---|---|---|---|
| Amazon Bedrock AgentCore | Có, gốc | Có | Chuyển đổi Lambda/API | Môi trường sandbox |
| Google Vertex AI | Có, qua ADK | Có | 100+ connectors, Apigee | Môi trường sandbox |
| Azure AI Foundry | Qua tools | Qua tools | Logic Apps, Azure Functions | Code interpreter |
| LangSmith Deployment | Qua tools | Không | Tích hợp tùy chỉnh | Qua callbacks |
| CrewAI Enterprise | Có | Không | Integration hub | Qua agents |
Khả Năng Quản Lý Bộ Nhớ và Tri Thức (Memory and Knowledge Management Capabilities)
Khả năng quản lý bộ nhớ khác nhau đáng kể giữa các nền tảng:
-
Amazon Bedrock AgentCore cung cấp bộ nhớ hai tầng—bộ nhớ ngắn hạn (STM) cho ngữ cảnh cuộc trò chuyện tức thì và bộ nhớ dài hạn (LTM) để duy trì qua các phiên—với độ chính xác hàng đầu ngành mà không cần quản lý cơ sở hạ tầng.
-
Google Vertex AI Agent Engine bao gồm Sessions để lưu trữ các tương tác người dùng-tác nhân riêng lẻ và Memory Bank để cá nhân hóa các tương tác tác nhân. Example Store (đang trong preview tại thời điểm viết) cho phép truy xuất động các ví dụ few-shot để cải thiện hiệu năng.
-
Azure AI Foundry cung cấp quản lý trạng thái cuộc trò chuyện tích hợp xử lý tự động việc quản lý thread và truy xuất lịch sử cuộc trò chuyện, loại bỏ nhu cầu xây dựng các hệ thống quản lý thread tùy chỉnh.
-
LangSmith Deployment cung cấp checkpointing và một bộ nhớ store với hỗ trợ TTL cho cả các thread cuộc trò chuyện và bộ nhớ dài hạn, với dọn dẹp dựa trên hết hạn.
-
CrewAI Enterprise bao gồm các khả năng bộ nhớ bền vững và buffer cuộc trò chuyện với các tính năng tự phục hồi để quản lý bộ nhớ trong các quy trình làm việc phức tạp.
Tính Năng Bảo Mật và Tuân Thủ (Security and Compliance Features)
Mặc dù tất cả các nhà cung cấp lớn đều cung cấp bảo mật cấp doanh nghiệp, đáng chú ý rằng tích hợp của AgentCore với các nhà cung cấp danh tính hiện có (loại bỏ di chuyển người dùng) và token vault an toàn để giảm thiểu sự mệt mỏi đồng ý cung cấp những lợi thế riêng biệt. Phát hiện mối đe dọa của Google Vertex AI Agent Engine qua Security Command Center thêm khả năng điều tra mối đe dọa chủ động. Bảng 6-5 so sánh các tính năng xác thực, danh tính và tuân thủ.
Bảng 6-5. Tính năng bảo mật và tuân thủ của các nền tảng AI tác nhân hàng đầu
| Nền tảng | Xác thực | Tính năng danh tính | Tuân thủ |
|---|---|---|---|
| Amazon Bedrock AgentCore | IAM, OAuth 2.0, Cognito | Token vault, ủy quyền quyền | VPC, PrivateLink |
| Google Vertex AI | IAM, VPC-SC, CMEK | Agent identity (preview) | HIPAA, data residency |
| Azure AI Foundry | Entra ID, RBAC, OBO | Keyless setup | Enterprise conditional access |
| LangSmith Deployment | Custom OAuth | API authentication | Tùy thuộc vào triển khai |
| CrewAI Enterprise | Enterprise SSO | IP protection | HIPAA, SOC 2 |
Hỗ Trợ Khả Năng Quan Sát và Đảm Bảo Chất Lượng (Observability and Quality Assurance Support)
Tất cả các nền tảng đều hỗ trợ OpenTelemetry để quan sát được tiêu chuẩn hóa:
-
Amazon Bedrock AgentCore cung cấp các bảng điều khiển toàn diện được hỗ trợ bởi Amazon CloudWatch với khả năng hiển thị thời gian thực vào các quy trình làm việc tác nhân, theo dõi X-Ray tự động và cấu hình Transaction Search.
-
Google Vertex AI tích hợp với Cloud Trace, Cloud Monitoring và Cloud Logging, với theo dõi đầy đủ hỗ trợ các tiêu chuẩn OpenTelemetry.
-
Azure AI Foundry cung cấp theo dõi dựa trên OpenTelemetry với tích hợp Application Insights, cung cấp khả năng hiển thị cấp cuộc trò chuyện và telemetry cho mọi quyết định tác nhân.
-
LangSmith Deployment tích hợp gốc với LangSmith, cho phép gỡ lỗi trực quan với khả năng hiển thị chi tiết vào các quỹ đạo tác nhân, logic phân nhánh và các luồng thử lại.
-
CrewAI không bao gồm xuất OpenTelemetry gốc trong framework cốt lõi của nó, yêu cầu các công cụ đo lường của bên thứ ba. Tuy nhiên, nền tảng CrewAI Enterprise cung cấp các bảng điều khiển, theo dõi và giám sát tích hợp toàn diện. Hệ sinh thái tích hợp với 10+ công cụ quan sát làm cho nó linh hoạt cao cho các triển khai doanh nghiệp.
Tóm Tắt (Summary)
Hành trình từ nguyên mẫu AI đến hệ thống sẵn sàng sản xuất đòi hỏi nhiều hơn là thành thạo kỹ thuật—nó đòi hỏi một sự thay đổi căn bản trong cách chúng ta tiếp cận dữ liệu, ngữ cảnh, lý luận và sự xuất sắc hoạt động.
Chương này đã thiết lập rằng dữ liệu là mạch máu của ứng dụng AI của bạn—nhưng chất lượng dữ liệu không phải là tuyệt đối. Nó phụ thuộc vào ngữ cảnh, được định hình bởi các mục tiêu kinh doanh và được phục vụ tốt nhất thông qua một thiết kế mô-đun bảo tồn tính linh hoạt trong khi tối ưu hóa hiệu năng. Chúng ta đã giải quyết quản lý ngữ cảnh ở quy mô lớn thông qua phân đoạn có hệ thống, suy luận song song và các chiến lược tổ chức thông minh ngăn các đầu vào lớn làm giảm chất lượng đầu ra.
Chúng ta đã khám phá lý luận tự động như một khả năng mạnh mẽ nhưng cần hiệu chỉnh cẩn thận. Các mẫu chain-of-thought, tree-of-thought và graph-of-thought cung cấp các cách tiếp cận có cấu trúc cho các vấn đề phức tạp, nhưng như các ví dụ đã chứng minh, các token lý luận đưa ra các đánh đổi thực sự về độ trễ và chi phí đòi hỏi tinh chỉnh cẩn thận.
Lớp metadata ngữ nghĩa thông minh nổi lên như một mẫu chuyển đổi cho các doanh nghiệp đang vật lộn với petabyte dữ liệu phi cấu trúc. Được xây dựng trên công nghệ đồ thị tri thức, cách tiếp cận này cho phép các tác nhân AI khám phá, diễn giải và lý luận trên nội dung ở quy mô lớn—mang lại không chỉ độ chính xác mà còn khả năng giải thích và sự tin tưởng được xây dựng trên các tài liệu nguồn có thể xác minh.
Cuối cùng, chúng ta đã cung cấp một khung toàn diện để đánh giá sẵn sàng hoạt động trên bảy lĩnh vực khả năng quan trọng—từ runtime lõi và bảo mật đến khả năng quan sát và điều phối đa tác nhân—cùng với phân tích so sánh các nền tảng hàng đầu ngày nay để thông báo cho các quyết định kiến trúc của bạn.
Sẵn sàng sản xuất không phải là một đích đến mà là một thực hành liên tục. Mỗi lần lặp củng cố nền tảng của bạn, cải thiện độ chính xác và sâu sắc thêm sự tin tưởng của người dùng. Các kỹ thuật được trình bày ở đây được rút ra từ các triển khai thực tế và cung cấp các cách tiếp cận thực tế đã được chứng minh để thu hẹp khoảng cách giữa tiềm năng AI và thực tế sản xuất.
Dữ liệu của bạn là một tài sản chiến lược xứng đáng với kiến trúc có chủ ý. Làm đúng điều này, và mọi thứ khác sẽ theo sau.
Bản thiết kế đã ở trong tay bạn. Bây giờ là lúc xây dựng.
Tạo tự động từ thư mục
chapters/. Dịch thêm chương rồi chạy lại
python build_website.py để cập nhật.